Transact-SQL
A Microsoft extension to the ANSI SQL language that includes procedural programming, local variables, and various support functions.
4,552 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ESW%3C/text%3E%3C/svg%3E)
what's the best way to spilt the pipe delimited columns in SQL 2017.
Input:
declare @table table (sno int,sname varchar(200),sname1 varchar(200))
Insert into @Table(sno,sname,sname1)
Values (1,'Mark|James','Dallas|Houston')
Excepted Output:
1 Mark Dallas
1 James Houston
Thank you.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EYK%3C/text%3E%3C/svg%3E)
Hi @SQL Whisper ,
Your post got quite a traction.
Did you have a chance to try at least a couple of proposed solutions you received?

Hi @SQL Whisper ,
Could you please validate all the answers so far and provide any update?
Please remember to accept the answers if they helped. Your action would be helpful to other users who encounter the same issue and read this thread.
Thank you for understanding!
Best regards
Melissa

Good day,
As of SQL Server 2016 you have a built in function named STRING_SPLIT
With that being said, this question implies optionality of a very bad design of your relational database and you should really re-think about your database design or/and the type of the database which you chose to use
Thanks Pituach for the response. Unfortunately, we receive this data in this format from a vendor. Our hands are tied in regards to format file.
String_split does not produce the excepted results.
declare @table table (sno int,sname varchar(200),sname1 varchar(200))
Insert into @Table(sno,sname,sname1)
Values (1,'Mark|James','Dallas|Houston')
Select sno,sname.value as sname,sname1.value as sname1
from @Table
cross apply string_split(sname,'|') as sname
cross apply string_split(sname1,'|') as sname1

The limitation of STRING_SPLIT is that that order is not guarantee... We might need to use JSON or XML for the split here (in this case SQLCLR function is probably your best option)
Let's clarify the situation better...
(1) Is the number of names in each value always 2 or can it be more?
(2) Is the number of names always the same in the sname and sname1 colums?
(3) Is the total number of names in the same value guarantee to be less than 4?
can all these might exists for example:
Values (1,'A|B|C','A|B|C')
Values (1,'A|null|C','A|B|C')
Values (1,'A|B|C','A|B')
Values (1,'A|B|C','A|B|')
Values (1,'A|B','A|B|C')
Values (1,'A|B|C|D|E','A|B|C|D|E')
Thanks pituach.
The number pipe delimited values in sname and sname1 will be same. There can be duplicated values in the pipe delimited string.
Values (1,'A|B|C','A|B|C') -- possible
Values (1,'A|null|C','A|B|C') -- not possible - no nulls are excepted
Values (1,'A|B|C','A|B') --not possible - number delimited values will be same in sname and sname1
Values (1,'A|B|C','A|B|') -- not possible
Values (1,'A|B','A|B|C') -- not possible
Values (1,'A|B|C|D|E','A|B|C|D|E') - possible
Hi @SQL Whisper ,
As @Ronen Ariely already pointed out, it is better to use XML (or Json) for such cases.
Please try the following solution that is based on XML and XQuery.
It is a two step process:
The CTE emits XML structured as follows:
<root>
<r name="Mark" city="Dallas" />
<r name="James" city="Houston" />
</root>
SQL
-- DDL and sample data population, start
DECLARE @table table (sno INT, sname VARCHAR(200), sname1 VARCHAR(200))
INSERT INTO @Table (sno,sname,sname1) VALUES
(1,'Mark|James','Dallas|Houston'),
(2,'Mary|Katy|Paula','Miami|Fort Lauderdale|Orlando'); -- # of tokens could be dynamic
-- DDL and sample data population, end
DECLARE @separator CHAR(1) = '|';
;WITH rs AS
(
SELECT sno
, TRY_CAST('<root><r>' +
REPLACE(sname + @separator + sname1, @separator, '</r><r>') +
'</r></root>' AS XML).query('<root>
{
let $counter := count(/root/r) div 2
for $x in /root/r[position() le $counter]
let $pos := count(/root/r[. << $x[1]]) + 1
return <r name="{$x/text()}" city="{/root/r[$pos + $counter]/text()}"></r>
}
</root>') AS xmldata
FROM @table
)
SELECT rs.sno
, n.value('@name','VARCHAR(30)') AS [name]
, n.value('@city','VARCHAR(30)') AS [city]
FROM rs
CROSS APPLY xmldata.nodes('/root/r') AS t(n)
ORDER BY rs.sno;
Output
+-----+-------+-----------------+
| sno | name | city |
+-----+-------+-----------------+
| 1 | Mark | Dallas |
| 1 | James | Houston |
| 2 | Mary | Miami |
| 2 | Katy | Fort Lauderdale |
| 2 | Paula | Orlando |
+-----+-------+-----------------+
Hi :-)
According to your answer to my clarification question the following should solve your need (please confirm)
----------
DROP TABLE IF EXISTS T1
GO
CREATE table T1 (sno int,sname varchar(200),sname1 varchar(200))
GO
Insert into T1(sno,sname,sname1)
Values
(1,'1A','1a'), (1,'2A|2B','2a|2b'),
(1,'3A|3B|3C','3a|3b|3c'), (1,'4A|4B|4C|4D','4a|4b|4c|4d')
GO
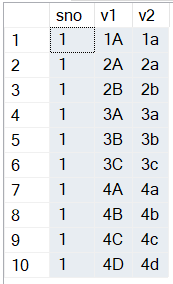
SELECT * FROM T1
GO
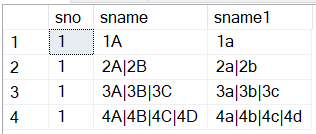
;With MyCTE0 as (
select sno, sname,sname1
,s = '["' + Replace(sname, '|', '","') + '"]'
,s1 = '["' + Replace(sname1, '|', '","') + '"]'
from T1
),
MyCTE1 as (
select sno, s, s1
, k1 = t.[key], v1 = t.[value]
from MyCTE0
CROSS APPLY OPENJSON (s, N'$') t
)
SELECT sno, v1 , v2
FROM MyCTE1
CROSS APPLY (SELECT t1.[key] k2 , t1.[value] v2 FROM OPENJSON (s1, N'$') t1 where t1.[key] = MyCTE1.k1) t
GO

Here is a solution that does not use XML or JSON (which both can result in problems if the data includes characters with a special function in these formats):
declare @Table table (sno int,sname varchar(200),sname1 varchar(200))
Insert into @Table(sno,sname,sname1)
Values (1,'Mark|James','Dallas|Houston')
SELECT t.sno, s.str + ' ' + s1.str
FROM @Table t
CROSS APPLY iter_charlist_to_tbl(t.sname, '|') AS s
CROSS APPLY iter_charlist_to_tbl(t.sname1, '|') AS s1
WHERE s.listpos = s1.listpos
You find the code for iter_charlist_to_tbl here: http://www.sommarskog.se/arrays-in-sql-2005.html#iter-list-of-strings
This solution based on loops and even so we cannot always count on the comparing of the relative execution performance I think that in first glance the image says something 9% cost for my solution vs 91% using your functions
Yes, Erland is right, there might be limitations for XML/JSON solutions which should be considered for each case (for example problematic characters which might need to be replaced first).

That is true, that is not the fast string-split function there is. There are faster ones in the article I linked to. But this is the easiest one to set up, I would suggest that you need a lot of data for the speed of the function to really matter.
And you should know better than comparing the estimated percentages in SSMS. They tell us nothing.

1234567890
Here is a solution that does not use XML or JSON (which both can result in problems if the data includes characters with a special function in these formats
Obviously, it is a legitimate concern. And of course, I am using CDATA section in the T-SQL answer on my computer. Unfortunately, this site doesn't allow their inclusion to the answers. I complained about it many times in the feedback to no avail.


Here is a solution that does not use XML or JSON (which both can result in problems if the data includes characters with a special function in these formats) […]
I think that splitting functions can also result in problems if the separator is allowed inside the values using some special rules, like representing ‘|’ as ‘\|’ and ‘\’ as ‘\’ when ‘|’ is a part of values.
Although, this is not a subject for present question.
The CDATA section helps in case of ‘a<b|c’, but some minor adjustments seem required to make it work in this rare case too: ‘a]]>b|c’.
Although, this is not a subject for present question.
You are absolutely correct in that regard. However, one will have to assume that the vendor who have specified this format never puts pipes into the data. It they would, their customers would be at loss anyhow.
But when you start to introduce methods such as XML or JSON that the vendor did not have in mind, you are taking a bigger risk.
On the other hand, if would design a format for information interchange, I would absolute go for XML or JSON from the start, exactly because they have methods to deal with meta-characters in the data. And this particular format that SQLWhisper is a victim of is really lousy, since it consists of two strings that must be in sync. It is certainly very brittle.
Yet a solution. This one is based on a performance test I did, and where I tried the solutions posted by Yitzhak, Ronen and me with a fairly large data set. I gave all ten minutes to run before I killed them. Looking at the plans, Ronen's is probably the one that would have completed first, but in how many hours, I don't know.
While I was waiting, I wrote a new solution which completed in three minutes. With a faster string splitter the time can be reduced further. But the keys is that the two strings need to split separately, so that we can join over an index.
SQLWhisper will have to accept that the names have changed. id = sno, ShipName = sname, ShipAddress = sname1
CREATE TABLE #t1 (id int NOT NULL,
pos int NOT NULL,
ShipName nvarchar(60) NOT NULL,
PRIMARY KEY (id, pos))
CREATE TABLE #t2 (id int NOT NULL,
pos int NOT NULL,
ShipAddress nvarchar(60) NOT NULL,
PRIMARY KEY (id, pos))
INSERT #t1(id, pos, ShipName)
SELECT t.id, s.listpos, s.nstr
FROM PipeData t
CROSS APPLY iter_charlist_to_tbl(t.ShipName, '|') AS s
INSERT #t2(id, pos, ShipAddress)
SELECT t.id, s.listpos, s.nstr
FROM PipeData t
CROSS APPLY iter_charlist_to_tbl(t.ShipAddress, '|') AS s
SELECT t1.id, t1.ShipName + ' ' + t2.ShipAddress as str
FROM #t1 t1
JOIN #t2 t2 ON t1.id = t2.id
AND t1.pos = t2.pos
For the curious, my test script is here: 34739-pipedatasplt.txt. The BigDB database that I load the data from is on http://www.sommarskog.se/present/BigDB.bak. Warning! This is a 3GB download, and the full database size is 20 GB. SQL 2016 or later is needed. (This is a demo database that I had uploaded already.)
The only reason your query is fast is related to the fact that you used temporary table and has nothing to do with your solution (your function).
In such table with such amount of data it is simply better to use two temporary table and then JOIN
I executed you query using your data but since my laptop is poor I in the PipeData table I only filled 10k rows using your query with top 10000
I tested your solution on these 10k rows and it took more than 5 minutes.
I tested my solution using (meaning using OPENJSON) using temporary tables
And guess what ?!?
As I expected my solution finished in 20 seconds!
Assuming I did not made a mistake in my test (and this is the expected result I had) the different is 20 seconds vs 5 minuets
I will post the query using temp table which I used in an answer since it is too long for comment