Azure Data Lake Storage
An Azure service that provides an enterprise-wide hyper-scale repository for big data analytic workloads and is integrated with Azure Blob Storage.
1,348 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ERD%3C/text%3E%3C/svg%3E)
Hi,
I have an initial 1000s of delimited files in Azure Data Lake Gen 2 storage account. I need to read all these files and create them as single dataset for analysis. This dataset must be preserved for future files. After these files are processed, there will be only few files every day which will need to be read, then the new data should be added to the existing dataset. Business users might use this single modeled data set for analysis.
Currently it takes lot of time to query all these files. We want a faster and cost effective approach.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ESM%3C/text%3E%3C/svg%3E)
@Ramanathan Dakshina Murthy - Just checking in to see if the below answer provided by @Thomas Boersma this answers your query, do click Accept Answer and Up-Vote for the same. And, if you have any further query do let us know.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ETB%3C/text%3E%3C/svg%3E)
Hi @Ramanathan Dakshina Murthy ,
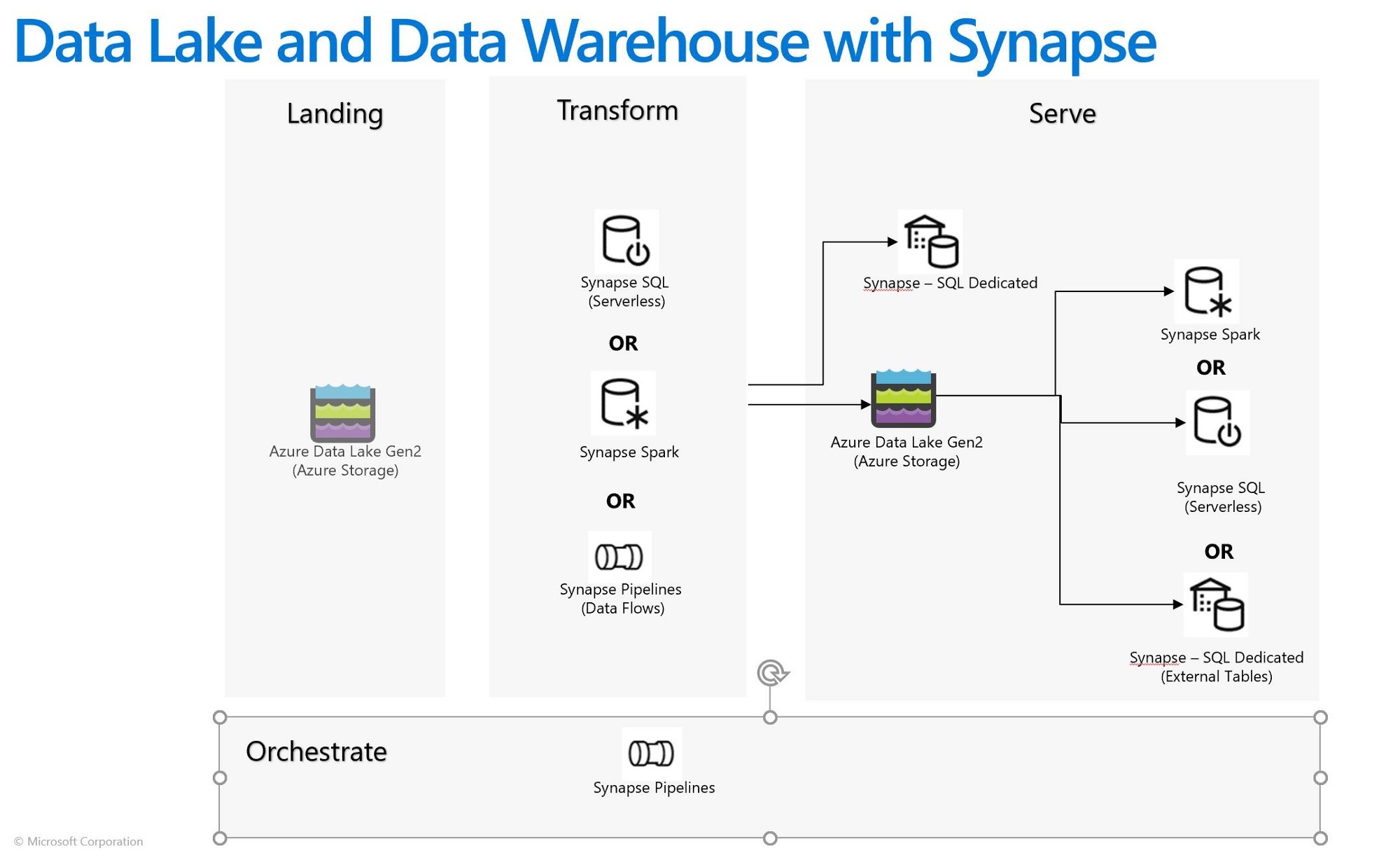
A possible solution is to create a staging folder inside you Azure Data Lake Gen2 (ADLS Gen2). Inside this staging folder you will place the delimited files that needs to be processed / transformed. Processing can be done with a Data Flow within Azure Synapse or Azure Data Factory, if the transformations are too complex you could use a notebook via Databricks or with the integrated Synapse notebooks. The source of the process should import all the delimited files, for example with a wildcard: staging_folder\*.csv.
When the data is loaded into the data flow or data frame you can process data. After the processing is done, you can store the data as a Delta Lake table within your ADLS Gen2. The delimited files should be deleted from the staging folder at this moment, because you don't want that the files are processed for a second time. At the end you can create a Synapse database view (with the Synpase serverless pool) on top of the Delta Lake table within you ADLS Gen2 for retrieving the data. I added an image where you can see in an abstract way the steps I described.
A benefit of Delta Lake is that you can create partitions on your data, what makes it more performant and cost effective, if you set the partitions right. It also saves the files as Parquet which is more compressed than csv. This works with hundreds of millions of rows, but if your dataset grows by more than a few billions I would recommend replacing the Delta Lake table with a Synapse Dedicated database. A dedicated database is very expensive compared with a serverless pool, but a lot faster.
Hope this helps.
Hi,
Thanks for your reply. I still have few questions though. Reading those files in Azure data factory can create performance issue because all those billions of data might be in memory. We would like to use the advantage of clusters, compute options, parallel processing and read those files lot quicker, process them and query them for analytics. Any suggestions?
Hi,
You can adjust the number of clusters according your needs in a data flow, see here how. At the end, the resulting data flows are executed as activities within ADF/Synapse pipelines that use scaled-out Apache Spark clusters. ADF/Synapse handles all the code translation, path optimization, and execution of your data flow jobs.
But if you want to change more of the settings regarding CPU/RAM I would suggest that you use Databricks, see here the possibilities of configuring clusters on Databricks. With Databricks you will always have more settings to change, however you need to write your own code and that sometimes takes longer time.
Another option is that you create durable Azure Functions with a Fan out/fan in pattern.