Azure Synapse Analytics
An Azure analytics service that brings together data integration, enterprise data warehousing, and big data analytics. Previously known as Azure SQL Data Warehouse.
4,342 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EJH%3C/text%3E%3C/svg%3E)
Goal: Connect client apps (e.g., SSMS, Tableau, Power BI) to the Synapse workspace serverless SQL endpoint and query databases and tables created by an Apache Spark pool in the same Synapse workspace.
Setup:
What we have:
At that point one user got an error:
[Microsoft][ODBC Driver 17 for SQL Server][SQL Server]External table 'dbo' is not accessible because content of directory cannot be listed.
The table "[dbo].[billing_all_prod]" does not exist.
Looking at the document on setting up Synapse access control (https://learn.microsoft.com/en-us/azure/synapse-analytics/security/how-to-set-up-access-control),
we assigned the Storage Blob Data Reader role to the AD user. We haven't heard back yet about whether this resolved all of the access issues, but the end-users (managers for this project) are tired of being used as debuggers, and we would like to be sure everything that needs to be done is completed.
That Synapse access control document, in STEP 7:
By default, all users assigned the Synapse Administrator role are also assigned the SQL db_owner role on the serverless SQL pool, 'Built-in', and all its databases.
Access to SQL pools for other users and for the workspace MSI is controlled using SQL permissions.
When I proceed to STEP 7.1: Serverless SQL pool, Built-in and run the scripts, when trying to create users on the Spark-created databases I get an error:
Operation CREATE USER is not allowed for a replicated database.
That sort of makes sense, since the Spark pool actually created the database and the serverless SQL pool is just using a copy of some metadata. But my questions from above are:
Thanks,
Johnny
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ESS%3C/text%3E%3C/svg%3E)
Johnny,
I'm taking a look to see what the least permissions is for your scenario. The product team is very aware that the permissions in Synapse are overly complicated and is working towards solving this.
Adding Storage Blob Data Reader should resolve that error.
There are two levels of authentication required to do what you are trying to do:
CREATE LOGIN [Security Group Name] FROM EXTERNAL PROVIDER; This must be a security group in AAD, not a Microsoft 365/Distribution group Storage Blob Data Reader role takes its place as your serverless pool is reading directly from the storage account.
Thanks for the update.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EA%3C/text%3E%3C/svg%3E)
Hi! I pretty much have the exact same case, but the suggested solution does not resolve the issue.
I've tried creating SQL logins (CREATE LOGIN), which makes me login and see the databases on the server. But when I try to expand "tables", I get this:
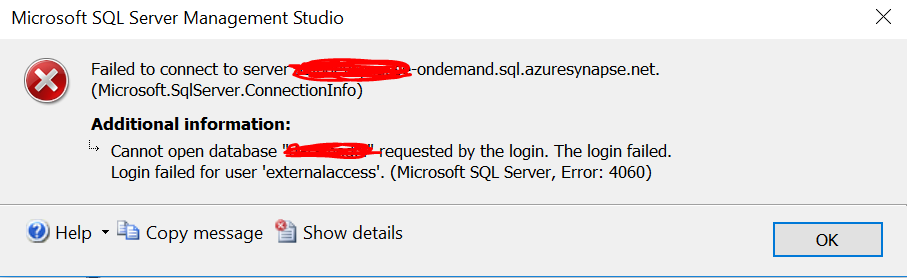
Which makes me think the SQL login works, but the data access is limited. I get the same result when I create a login for the user who are to access the data based on their email: CREATE LOGIN email@ssss .com FROM EXTERNAL PROVIDER;.
However, the user is granted Storage Blob Data Reader access on the resource group that contains the data lake/storage account, without this changing the outcome. The user is supposed to connect through Power BI, and the error looks like this:
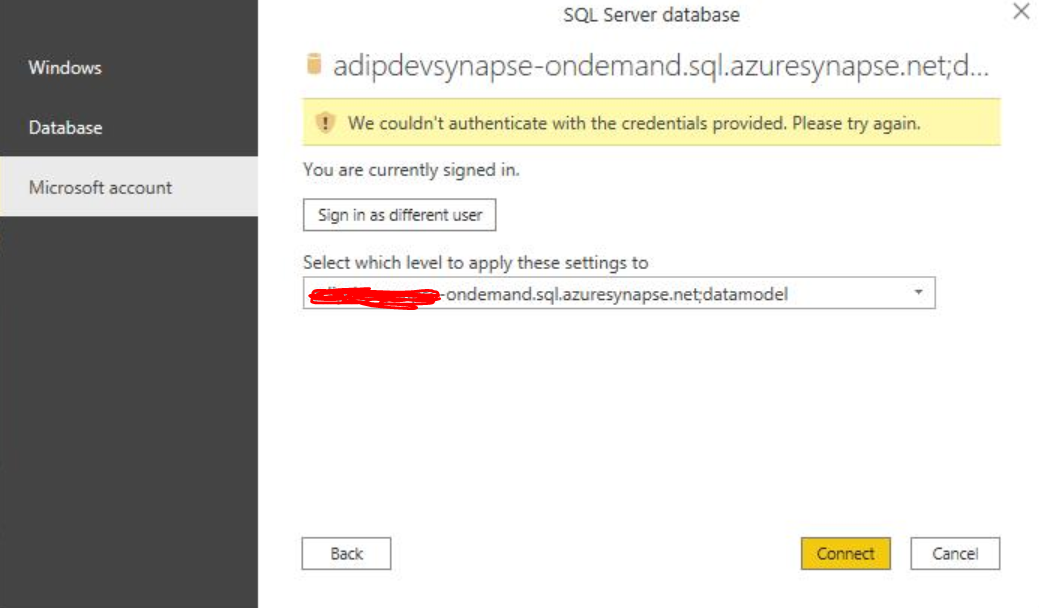
What am I doing wrong here?
Since a SQL login can't be given storage account permissions, it doesn't work with accessing the built-in external tables for Spark. You could set up an additional copy of external tables that use SAS authentication, but if you have AAD login available to you, I would recommend going that route.
Is the issue service-wide or is it limited to this particular user?
The problem is not limited to this user only. As mentioned, the user is Storage Blob Data Reader on the resource group, so it is not limited to SQL access.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EPH%3C/text%3E%3C/svg%3E)
II'm using an AAD account and get the same issue, although you can add at the Server level there is no way to provide authentication at the Database level so you appear to be stuck with the accounts created on provisioning...which is unhelpful
I have given the service account the 'Synapse SQL Administrator' role in Azure as well as the 'Storage Blob Data Reader' and it's now able to access the database instance. I guess that's because it has implicit access from being an admin so bypasses the need for a database user