Azure AI Speech
An Azure service that integrates speech processing into apps and services.
1,402 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ELF%3C/text%3E%3C/svg%3E)
Hi,
We want to use your solution for speech to text service.
Our use case is the following one, we want to get the transcript from an audio, but we do not know from which language the audio is.
I noted that the language detection has some limits:
Language identification currently has a limit of four languages for single-shot recognition, and 10 languages for continuous recognition.
Is the limitation about the number of languages to search into or about the number of different languages that can be detected from the audio ?
As we do not know in which language the audio is, we may need to detect the language between all the one you can detect.
The time to detect a language between more than 2 seems quite long. What about it ?
Moreover, I tested to detect the language from an English audio between German and English, the result was German detected, it is quite weird. What can be the source of the issue ?
Do you have an audio to test your feature with ?
Thanks a lot for your precious answers,
Laure Florent
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EYM%3C/text%3E%3C/svg%3E)
Thanks for reaching out to us, we are checking internally to see anything can help.
Regards,
Yutong
Hello,
Sorry for the delay. The limitation means you have max to 4 language in the single-shot recognition. For which language is supported by language detection, please refer to below table, there are around 30 languages are supported now:
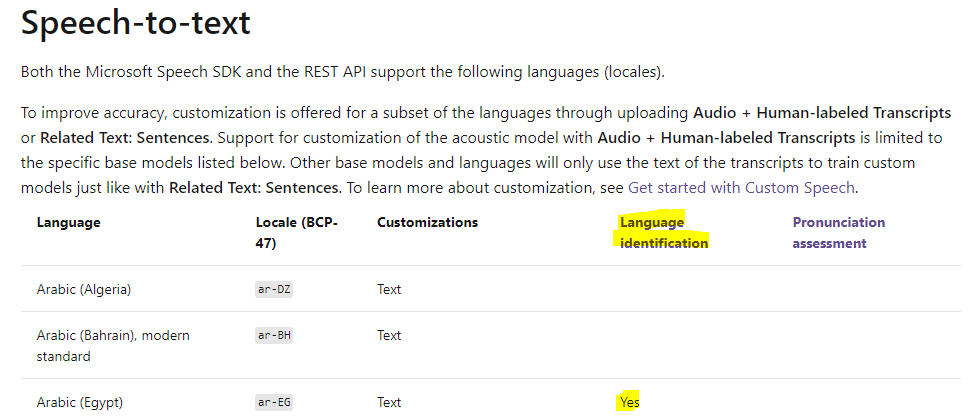
For more samples code and sample input, please refer to here: https://github.com/Azure-Samples/cognitive-services-speech-sdk
Hope this helps.
Regards,
Yutong