End-to-End Scenarios Enabled by the Data Science Virtual Machine: Webinar Video
This post is authored by Barnam Bora, Program Manager in the Algorithms & Data Science team at Microsoft.
Microsoft's Data Science Virtual Machine (DSVM) is a family of popular VM images in Windows Server & Linux flavors that are published on the Microsoft Azure Marketplace. They have a curated but broad set of pre-configured machine learning and data science tools including pre-loaded samples. These DSVM offerings are configured and tested to work seamlessly with a plethora of services available on the Microsoft Azure cloud, and they enable a wide array of data analytics scenarios that are being used by many organizations across the globe.
Our team recently hosted a webinar to highlight some of the most popular end-to-end scenarios enabled by DSVM, and to demonstrate a few of these scenarios in detail. The webinar also covered the DSVM roadmap. A complete recording of the webinar is available for on-demand viewing below. The documents and examples used in the webinar are available at this GitHub Repository.
Scenarios covered in the webinar include:
- Using SQL Server R Services, for the Dev>Train>Test>Deploy>Score cycle.
- Using the Local Spark 2.0 instance on the DSVM for Dev & Test.
- Training and Deploying Deep Learning Models on GPU based Azure VMs. This features the Deep Learning Toolkit for DSVM.
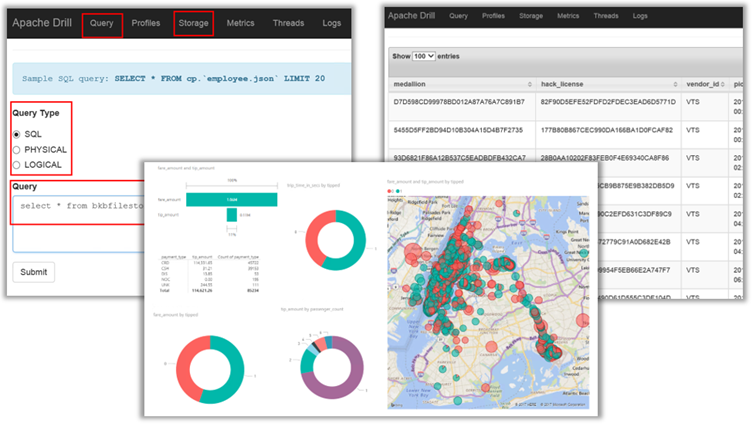
- Querying and wrangling across platforms, featuring Apache Drill and Microsoft Power BI.

Click here to view the webinar video on-demand on Channel 9, or on the above image.
Summary of Scenarios Demonstrated in the Webinar
The webinar is primarily geared to familiarize users on how to achieve the complete end-to-end workflows enabled by DSVM. It is not meant to be an introduction to Data Science and Analytics, however. Most of the scenario examples are based on Jupyter Notebooks that are included as part of the DSVMs.
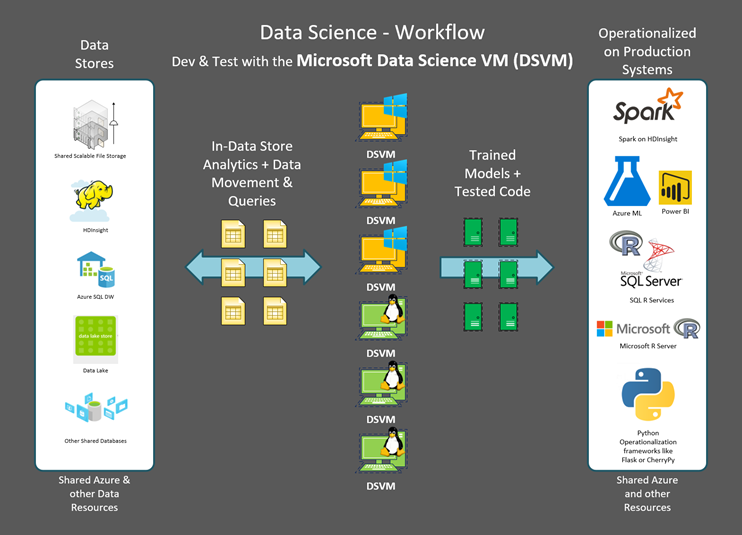
Using SQL Server R Services, for the Dev>Train>Test>Deploy>Score Cycle
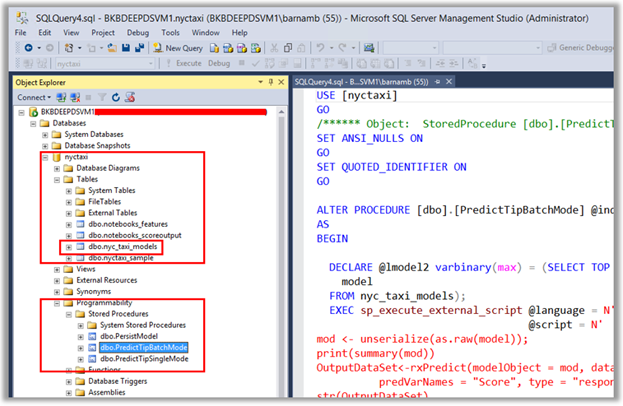
The Windows Server DSVM comes with the Developer Editions of SQL Server 2016 and Microsoft R Server (MRS) pre-installed. This scenario demonstrates the In-database advanced analytics features of SQL Server and the parallelized and scale-out capabilities available to Develop, Train, Test, Operationalize and Consume Predictive R models on large-scale data sets.
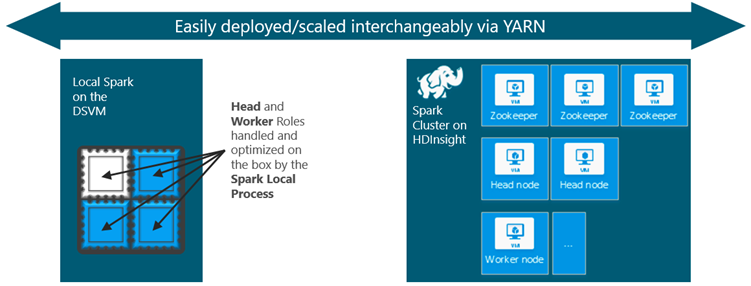
Using the Local Spark Instance on the Linux DSVM, for Dev & Test
The Linux DSVM comes pre-configured with standalone Spark 2.0 on a local Hadoop instance to help you build and test applications and deploy them on large scale clusters like Azure HDInsight Spark (or other Spark clusters). You can develop your code using either Jupyter notebooks or with the included community edition of the Pycharm IDE for Python or RStudio for R. Please refer to the detailed walkthrough available here.
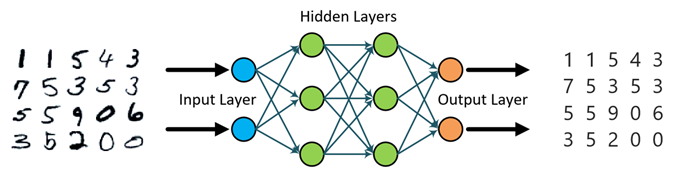
Training and Deploying Deep Learning Models on GPU-Based Azure VMs
The comprehensive Deep Learning Toolkit for DSVM extends the capabilities of the Windows Server 2012 edition of the DSVM, especially on GPUs, using popular Deep Learning tools. It is deployed on NC class VMs in Azure which have dedicated Nvidia GPU capacity on the machines, which can be used for parallelizing compute intensive workloads. This typically results in orders of magnitude improvements in performance. In our scenario demonstration, we utilize the open source Microsoft Cognitive Toolkit (formerly called CNTK) to showcase an example of character recognition using a deep neural network trained on GPUs.
Querying and Wrangling Across Platforms
DSVM comes with multiple popular querying and data wrangling tools pre-installed. In our webinar, we briefly showcase the use of Apache Drill (schema-free SQL query engine for Hadoop, NoSQL and cloud storage) to easily query non-relational stores such as Azure Blobs and local csv files using ANSI SQL syntax. We also show data investigation and analysis using Microsoft Power BI.
The goal of the Data Science Virtual Machine is to make developers and data scientists highly productive in their work by providing a broad array of popular tools in a comprehensive package. We hope this webinar was useful to understand the popular scenarios that DSVM is enabling.
We always appreciate feedback, so feel free to comment below or share your thoughts with us at the DSVM community forum.
Barnam
Connect with me @barnambora or via LinkedIn
Webinar Resources:
- Video on-demand viewing link for the webinar on Channel 9.
- GitHub repository for this webinar.
- Register here to receive content and viewing links over email through our webinar platform.
DSVM & Related Resources:
- DSVM community forum for community support and Q&A.
- DSVM listings on Azure Marketplace.
- DSVM introductory DIY workshop.
- DSVM product page – Windows.
- DSVM documentation – Windows.
- DSVM product page – Linux Ubuntu.
- DSVM product page – Linux CentOS.
- DSVM documentation – Linux.
- Deep Learning Toolkit for DSVM.
- Free test drive of Linux DSVM (8 hours).
- 2 page handout for DSVM.
- Learn Analytics @ Microsoft.