AzureML中的回归
在Microsoft Azure Machine Learning中提供了以下几种回归模型:
- 贝叶斯线性回归 Bayesian Linear Regression
- 提升决策树回归 Boosted Decision Tree Regression
- 决策森林回归 Decision Forest Regression
- 快速森林分位回归 Fast Forest Quantile Regression
- 线性回归 Linear Regression
- 神经网络回归 Neural Network Regression
- 有序回归 Ordinal Regression
- 泊松回归 Poisson Regression
那什么叫回归呢?在统计分析中,回归是研究一个随机变量Y对于另一个(X)或一组(X1, X2, …, Xk)变量的相依关系的统计分析方法。我们通常把X1, X2等叫做自变量,在机器学习里又叫做Feature(特征),而又把Y叫做因变量,也就是我们希望预测分析的部分。Y一般都是数值,是连续的,而在分类中我们预测的部分通常只有个别的几个值/类, 所以我们可以了解回归Regression与分类Classification的差别。在回归里,自变量可以是数值型的也可以是分类型的,而因变量是数值的。
回归模型就是构造一个从x到y的映射关系。最简单的回归情形是当单个因变量和单个自变量为线性关系时,也就是一元线性回归(Linear Regression),通常的模型就是Y=a+bX+ε, 即在二维坐标上是一条直线,a是直线的截距,而b为直线的斜率。ε为随机误差(通常假定随机误差的均值为0)。通过获取样本数据,我们可以把这些点画成散点图,然后求解对应的系数a和b的值,这样就可以用一条直线来代表这个数据模型。当有新的自变量值输入到模型,我们就可以通过这个模型计算出因变量值从而进行预测。线性回归当然也可以是多元的,就是有多个X,互相之间是独立的。除了线性回归,还有非线性回归,也就是曲线或者曲面的回归。比如我们可以通过S型函数来进行逻辑回归。而更一般的情况是多元的情况。比如贝叶斯线性回归假设随机变量的概率分布近似于高斯分布也就是正态分布来描述,通过最大后验概率来求解回归问题。而泊松回归则假设因变量Y是泊松分布,并假设它期望值的对数可以被未知参数的线性组合建模。
决策树本来是应用最广的分类算法之一。决策树可以表示成多个If-Else的规则。它其实是将空间用超平面进行划分的一种方法,每次分割的时候,都将当前的空间一分为二,比如说下面的决策树:
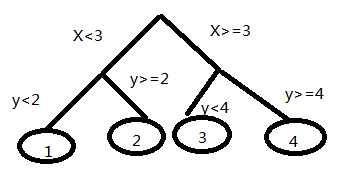
我们可以在二维坐标中画出来:
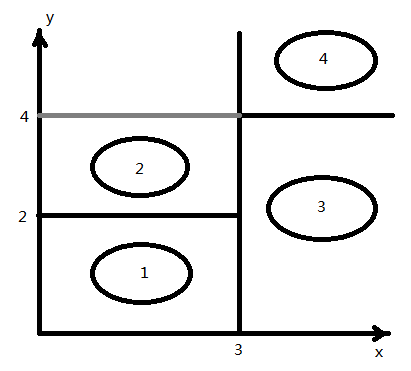
这样我们可以在一个待分类的样本实例进行决策的时候根据2个特征(x,y)的取值来划分到对应的一个叶子节点,得到分类结果。这就是决策树分类的过程。而提升(Boosting)是属于模型组合的方法之一,通过组合效果可以比单个模型更好。Boosting就是用弱分类器先分类,然后把上次分错的数据权重提高一点,然后再分类,这样最终得到的模型效果比较好。在决策树上运用这个思想就可以达到更好的效果。而回归树选择变量的标准用残差平方和。在决策树的根部残差平方和就是回归的残差平方和。然后选择一个特征,使得通过这个进行分类后的两部分的分别的残差平方和的和最小。然后在分叉的节点再利用这个准则进行分类,生长成一个树。而在这个基础上,我们还要进行剪枝,通过训练样本来进行评估,如果被减的树中得到的残差平方和缩小了,那么剪枝就是有效的,否则就不剪。在机器学习中,随机森林包含多个决策树, 输出的类别是由个别数输出的类别的众数而定。而决策森林结合了随机森林和随机子空间方法来建造决策树的集合,它引入了模型组合的另外一个重要方法,也就是Bagging。对于每个节点会随机选择m个特征,根据这m个特征计算其最佳分裂方式。这里每棵树的成长是不会剪枝的。
在统计里面,有序回归是一类回归分析用来预测一个有序变量的。有序变量可以这样理解:比如我们评价客户满意度从1分到9分,1到3代表”非常不满意“,4到5分表示”不满意“,6分到7分代表”满意“,8和9代表“非常满意“。这就是有序变量。
而人工神经网络回归可用于非线性回归,是一种大规模并行非线性系统,具有良好的非线性映射能力,强大的解决问题的能力和实际推广能力。它是一组算法来模拟大脑的工作。神经网络算法有很多种,最主要的是backpropagation,又叫多层感知器。通常有三层网络:
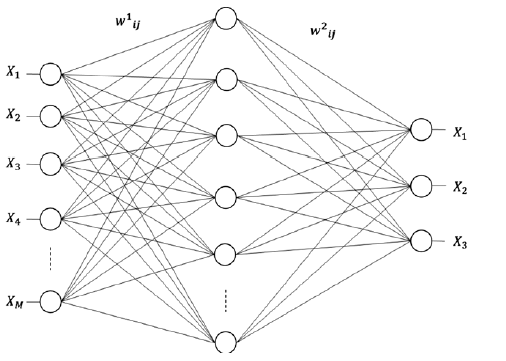
最左边的是输入层,中间是隐藏层,而右边是输出层。当然我们可以有更多的隐藏层。一般输入的节点数相当于独立自变量的数量。而输出节点数为因变量的数量。而隐藏层的节点数就比较复杂。在训练阶段,我们给网络喂一组样本。在向前传播过程中,在隐藏层和输出层的节点会计算一个加权的输入总和,然后用这个总和通过一个激活函数来计算它的输出。通常我们用S型函数,或者高斯,甚至线性函数来作为激活函数。当输出计算好了以后,向后传播的步骤就开始了。在这个阶段,算法会计算预测值跟实际值的误差。使用梯度下降的方法,它调节所有回传误差连接的权重。这些权重的调整能够减少下次的误差。通过一系列样本的列举,最终神经网络形成对应的模型。在这其中,有2个参数比较重要。一个是学习的效率(learning rate)。如果效率太低,那么列举就多,时间就长。而效率太高,可能很难找到局部极小值。另一个是关于隐藏节点数量。随着隐藏节点的数量增加,模型的精确度可增加,但却会造成过拟合。通常我们设定输入节点数的平方根作为起始值或者这个值在输入节点数和输出节点数之间比如(输入节点数+输出节点数)/3。通常只有在测试中才能调整到比较合适的值。