Azure HDInsight
An Azure managed cluster service for open-source analytics.
200 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EY%3C/text%3E%3C/svg%3E)
Hello
As I described in this title, when HDInsight worker node is stopped for some reason(not for Azure infrastructure issue, but for the issue inside worker nodes stems from such as CPU or memory issues), the worker node will be automatically rebooted?
I am also working with AWS cloud, and in AWS auto-scaling tries to retain the least number of an instance working range configured like minimum is 1 and maximum is 2.
Is the same process working in Azure to retain the minimum worker?
Or we have to ssh into head node and reboot the worker nodes manually?
If manual operation is required, is there any service to monitor the status of worker nodes for us to recognize stopped worker nodes?
Thanks in advance.

Hello @yu ,
Thanks for the question and using MS Q&A platform.
Yes, the node will be automatically rebooted.
In order to provide you with optimal levels of availability for your analytics components, HDInsight was developed with a unique architecture for ensuring high availability (HA) of critical services. Some components of this architecture were developed by Microsoft to provide automatic failover. Other components are standard Apache components that are deployed to support specific services.
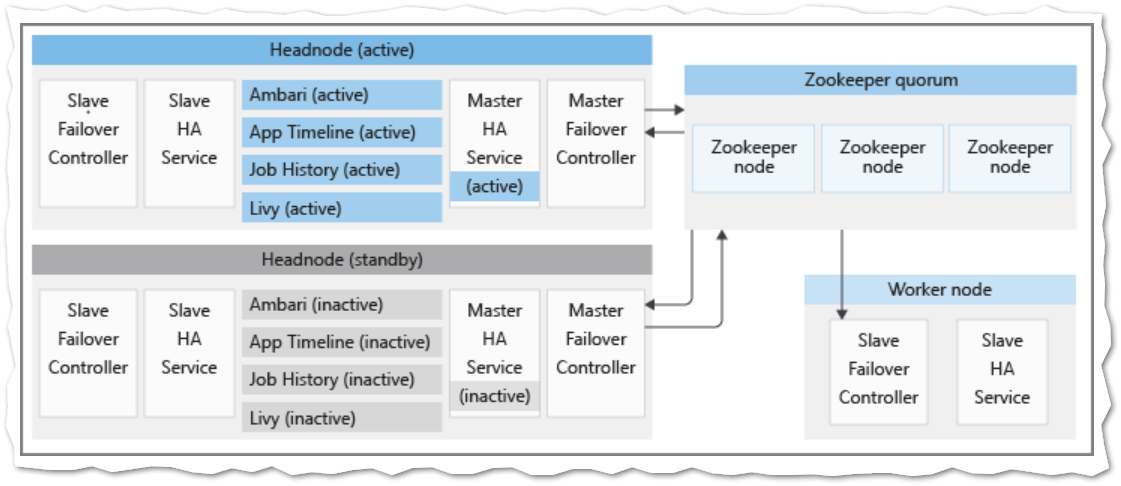
This infrastructure consists of a number of services and software components, some of which are designed by Microsoft. The following components are unique to the HDInsight platform:
The slave failover controller runs on every node in an HDInsight cluster. This controller is responsible for starting the Ambari agent and slave-ha-service on each node. It periodically queries the first ZooKeeper quorum about the active headnode. When the active and standby headnodes change, the slave failover controller performs the following:
The slave-ha-service is responsible for stopping the HDInsight HA services (except Ambari server) on the standby headnode.
This article explains the architecture of the HA service model in HDInsight, how HDInsight supports failover for HA services, and best practices to recover from other service interruptions.
Hope this helps. Do let us know if you any further queries.
------------
Please don’t forget to Accept Answer and Up-Vote wherever the information provided helps you, this can be beneficial to other community members.
Hello @yu ,
Just checking in to see if the above answer helped. If this answers your query, do click Accept Answer and Up-Vote for the same. And, if you have any further query do let us know.
Hello @yu ,
Following up to see if the above suggestion was helpful. And, if you have any further query do let us know.
Take care & stay safe!