Azure SQL Database
An Azure relational database service.
5,148 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EAB%3C/text%3E%3C/svg%3E)
Our webapp started throwing SqlExceptions over the weekend, which quickly escalated this morning once the bulk of our users started using the app again. I managed to track the issue down to 1 db, which was pegged at 100% CPU. My first attempt to resolve it was to scale it up from a Basic to S0, which didn't help. I then tried stopping the webapp and restoring a copy of the DB to see if a new instance of the DB would be free from these issues - it didn't help. Then in a blind panic, I kept scaling up in the hope that at some point the issue would resolve. It finally did at S3.
So thankfully my webapp is now working again, but I don't want to be paying for an S3 DB when I clearly shouldn't be at that level, so I'd like to figure out what the cause of the issue is, and how to properly resolve it so that I can scale back down.
Under Diagnose, there is this message:
Active: At 02:26 AM, Saturday, 27 February 2021 UTC, the Azure monitoring system received the following information regarding your SQL database resource tht-uks1/tht-main::
We're sorry your SQL database is experiencing transient login failures. Currently, Azure shows the impacted time period for your SQL database resource at a two-minute granularity. The actual impact is likely less than a minute – average is 2s. We're working to determine the source of the problem
I don't know if this is related or not, but figured it was worth mentioning.
Can anyone point me in the right direction for understanding what went wrong?
Thanks,
Anthony

I will share my own experience with customers. If you want to save with Azure SQL Database you have to optimize your database and its programming objects. Just last week a customer saw 30% less DTU usage on peak hours by just adding less than 10 indexes to their database. Adding missing indexes to the database is the easiest way to lower DTU consumption.
When the database reaches the DTU limit and stay there for some minutes, poor performance and connection timeouts may come along.
Optimize top worst queries in terms of performance. Identify them on the "Performance Overview" section for your Azure SQL Database (Azure portal - left vertical panel). See image below. You make a click on the chart and you get details of the queries involved.
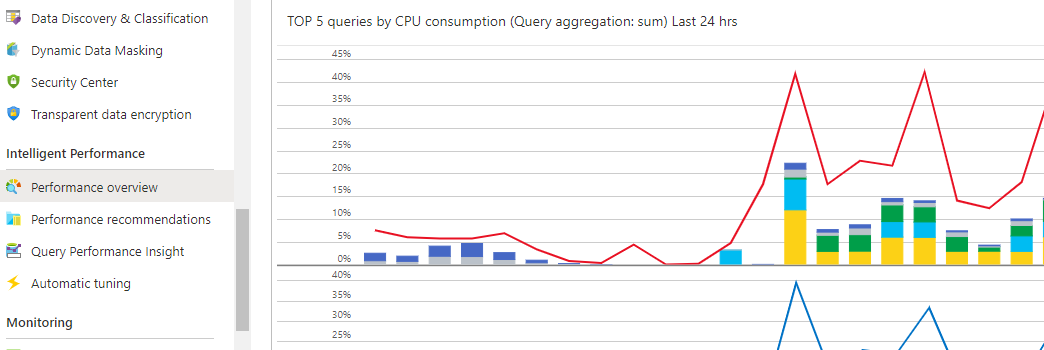
Verify also deadlocks are not occurring. Resolve possible deadlocks issues.
IO intensive workloads are more intended for premium tiers.
Thanks for your response. That's really useful information, and definitely something I'll look into, however, it doesn't help me understand why my CPU usage has suddenly increased from Basic plan level to S3 level. The amount of traffic hasn't changed, and code hasn't changed.
Index fragmentation, outdated statistics and missing indexes produce table scans, and spike IO consumption, CPU consumption and memory usage.
If you take care of that, then you will be able to scale down the database to lower tiers and save money.
Thanks, that seems to have done the trick!