Internet Information Services
Microsoft web server software.
1,582 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EVS%3C/text%3E%3C/svg%3E)
Hey, I have a LB set up in Azure that fronts 2 VMs. There is a health probe that determines "health" status of the backend servers and once the VM is reported as unhealthy, all new connections are routed to the only healthy node.
My problem is that the existing TCP connections are still routed to the same node which could be now unhealthy which creates an interruption in service. I have set IIS app pool Rapid-Fail Protection setting to TcpLevel which should terminate all TCP connections when app pool is shut down. However, existing connections are still routed to the server after app pool is stopped. Is there a way to force new tcp connections to be established in this scenario?
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EBZ%3C/text%3E%3C/svg%3E)
Hi @Vitalii Stadnyk ,
Why you set Rapid-Fail Protection to TCP level? As IIS said, if set to TCP level, http.sys will reset the connection. So the connection will route to the server again. Rapid-Fail Protection is not to protect or create a new connect when application pool crash. It will stop application pool when the application pool crashes to the set conditions.

Hey, thank you for getting back to me. I expect tcp connection to be reset by HTTP.sys when I stop app pool with TcpLevel setting selected.
The issue though is that requests from clients are still routed to "dead" instance during deployment. I am looking for a way in Azure LB to route ALL requests (new and existing) to a healthy instance. Do you know if there is some setting that I am missing for it?
Here is an example of current behavior:
I would like to set it up in a way that in step 3 User X is routed to a healthy instance.
Hi @Vitalii Stadnyk ,
I'm not sure how you set load balance because I'm not engineer of Azure. If you set load balance in ARR of IIS, ARR load balancer health test and live traffic test will check whether the resource servers every few seconds. If it detect unhealthy response, then it will mark the corrupted as unhealthy. Then all requests will be routed to other server. You can get this information from this document.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EM%3C/text%3E%3C/svg%3E)
Hi @Vitalii Stadnyk ,
Did you finally find a solution to get the user routed to a healthy instance in step 3?
I am facing the same issue with Azure Load Balancer (standard tier). When an application pool goes down, it takes about 10-20 seconds for health probe to mark VM as unhealthy. From this point new connections are routed to another VM in the backend pool. But existing connections are still being routed to the unhealthy instance.
I have set "Service Unavailable" Response Type for IIS Application Pool to TcpLevel (from HttpLevel) but it makes no difference.
Here you can see the Azure Load Balancer configuration:
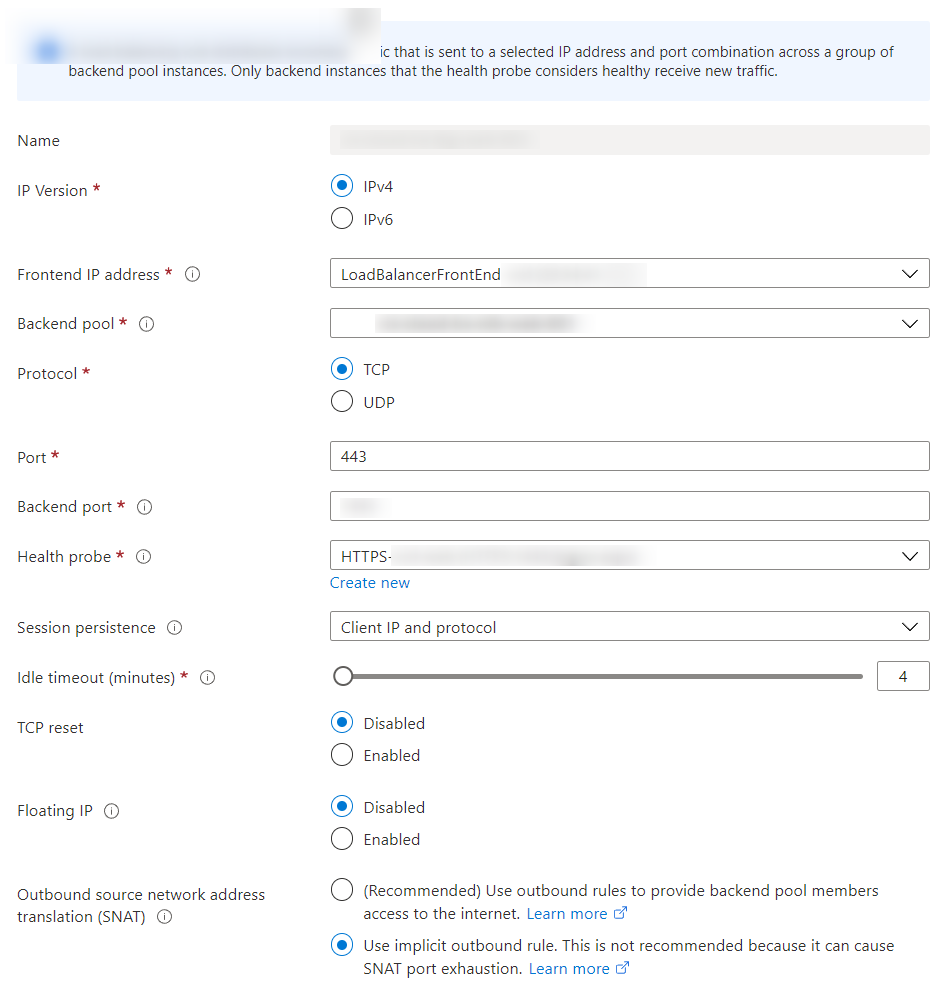
Values for Session persistence, Floating IP and Outbound SNAT must be configured this way, due to other restrictions.
I've tested with different values for TCP reset - turned it on and off. But this makes no difference to reported behavior.
I believe Session persistence could speed up switching to healthy VM, because user could basically get a new route on every request. But we explicitly want to have session persistence, so user "stays" on a vm - as long as it's healthy.