Azure Data Factory
An Azure service for ingesting, preparing, and transforming data at scale.
9,652 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.

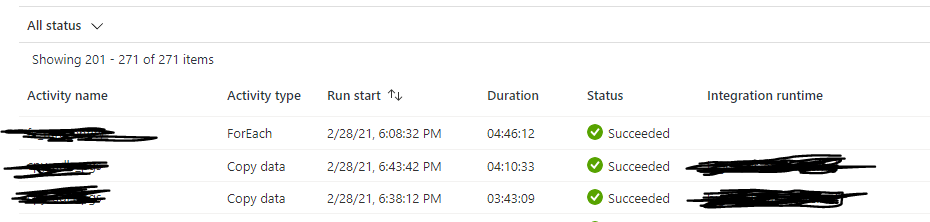
In the following scenario we have a ForEach activity running in an Azure Data Factory pipeline to copy data from source to destination. The last CopyActivity took 4:10:33 but the ForEach activity declared Succeeded 36 Minutes later: 4:46:12. The question is, why ForEach activity need this 36 Minutes extra? Is it the case that the ForEach needs also to consolidate results from subactivities before declaring success or fail?
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EKM%3C/text%3E%3C/svg%3E)
Hi @Georgian Pirvu ,
Welcome to Microsoft Q&A and thanks for your query. Could you please share the pipeline run Id for which you are seeing this behavior so that we can check with internal team on what exactly is causing this issue.
Looking forward to your response.
Thanks
sure, the run id for the pipeline is a22948ae-d3d6-4e33-9bdf-7b9c8d0a4d6e. Thank you for support.
Hi @Georgian Pirvu ,
Thanks for the details. I am reaching out to internal team to get better understanding why this has happened.
Will get back to you as soon as I have an update.
Thank you for your patience.
Hi @Georgian Pirvu ,
After having conversation with internal team, below are the findings:
ForEach activity does wait for all inner activity runs to complete. In theory, there should not be much delay on marking foreach run success after the last activity run within it succeed. However, ADF rely on partner service to execute the runs and it's possible that the partner service run into failures and could not complete foreach in time. They have build in logic to keep retry and recover but the behavior in ADF activity runs is delay. It's also possible that orchestration service fails and partner service keep retry on calling us. but usually partner service delay is the main cause here.
Are you noticing this behavior consistently or intermittently? If you notice this behavior consistently then we need to file a support ticket for deeper analysis.
Please let me know if this info helps or if you would want to proceed with Support ticket.
----------
Thank you
Please do consider to click on "Accept Answer" and "Upvote" on the post that helps you, as it can be beneficial to other community members.
Thank you for answer. This would be a consistent behavior or pattern. Losing 30-50 Min for every pipeline run, running 3 times/day would cost 90-150 Min per day.
But we will move on from Postgre copy_activity and will remove this pipeline with a Synapse solution where we will query directly the ADLS.
Hi @Georgian Pirvu ,
Thanks for your response and sharing alternate approach here. Please let us know if there is anything else that we can help with on the original query. If you have questions on other topics please feel free to open a new thread.
Thank you