Security Reviews: The Heuristics Zoo, Part 2/2
Note: standard Disclaimer expressed in Part I applies here as well.
Heuristic 5: "Area Expertise" and "Penetration Testing"
These two seemingly different techniques share a lot in how they approach managing the complexity of security reviews, so I will consider them together.
"Area Expertise" is simply learning. Studying a technology long enough can make one a Subject Matter Expert (an "SME") who knows all subtle interactions within the area and can recognize possible security issues there quickly. This approach is orthogonal to an "audit". While "audit" spans a horizontal area across the product, an expertise would tend to occupy a deep "vertical" cut of a limited width. E.g., an expert may know how to write interfaces with static methods on them in Intermediate Language -- but would have no idea about network security:
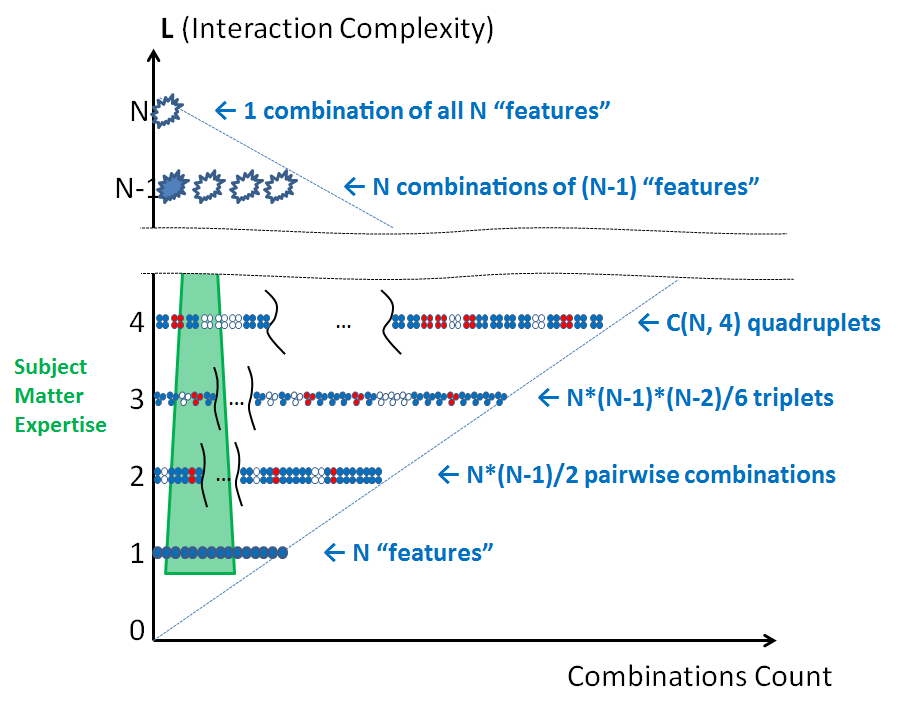
Penetration testing is a technique that seeks (to some degree) to re-create SME effect on a faster timescale. It starts with carefully choosing a sub-set of a product "surface" that appears to be softer. Then, with a help of tools and deep design dives it seeks to pass through the L1-L2 complexity levels and gain a control over a set of more complex interactions, typically at Level 3 and deeper. As many security heuristics would have patchy coverage at complexities above L2, chances are good that executing or examining that functionality would reveal new security holes.
Importantly, pentesting cannot be used to ensure large products security. As it focuses on higher order interactions, it would need at least something like O(N3) time for that. Time and budget limitations would prevent such an algorithm from scaling across the entire product. Pentesting resolves this contradiction by reducing N – in other words, but precisely aiming at a smaller part of a product to break through.
Therefore, the value of pentesing is akin to that of a geological drilling. It measures product "security" by assessing the difficulty of breaking through its L1-L2 security "crust", and delivers samples not easily found on the surface.
Heuristic 6: "Learning from Attackers"
If you are an enterprise, you may have something like 104-1016 automatic security checks at your disposal to run against your product before giving it to the user. On top of that, there are 102-105 human verification questions available to apply, too. Seems like a lot? But a product with just 100 elements can have up to 1030 possible element interaction states! Even if 99.999% of them are void, the remainder still represents a space overwhelmingly huge and is beyond any technical or human capability. Within that vast space, where should we place our "tiny" 1016 security checks?
Well, the good news is that we actually don’t need to find all security holes. We need to find only those that attackers can and will (eventually) find. With that leverage, the effectiveness of the security assurance can be boosted by orders of magnitude, enabling practical and effective security defense.
What specifically could be done?
First, you can study past attacks against your product or other similar ones on the market. How are they typically attacked? What are the top 5 classes of security vulnerabilities they had faced? https://cve.mitre.org/ could be a good starting point for such an assessment.
Second, you can attend security conferences and talk to security researchers. Or, if travel budget is an issue, just read abstracts of their presentations and summaries of their talks. Even in such form the knowledge gain can help you predict how your product would be attacked in 1-3 years. By smartly prioritizing security assurance work then it could be shrank in volume (compared to "blind" planning) by a factor of 2-10 times.
Finally, if you are an online service, you can learn security attacking patterns from your logs! That way, attackers actually work for you. Any new creative idea they come up with becomes part of your tools set. For free. Isn't it cool? Of course, this is easier to say than to do. Putting together a proper monitoring & detection solution is a daunting task. But the benefits are so great that I would definitely strive for that.
Mind the privacy though – you don't want any sensitive or private users' data to be exposed internally or externally in the process.
By the way, not only services can benefit from that approach. Traditional "box" products can collect crash reports and mine attacks in them as well, thus improving their security posture.
Heuristic 7: "Scenario Fuzzing"
A JPG file may miss up to 90% of information contained in the original bitmap image. Yet for a human viewer it represents all the essentials of the picture. Conceptually, this is achieved by abandoning a “dot” as a principal element of image construction and choosing a “wave” for that purpose.
Can we apply the same idea? Can a very large product be effectively represented with a number of elements substantially smaller than its feature count?
Personally, I'm quite positive that is possible, and possible in many ways. Here I will discuss one of them that is based on the concept of an end-user scenario.
What is a "scenario"? A scenario is a description of some meaningful user's interaction sequence. An example would be: "launch the browser, login into your email account, read new messages, log-off and close the browser." A product could be represented then as a set of scenarios it supports.
Why would that work?
First, scenario-based description is complete. The proof is obvious: if there is a functionality that is not activated in any legitimate user interaction, it is a dead code. Throw it away. No customer would notice that, ever.
Second, scenario representation is compact. Typically, scenarios drive product requirements, which drive the specifications, which produce the API, then the code, and thus the product itself. A single use case quoted above would already hit thousands APIs and dozens of features in a contemporary OS. A few hundred scenarios often completely describe even a large product.
In fact, for a product where scenarios "choose" features to participate randomly and independently of each other, the number of scenarios needed to execute all features grows logarithmically with respect to feature count: S = O(Log(N)) . While that is probably not exactly how real products are structured, it still demonstrates the power of scenario-based product description at least for some cases.
Effectively, scenarios play a role similar to that of a “coverage graph”, providing access to a vicinity of each and every possible functionality combination in a product.
How do we use that to discover security weaknesses?
If you look carefully at security breaches you'll see that most have valid user scenarios closely associated with them. When an attacker breaks into a system, he/she mostly interacts with it in ways that are fairly close to what a "legitimate" user would do. Those are only 1-3 unexpected "twists" that throw the system into a state of abnormal that may further lead to exploitability.
In other words, an attack often is a scenario that differs from a legitimate use by few changes. If so, can it be derived from a legit scenario by some morphing, using techniques such as random tweaks, grammar-based generators, genetic algorithms, or N-wise combinations building?
After all, if we do fuzz binary inputs, why not fuzz scenarios?
Many security reviewers do exactly that. They take a valid workflow and morph it. “Next step: FTP log-in. Well, what if I send my log-in packet twice after seeing a 100 response but right before a 200 is received? Or what if I start sending log-in packet, but will never finish it?”
Such variations may trigger completely new sequences of calls within the system and cause interactions between components that have never been in touch before… and sometimes result in an unexpected behavior.
Personally, that’s why I tend to start security reviews with a simple question of “please give me the user’s perspective”. That’s my minimal "fuzzing seed” – a valid use case that I can tweak to produce new variations.
Scenario fuzzing is intuitively easy. It scales well with respect to the scenarios count involved. It naturally considers multi-component interactions and can, in theory, discover completely unknown classes of security bugs.
But of course it has its limitations as well.
First, today it is primarily a human-driven process. I’d be very happy to see a tool that can do that job but I think our scientific understanding of natural languages is just not there yet. This tool would need to be able to take a valid English description of a scenario, tweak it, and produce a different (yet still meaningful) description as an output.
Of course, this does not have to be done in English. There are artificial formal languages for scenario description in software industry. They may offer a better starting point for this approach.
Second, it takes years of security training and a good bit of human creativity to come up with good scenario tweaks.
Third (and the most important) its' practical application is limited by the knowledge limits of your data sources.
It is easy to ask crazy questions like “what if I do A before doing B, without doing C, while continuing to do D at the same time?” However, in many cases neither the specification, nor the product team would be confident in the answer! In fact, hitting a blank look and “we don’t know” is an indicator that the review is within the space that nobody has deeply thought through before.
But does that help? If most of these questions eventually lead to boring answers, people will quickly learn to ignore your requests. Because obtaining the answers might be difficult for them. It could take hours of examining the source code, or getting a response from SMEs, or painful debugging. Plus it takes great tenacity to make sure that email threads do not die, that people keep working on your questions and deliver consistent answers.
So it requires building great trust with people. While operating in this mode, you need to make sure you are asking "good" questions frequently enough so that people would not learn to dismiss them as "mostly useless" based on past observations.
What is the complexity of this algorithm? It's hard to say. It really depends on the specific mechanism chosen to generate new scenarios. And it does not even have a defined stopping point, so formally speaking this is not even an "algorithm".
Just for the sake of illustration, we can assess the complexity for one special case when:
- Fuzzed scenarios are produced by random tweaks of legitimate scenarios, and we do t tweaks per each one
- Scenarios use features randomly and independently of each other
For that case, the complexity of the review could be shown to be approximately O(t*Log(N)) – in other words, it's less than linear! How's that possible? The short answer is because in scenario fuzzing, one question executes many features, and the reviewer does not need to explicitly know them all. So he/she doesn't have to spend O(N) time enumerating them – that has already been done by the engineering team when they designed and built the product.
Item 8: What about Secure Design and Layers of Abstraction?
I'll say it upfront: neither of them is a review heuristic. They are design techniques. But as it's simply impossible to avoid this topic while discussing software security, I'll share my view on it.
So, in a system of N elements where each can (generally) interact with each other one, there are potentially up to 2N various interaction combinations possible. That causes security review to be exponentially complex and generally unmanageable in practice.
But what if we avoid that "any-to-any" interaction pattern and bring some structure into the system?
One way of doing that could be logical arrangement of product elements into a two-store hierarchy where:
- The lower level elements are bucketed into groups each "reporting" to a parent element. Lower elements can freely talk to each other within the group, but cannot converse across the group boundary
- All cross-group interactions happen through the top-level elements that talk only to each other or their "child" groups.
Here is how it may look like:
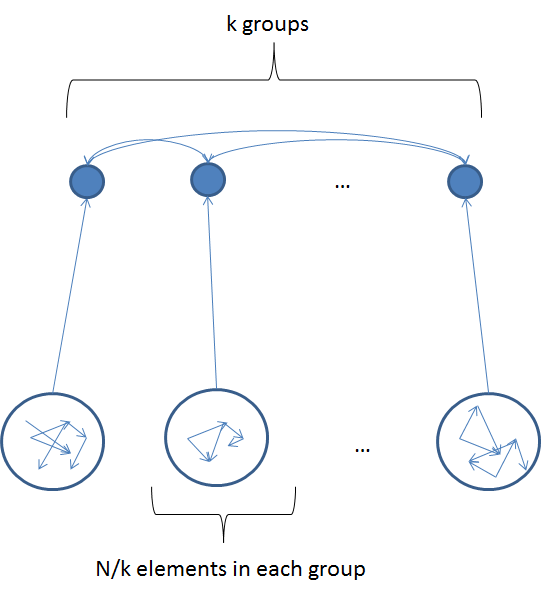
What would be the total number of checks needed to ensure the secure design of such a system? Obviously, it will require 2k checks to cover the upper level, plus k times 2N/k for the lower:
T = 2k + k*2N/k [3]
What is the choice of k that minimizes that number? That's answered by demanding that ∂T/∂k = 0 and solving the resulting equation. While the precise solution is impossible to express in common functions, a good approximation for N >> 1 is easy to obtain:
k ≈ N1/2 + ¼ Ln(N) [4]
With the corresponding number of needed security checks being then:
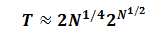 [5]
[5]While that is still a huge number, it is tremendously smaller than 2N checks needed for a "disorganized" system where just everything interacts with everything. So arranging a system as a 2-layered hierarchy brings in a great reduction in complexity of the security assurance.
Can we capitalize on that and introduce more layers of abstraction, somewhat similarly to the OSI model?
The answer is positive. For a system with L such layers the total number of security checks needed (very approximately and assuming very large N) is even further reduced to:
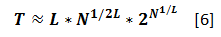
Why not continue adding layers indefinitely? Because there is a design and implementation cost behind each next layer of abstraction. So there needs to be just enough of them to keep the system manageable – but not more. How many, exactly? If your budget of security checks is T, and there are N >> 1 atomic elements expected to be in the system, the count is obtained by inversing [6], and it is, roughly:
L ≈ Ln(N)/Ln(Ln(T)) [7]
For a product 10 Gb in size with 1 million security checks budget that evaluates to L ≈ 10. Not surprisingly, it is quite close to the number of abstraction layers in the OSI model, because the dependency on both input parameters is rather weak.
In fact, a logarithm of a logarithm of pretty much anything in our Universe could be considered a constant for most practical uses :))
Now when we are done with that, let's make a few sobering notes.
First, as a security reviewer, you rarely face a large product that you have a chance to design "properly" from scratch. More often you face systems already mostly designed, with a long history of past versions, people joining and leaving, patches, changes, and even acquisitions. Your responsibility is similar to that of a doctor, who needs to diagnose a patient and give actionable advice while fully accepting their background, past life events and known health issues.
Second, even if you get a chance to design something from the beginning, I seriously doubt that such a thing as "Secure Design" exists in practice. Sure, it would be nice to live in a world where no unexpected higher order interactions between components are possible, and all lower-order ones are documented. But I doubt that's possible. In my opinion, there is no such thing as "completely non-interacting features". There are only features with very low interaction probability. So every time you think you've eliminated a class of unwanted interference, a completely new one surfaces right behind it…
Functions A and B may never call each other. But if each one allocates one byte of memory dynamically, A may (potentially) eat the last memory byte precisely before B would need it. So suddenly B's call becomes dependent on A's execution state. Is that an effective control mechanism? Not really. But is that a dependency? Yes. And it may need to be factored into the analysis if the cost of a potential failure is represented by a nine digit figure.
Certainly, not keeping any function variables cures this problem. But even if software is (somehow?) completely removed from the risk picture, what about hardware failures? Believe it or not, some researchers have learned how to exploit results of memory corruptions caused by (among other things) random protons from the interstellar space hitting our memory chips -- see https://dinaburg.org/bitsquatting.html for details.
My personal take on that is that there is always some probability of an unexpected interaction. Eliminating one class of it brings up the next one, far less probable but way more elusive and difficult to eliminate. So some surprises will always keep hiding somewhere within the realms of higher complexity interferences.
That being said, a "Secure Design" as something that tries to minimize side interactions is valuable. While it may not be perfectly achievable, it may still bring the security of a product couple levels up in terms of the complexity analysis needed to successfully attack it.