Azure Machine Learning
An Azure machine learning service for building and deploying models.
2,548 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EMY%3C/text%3E%3C/svg%3E)
Hello,
I would like to convert a file dataset into a dataframe using a python script to use the data in a pipeline. I need to use the file dataset as i want to train my model using the files and not the table.
Thank you!

@MEZIANE Yani I think you could try this to use the filedataset as pandas dataframe, download and use it for your experiment's training.
from azureml.core import Dataset
from azureml.opendatasets import MNIST
import pandas as pd
import os
data_folder = os.path.join(os.getcwd(), 'data')
os.makedirs(data_folder, exist_ok=True)
#Download the dataset
mnist_file_dataset = MNIST.get_file_dataset()
mnist_file_dataset.download(data_folder, overwrite=True)
#Use the files in dataframe
df = pd.DataFrame(mnist_file_dataset.to_path())
print(df)
#Register the dataset for training
mnist_file_dataset = mnist_file_dataset.register(workspace=ws,
name='mnist_opendataset',
description='training and test dataset',
create_new_version=True)
Thank you very much for your response.
Before training the model, I have some data modifications to do in the pipeline (I am using design) and with this approach I cannot pre-processed the data within the .csv files. Is there a way to do this?
Additionally, even just for the training in design I must select a label column and is not letting me do this, as it doesn’t recognize the header within the files. Thank you very much for your help!
@MEZIANE Yani Do you mean editing the file contents after upload? I don't think that is possible from the designer.
You can however select the header in your file using the following options for tabular datatypes when you upload and register it as a dataset.
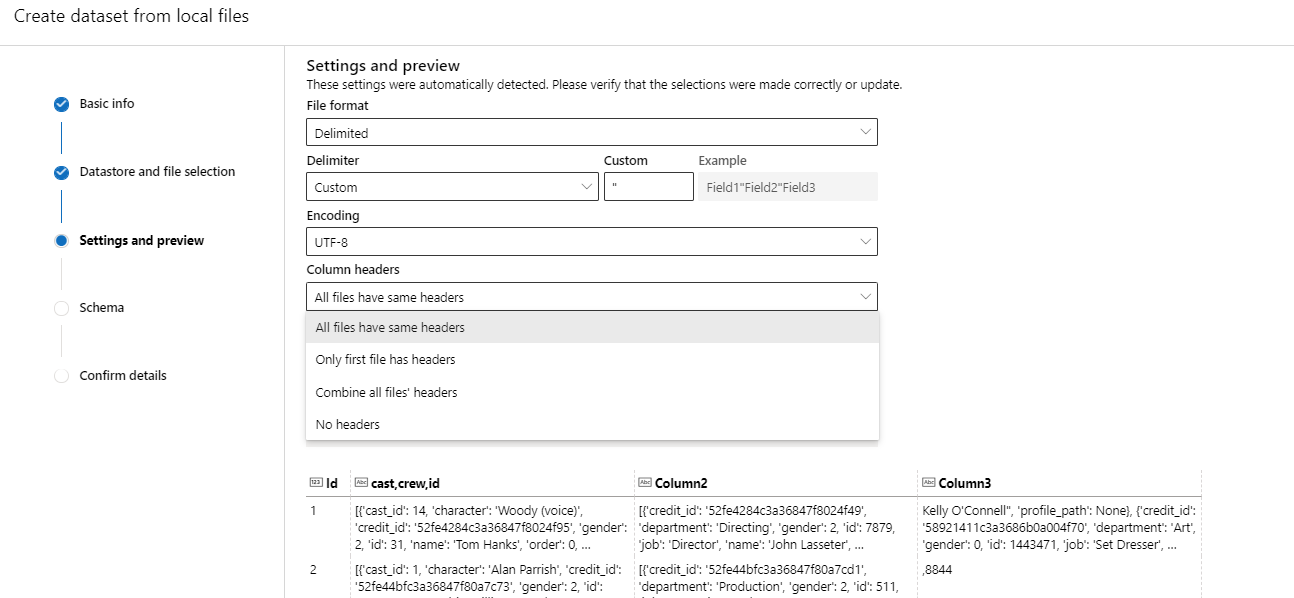
My aim is to run a pipeline (pre-process data and tune model hyperparameters) that I already have with design using as input data not each row of a table as it does with a tabular dataset but rather for each CVS file that represents an object (its information with a lot of rows) as input since the random selection per frame is amplifying the performance of the model. I have the data as tabular and files in a dataset. I have managed to get the path of each cvs file; but cannot read them as part of a new dataframe. I have the data in a datastore and dataset, so I don’t know if to accomplish this I should store the data elsewhere (I have not been working long with Azure so I am not acquainted with all the storage possibilities and the interactions between these and the ML studio.)
I manage to do this in python with the following code:
listOfFile = os.listdir(path)
for file in listOfFile:
new_well=pd.read_csv(os.path.join(path,file))
And in Azure this is as far as I have gotten without result:
ds = Dataset.get_by_name(ws, name='well files')
ds.download(data_folder, overwrite=True)
df = pd.DataFrame(ds.to_path())
df= dirr+df
files = pd.DataFrame(df)
well = map(pd.read_csv, files)
but I cannot use this output of well into the design pipeline due to being class map.
Thank you very much for your help. It is greatly appreciated as I really have no clue whatsoever on how to proceed or solve this.
For the part where you would like to read a csv file as above. This should work with a tabular file dataset. So, you can basically pass each of the file location to the tabular dataset and read them.
from azureml.core import Dataset
datastore = ws.get_default_datastore()
datastore.upload_files(files = ['./local_file.csv'],
target_path = 'train-dataset/tabular/',
overwrite = True,
show_progress = True)
dataset = Dataset.Tabular.from_delimited_files(path = [(datastore, 'train-dataset/tabular/local_file.csv')])
# preview the first 3 rows of the dataset
dataset.take(3).to_pandas_dataframe()
Is there a way to do this with multiples .cvs documents?
I have a folder full of cvs files I need to read, is there a way to give the path of the folder and for the program to read all of the cvs files within that folder?
There are a lot so not really feasible to do them one by one.
Ok I managed with this very simple line:
tabular_dataset_3 = Dataset.Tabular.from_delimited_files(path=(datastore,'weather/**/*.csv'))
However, I’m afraid this will not help me accomplish my objective as all the files are now in the same tabular dataset and now, I need the training of a model to be done considering the files and not all the rows, meaning that there will be random selection per frame and not per document as I desired. I need to pre-process the data and split the training and test dataset based on the csv documents, not on a table containing all the data points.
Thank you for your help!