Vowpal Wabbit Modules in AzureML
This post is authored by Sudarshan Raghunathan, Principal Development Lead for modules in the Microsoft Azure ML Studio team based in Cambridge, MA.
In his blog post last month, John Langford wrote about the open source Vowpal Wabbit (VW) machine learning (ML) system. He highlighted some of the main advantages of VW, e.g. its performance and ability to handle large sparse datasets, which make it particularly popular both within and outside Microsoft for applications such as sentiment analysis and recommendation systems.
When we initially released the public preview of Azure ML in July this year, we exposed a small subset of VW functionality as part of our Feature Hashing module. The latter transforms datasets with text features into binary using the feature hashing algorithm (Murmur hash) implemented in VW. When we refreshed the service earlier this month, we added two new modules to our palette, Vowpal Wabbit Train and Vowpal Wabbit Score, and these expose almost all the functionality in VW with very similar performance characteristics, and, very importantly, allow models trained by VW learners to now be operationalized as web services on Azure. In the rest of this post, I will describe a few of the design decisions behind these two new modules and some of the implementation details and work in progress to extend the functionality of other modules in Azure ML with VW.
Design of the module
Our primary target users for the new VW-based modules are data scientists who have already invested in VW for their ML tasks, be it in traditional areas such as classification and regression or more contemporary ones like topic modeling or matrix factorization. The VW-based modules allow such users to easily port the modeling phase of their workflows to Azure ML (taking full advantage of the powerful features and native performance of VW) and easily publish the trained model as operationalized services.
To this end, both modules expect their input datasets to be in the native text format supported by VW and the user of the modules to be familiar with the command line arguments necessary to perform the modeling task. Finally, today we only support reading training data from Azure Blobs.
Figure 1 illustrates a simple training experiment that creates a multi-class classifier using one-vs-all. When executed, the module produces a model that can be saved and used for creating a scoring workflow.
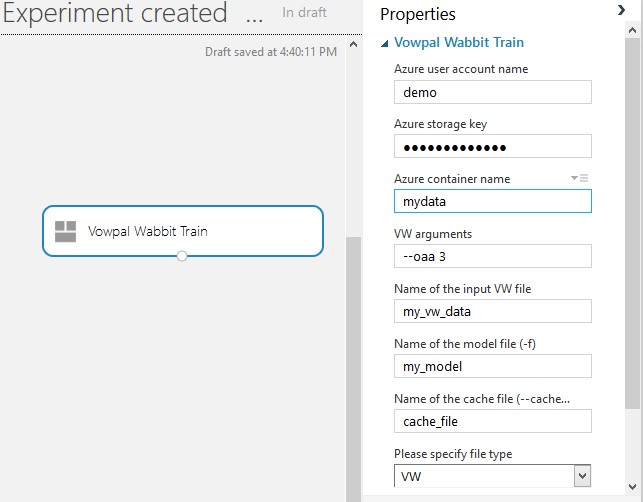
Figure 1. A sample training experiment using the Vowpal Wabbit Train module.
Figure 2 illustrates a sample experiment that scores a trained module produced by Vowpal Wabbit Train using data from any of the data ingress sources supported by Azure ML. The data to be scored must once again be in the VW text format and the scored outputs from VW are returned as an Azure ML dataset.
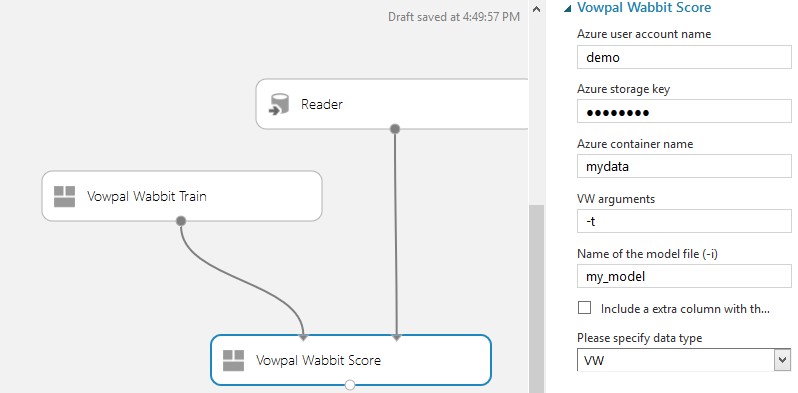
Figure 2. A sample experiment to train and score a model using VW.
Technical Details
Recognizing the importance of the features in VW and the potential for their use throughout the system, the Azure ML team invested in creating a rich C++/CLI wrapper around the underlying native APIs in VW. All functionality in VW (including ones that will be added in the future) can easily be called through our managed wrappers and exposed as modules in Azure ML or used by other parts of our ML infrastructure.
The Vowpal Wabbit Train module simply calls into the general-purpose VW wrapper. It downloads the training dataset in blocks from Azure (utilizing the high bandwidth between the worker roles executing the computations and the store) and streams it to the learners in VW. This strategy allows us to achieve training performance quite similar to what one might get from an on premise machine. The resulting model is generally very compact thanks to the internal compression done by VW and is copied back to the model store utilized by other models in Azure ML.
The Vowpal Wabbit Score model works in a similar manner. The only difference is that the data to be scored typically comes in through a client of the published web service as opposed to a user’s Azure storage.
Limitations and further work
As mentioned above, our wrapper modules are geared towards existing users of VW in order to enable them to easily on-board parts of their modeling workflow to Azure ML and take optimal advantage of the ability to publish and scale out web-services backed by ML models. The modules therefore expect the data to be in VW’s native text format (rather than the dataset representation used by other modules in Azure ML). Further, the training data is directly streamed into VW from Azure for maximal performance and minimal parsing overhead as opposed to other models in Azure ML that pre-process the data to handle missing values and different data types such as numeric, categorical, text, date-time, etc. Therefore, the interoperability between the VW-based modules and other modules in Azure ML is currently somewhat limited. Over the coming months, we intend to expose selective functionality in VW such as topic modeling in a more turnkey manner that consumes Azure ML datasets and interoperates seamlessly with other modules.
Conclusions
Tools such as VW provide a data scientist easy access to state-of-the art ML algorithms that can churn through massive amounts of training data in a short amount of time. However, turning the resulting models into operationalized scalable, reliable web services that can be used to drive business decisions remains a non-trivial problem. Azure ML reduces the process of publishing such web services to a few mouse clicks. The two new modules in Azure ML based on Vowpal Wabbit aim to give the data scientist the best of both worlds: the state-of-the art performance and functionality of VW plus the ease of operationalization of Azure ML.
I hope you have a chance to try these new modules out and give us feedback so we can continue to improve.
Sudarshan