Structured Streaming with Databricks into Power BI & Cosmos DB

 By Giuliano Rapoz, Cloud Solution Architect at Microsoft
By Giuliano Rapoz, Cloud Solution Architect at Microsoft
In this blog we’ll be building on the concept of Structured Streaming with Databricks and how it can be used in conjunction with Power BI and Cosmos DB enabling visualisation and advanced analytics of the ingested data.
We’ll build a data ingestion path directly using Azure Databricks, enabling us to stream data in near-real-time. We’ll show some of the analysis capabilities which can be called from directly within Databricks utilising the Text Analytics API, then we'll connect Databricks directly into Power BI for further analysis and reporting. As a final step we'll read and write from Databricks directly into CosmosDB as the persistent storage and further use. 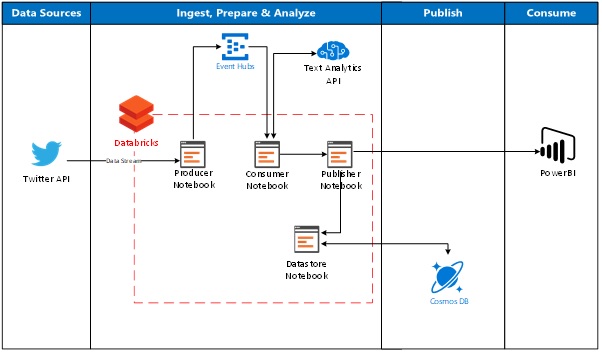
Figure 1: High-level architecture for real-time ingestion and processing of streaming data using Databricks, Cosmos DB and Power BI.
The first step is to get all our individual resources set up. We’ll need the following:
- A Databricks workspace and Apache spark cluster to run our notebooks.
- A Event Hub, for Databricks to send the data to.
- A Cognitive Services account to access the Text Analytics API.
- A Twitter application representing streaming of data.
- A CosmosDB Database as the persistent data store.
- Power BI Desktop for data visualization to visualise & analyse the data.
Event Hub
Firstly, create an Event Hub by searching for Event Hubs in Azure. In Create namespace, choose a namespace and select an Azure Subscription, resource group and location to create the resource.
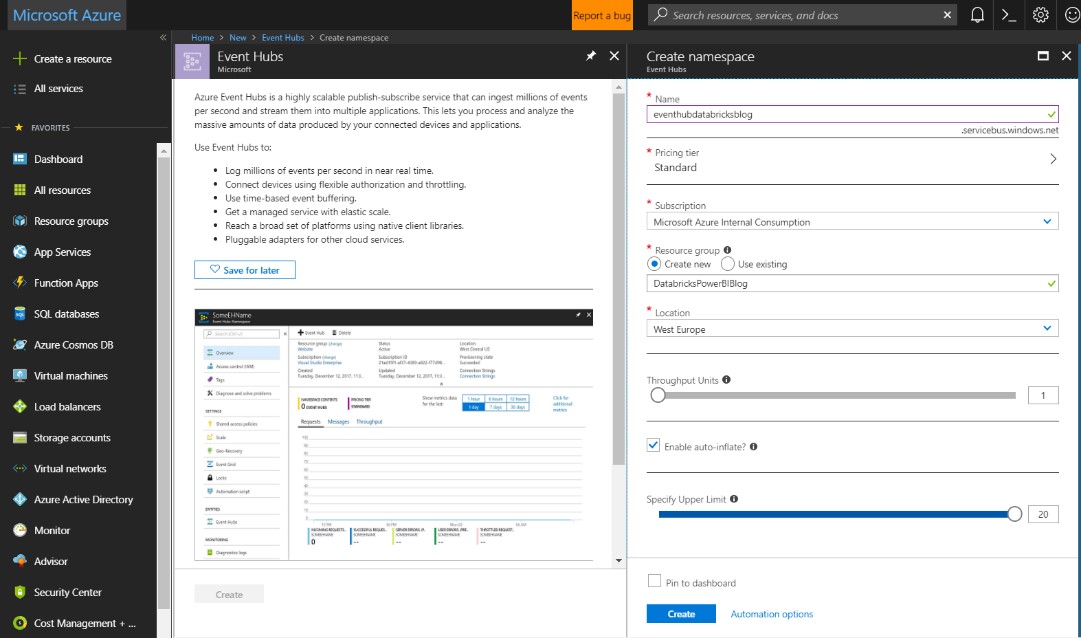
Figure 2: Event Hub configuration parameters.
Click Shared Access Policies and then on RootManagedSharedAccessKey. Take note of the connection string and primary key… you’ll need these later to allow Databricks send data to the Event Hub. 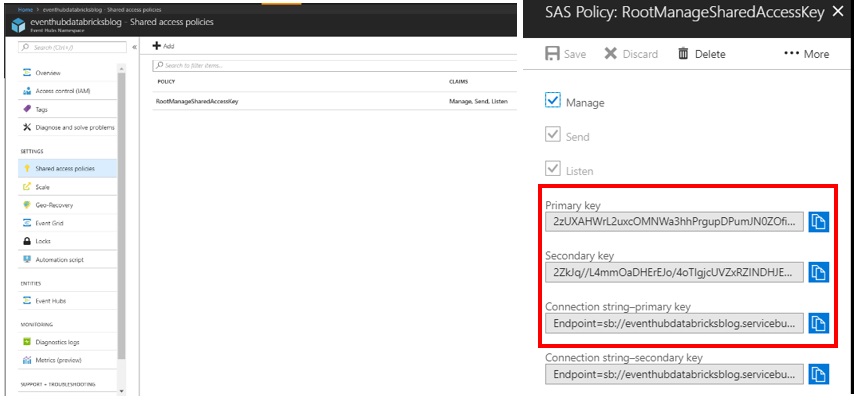
Figure 3: Event Hub Access Keys
Next, create an Event Hub via the namespace you just created. Click Event Hubs and then +Add Event Hub. Give it a name and then hit Create. 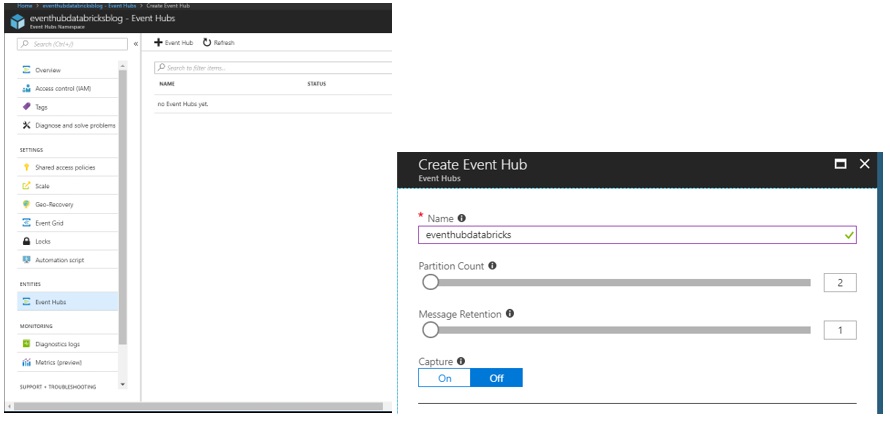
Figure 4: Creating the Event Hub in the Azure portal.
That’s it, the Event hub is ready to go, and we have all our connection strings required for Databricks to send data to!
Databricks Workspace
Now to create the Databricks workspace. Search Databricks using the Azure portal. Provide a workspace name, your existing resource group and location and Premium as the pricing tier - (Note: for connection via DirectQuery to Power BI you will need this!)
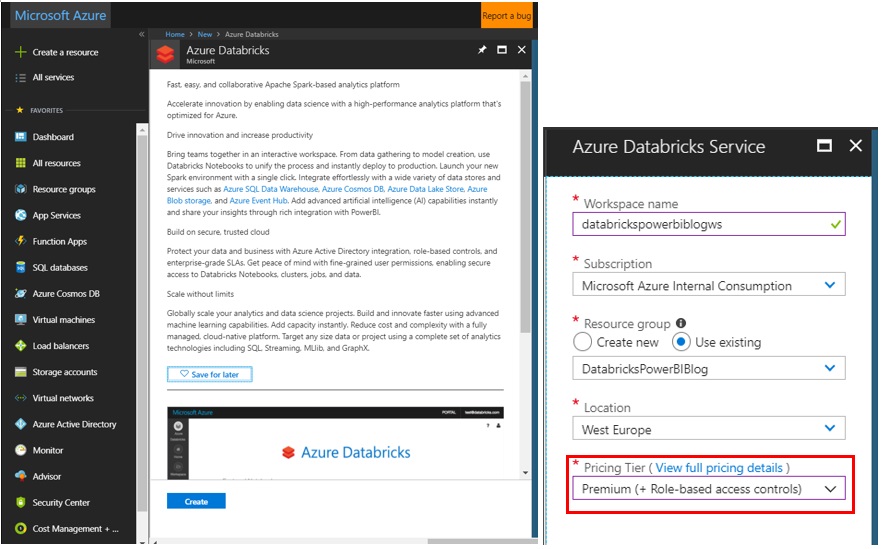
Figure 5: Azure Databricks Creation in Azure Portal
Create an Apache Spark Cluster within Databricks
To run notebooks to ingest the streaming data, first a cluster is required. To create an Apache Spark cluster within Databricks, Launch Workspace from the Databricks resource that was created. From within the Databricks portal, select Cluster.

Figure 6: Azure Databricks Workspace
In a new cluster provide the following values to create the cluster. NOTE! - For read/write capabilities to CosmosDB, a Apache Spark version of 2.2.0 is required. At time of writing 2.3.0 is not yet supported.
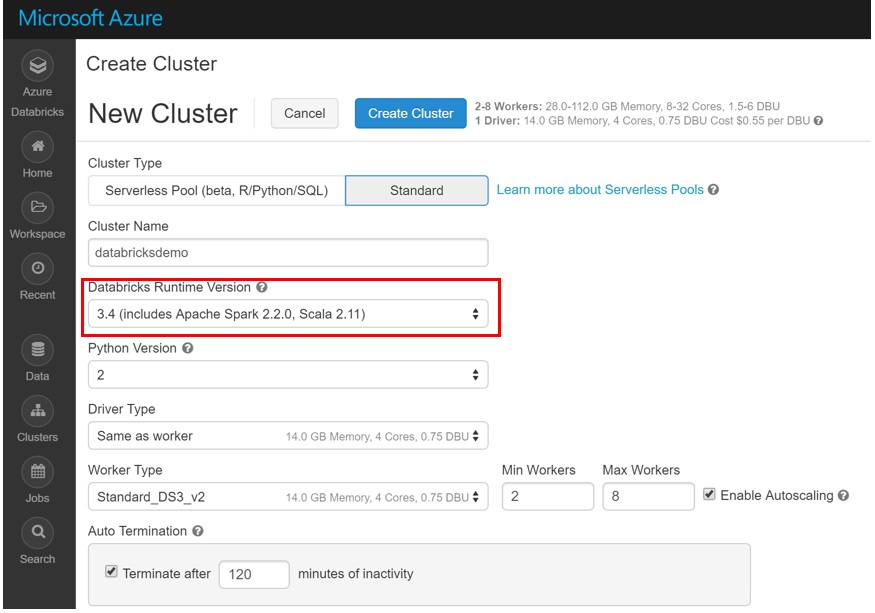
Figure 7: Selecting the Runtime Version and VM size in Azure Databricks cluster creation.
Get access to Twitter Data
To get access to a stream of tweets, first a Twitter application is required. Navigate to https://apps.twitter.com/, login, click on Create a new app and follow the instructions to create a new twitter application.

Figure 8: Twitter Application Management Overview.
Once complete, take note of the Keys and Access Tokens, the Consumer Key and the Consumer Secret. Also take note of the value from Create My Access Token, Access Token and Access Token Secret – these will be required to authenticate streaming of twitter data into the Databricks notebook. 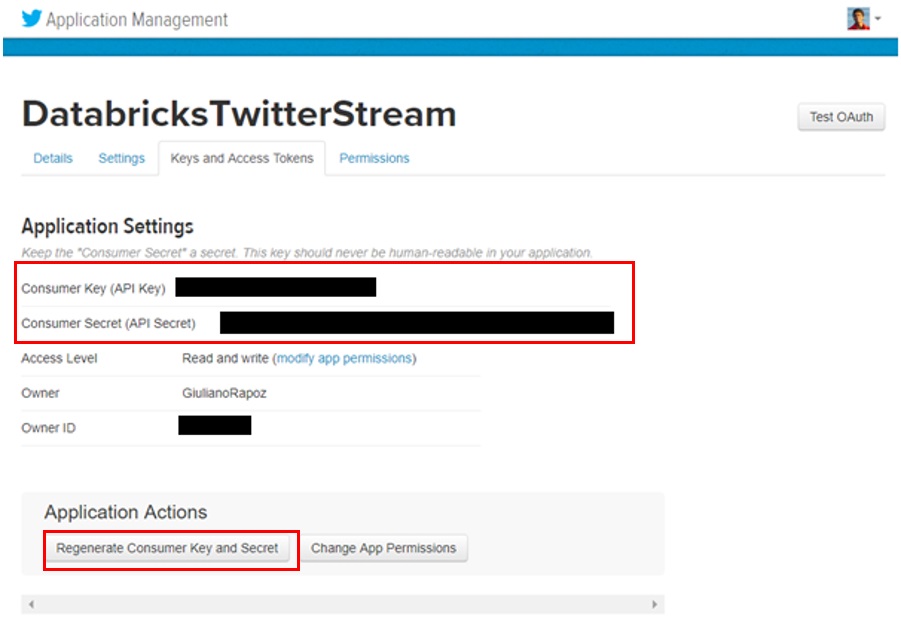
Figure 9: Twitter Application Consumer Key & Consumer Secret.
Attaching Libraries to Spark Cluster
To enable the Twitter API to send tweets into Databricks and Databricks to read and write data into Event Hubs and CosmosDB, three packages are required:
- Spark Event Hubs connector - com.microsoft.azure:azure-eventhubs-spark_2.11:2.3.1
- Twitter API - org.twitter4j:twitter4j-core:4.0.6
- CosmosDB Spark Connector: https://repo1.maven.org/maven2/com/microsoft/azure/azure-cosmosdb-spark_2.2.0_2.11/1.1.1/azure-cosmosdb-spark_2.2.0_2.11-1.1.1-uber.jar
Right click on the Databricks workspace and select Create > Library. From the New Library page, select Maven Coordinate and input the library names above. is maintained is located here: https://github.com/Azure/azure-cosmosdb-spark 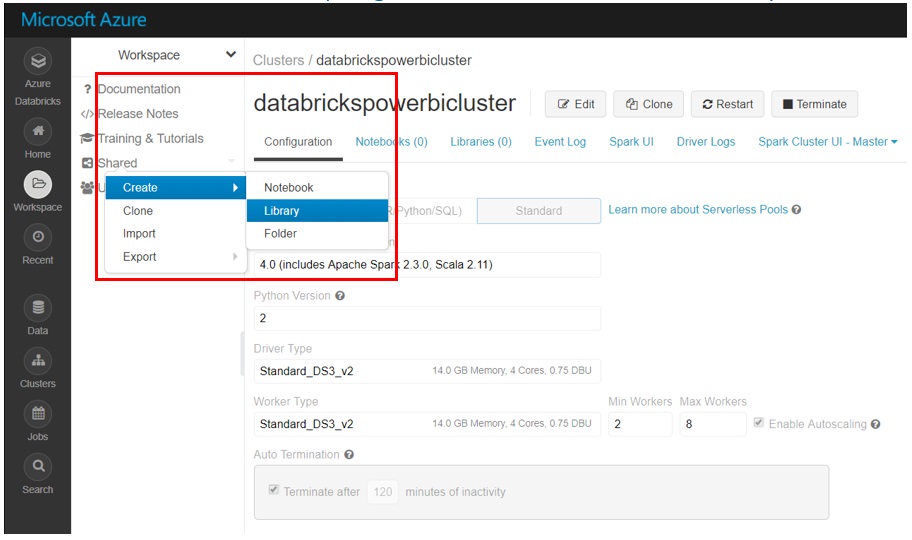
Figure 10: Creating Libraries in Azure Databricks workspace.
Click Create Library and then tick to attach the libraries to the cluster. For the CosmosDBSpark Connector, click this link to download the library and upload it to the cluster through JAR Upload option. Then attach it to the cluster in the same way. 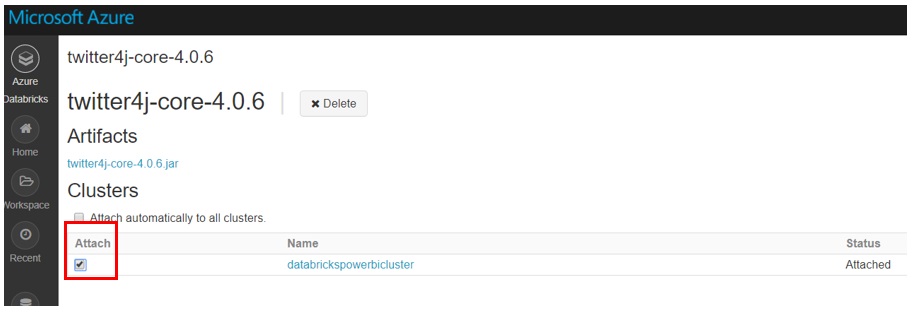
Figure 11: Attaching Libraries to clusters in the Azure Databricks workspace.
Cognitive Services Toolkit
To calculate the sentiment of the tweets, access to Microsoft’s Cognitive Services is required. This will allow Databricks to call the Text Analytics API in near-real time directly from within the notebook and calculate the sentiment for a given tweet.
Search for Text Analytics API in the Azure portal. Provide a name, location and pricing tier. (F0 will suffice for the purposes of this demo).
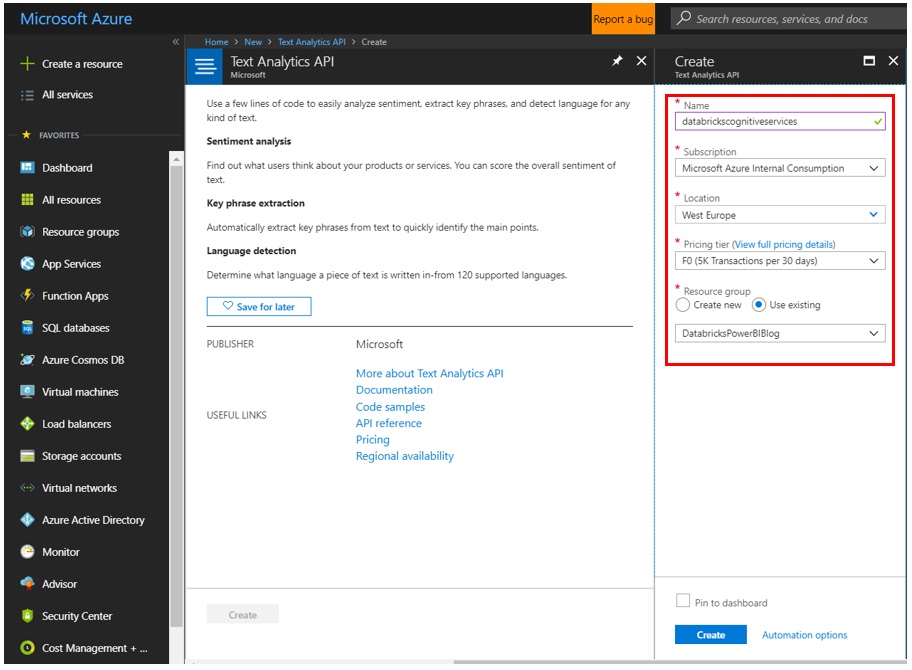
Figure 12: Configuring the Text Analytics API in the Azure Portal
Once created, click on Keys and take note of the Endpoint URL and Primary key to be used. These values will be required for Databricks to successfully call the Text Analytics API. 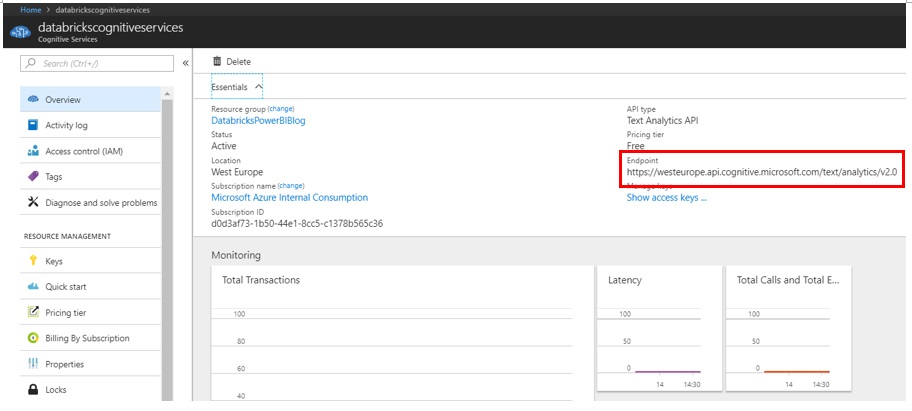
Figure 13: High-level architecture for real-time ingestion and processing of streaming data using Databricks, Cosmos DB and Power BI.
Optional: Create and Mount Blob Storage
Databricks automatically can save and write data to its internal file store. However, it is also possible to manually create a storage account and mount a blob store within that account directly to Databricks. If you wish to do this, simply create a new blob store within the Azure portal and reference the source via running the below mount command in a notebook with your storage account access keys.
1. dbutils.fs.mount(
2. source = "wasbs://YOURCONTAINERNAME@YOURSTORAGENAME.blob.core.windows.net/",
3. mountPoint = "/mnt/YOURCHOSENFILEPATH",
4. extraConfigs = Map("YOUR CONNECTION STRING"))
Create Databricks Notebooks
To execute the code, we’ll need to create 4 notebooks in the created Databricks workspace as follows:
- EventHubTweets (To send tweets to the event hub)
- TweetSentiment (To calculate sentiment from stream of tweets from event hub)
- ScheduledDatasetCreation (To create and continuously update the dataset)
- DatasetValidation (To validate the dataset directly within Databricks)
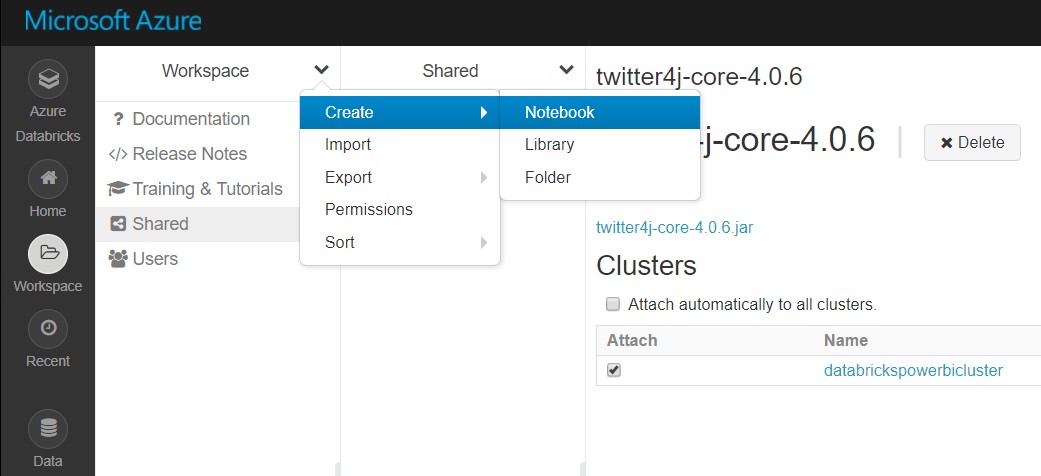
Figure 14: Creating a new Notebook in the Azure Databricks workspace
In the EventHubTweets notebook, add the following code located in GitHub which passes in connection to the EventHub, streams the tweets from Twitter API for a given keyword (#Microsoft in this instance) and sends them into the EventHub in near-real time.
From running the notebook, it is shown directly in Databricks, printed out to the console the stream of tweets coming in based on the keyword set.
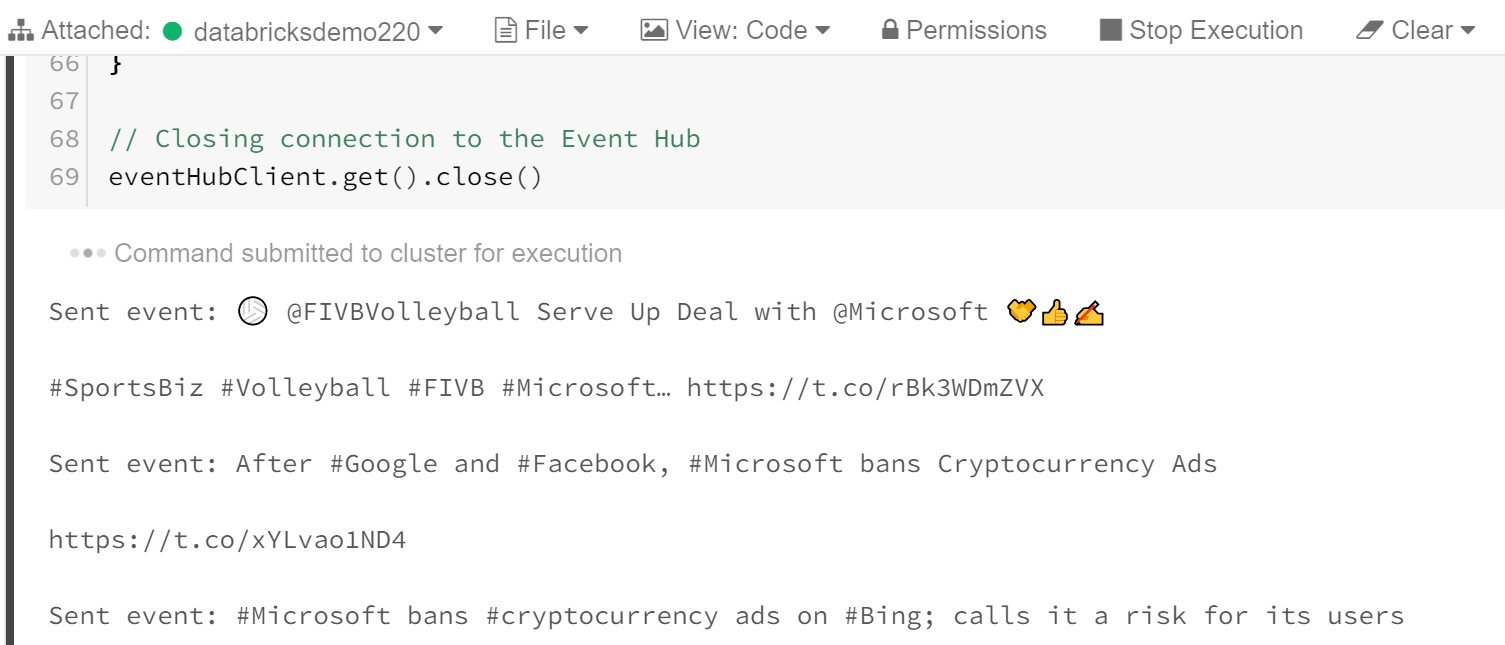
Figure 15: Output of running Notebook stream: Tweets being sent to the Event Hub.
The next step is to take this stream of tweets and apply sentiment analysis to it. The following cells of code read from the EventHub, call the Text Analytics API and pass the body of the tweet in order for the Sentiment to be calculated.
Get Sentiment of Tweets
In the TweetSentiment notebook add the following cells of code to call the Text Analytics API to calculate the sentiment of the Twitter stream.
As an output from this stream, a flow of data (dependant on your Twitter search criteria) should be visible as follows:
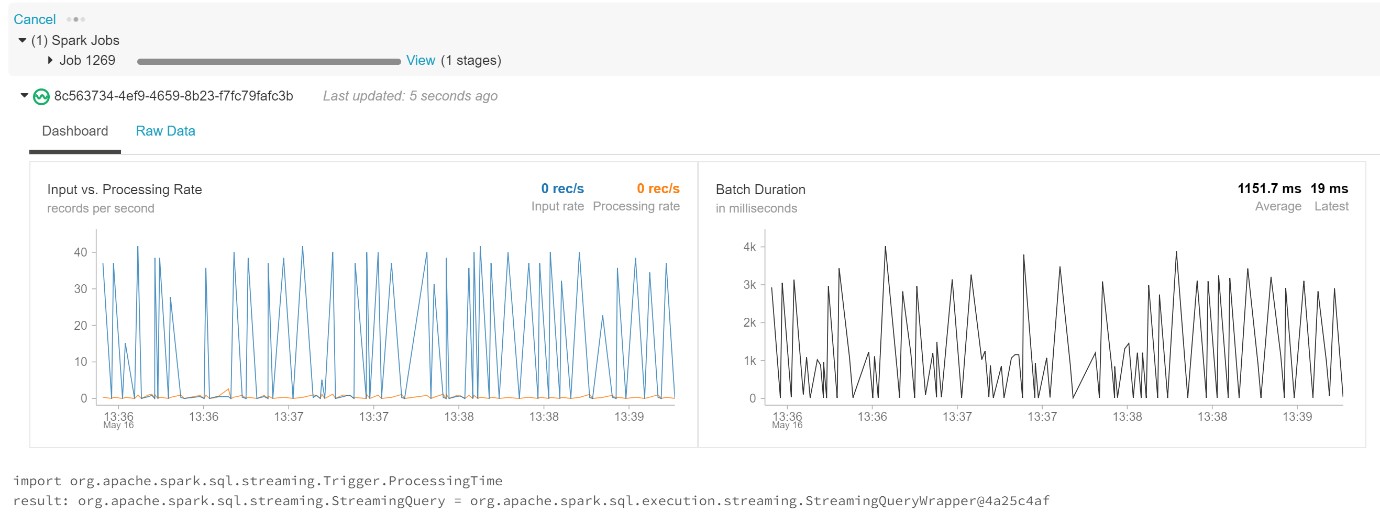
Figure 16: Databricks visualisation of the streaming tweets as the sentiment is applied to the tweet body.
Create Data Table for Power BI to connect to
First, we need to write data as parquet format into the blob storage passing in the path of our mounted blob storage.
1. //WRITE THE STREAM TO PARQUET FORMAT/////
2. import org.apache.spark.sql.streaming.Trigger.ProcessingTime
3. val result = streamingDataFrame
4. .writeStream
5. .format("parquet")
6. .option("path", "/mnt/DatabricksSentimentPowerBI")
7. .option("checkpointLocation", "/mnt/sample/check2")
8. .start()
To verify that data is being written to the mounted blob storage directly from within the Databricks notebook, create a new notebook DatasetValidation and run the following commands to display the contents of the parquet files directly within Databricks. If data is being written correctly an output when querying the table in Databricks should look similar as below. 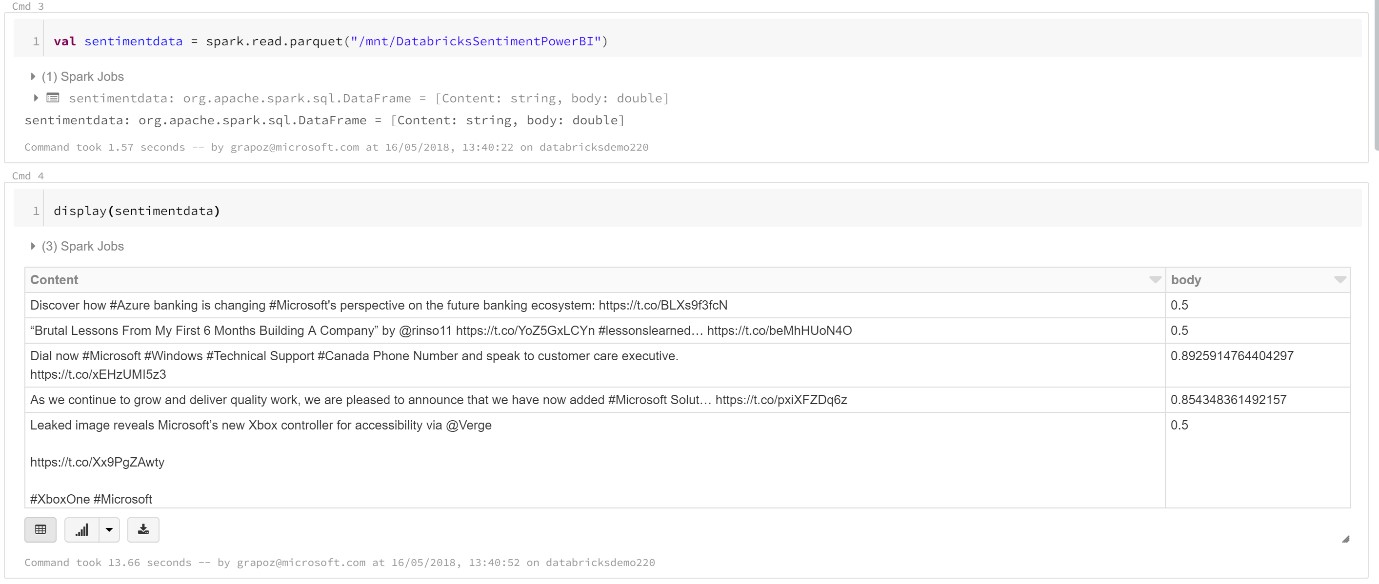
Figure 17: Reading the Parquet files and verifying that data is being written correctly into storage.
We now have streaming Twitter data with the attached sentiment flowing into a mounted blob storage. The next step is to connect Databricks (and this dataset) directly into Power BI for further analysis and data dissection. To do this, we need to write the parquet files into a dataset which Power BI will be able to read successfully at regular intervals (i.e. Continiously refresh the dataset at specified intervals for the batch flow of data). To do this, create the final notebook ScheduledDatasetCreation and run the following scala command set as a schedule to run every minute. (This will update the created table every 1 minute with the stream of data).
1. spark.read.parquet("/mnt/DatabricksSentimentPowerBI").write.mode(SaveMode.Overwrite) saveAsTable("twitter_dataset")
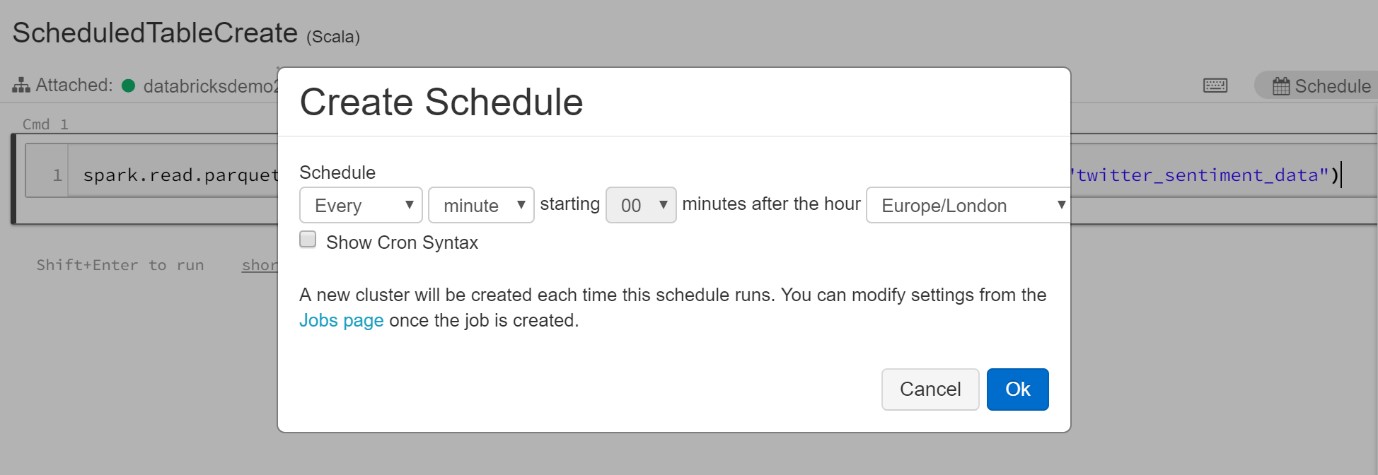
Figure 18: Creating a schedule to run the notebook at set intervals to write the data to a table format.
Connect Power BI to Databricks Cluster
To enable Power BI to connect to Databricks first the clusters JDBC connection information is required to be provided as a server address for the Power BI connection. To obtain this, navigate to the cluster within Databricks and select the cluster to be connected. On the cluster page, select the JDBC/ODBC tab (Note: If you did not create a Premium Databricks workspace, this option will not be available).
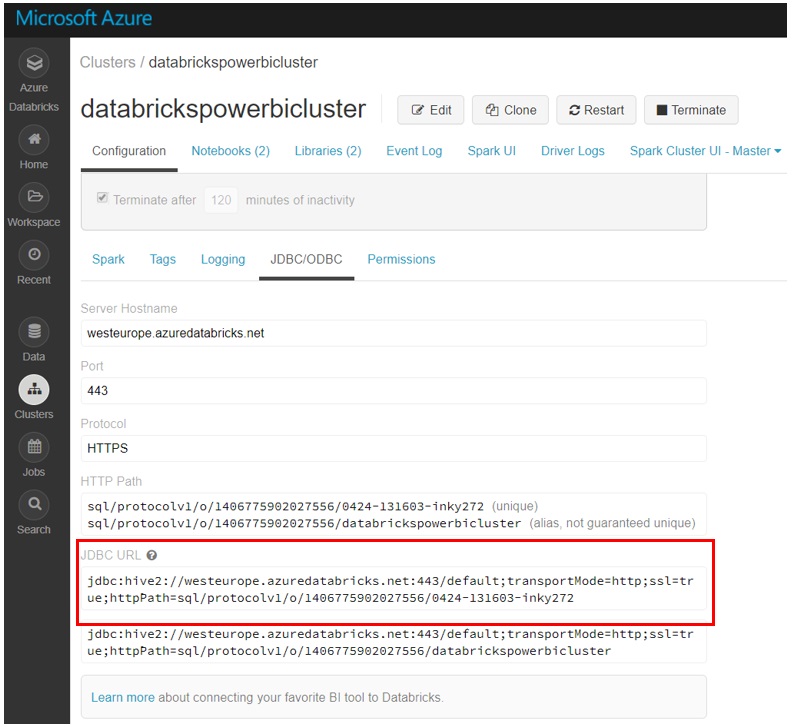
Figure 19: JDBC Connection string for PowerBI connector within Azure Databricks Cluster configuration.
To construct the server address, take the JDBC URL displayed in the cluster and do the following:
- Replace jdbc:hive2 with https.
- Remove everything in the path between the port number and sql retaining the components so that you have a url which looks like the following: https://westeurope.azuredatabricks.net:443/sql/protocolv1/o/1406775902027556/0424-131603-inky272
To generate the personal access token, select User Settings from the cluster dashboard.
Figure 20: Navigating to the Azure Databricks User Settings.
Click on Generate New Token to provide an access token for Power BI to use for the Databricks cluster. Note: This is the only time the token will be visible, so be sure to write it down.
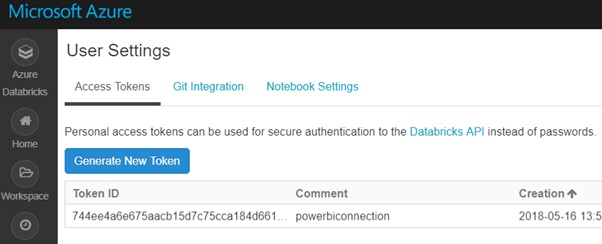
Figure 21: Obtaining the access token to pass into Power BI from the Azure Databricks User settings.
Configure the Power BI connection
The final step is to connect Databricks to Power BI to enable the flow of batch data and carry out analysis. To do this, open Power BI Desktop and click on Get Data. Select Spark(beta) to begin configuring the Databricks cluster connection.
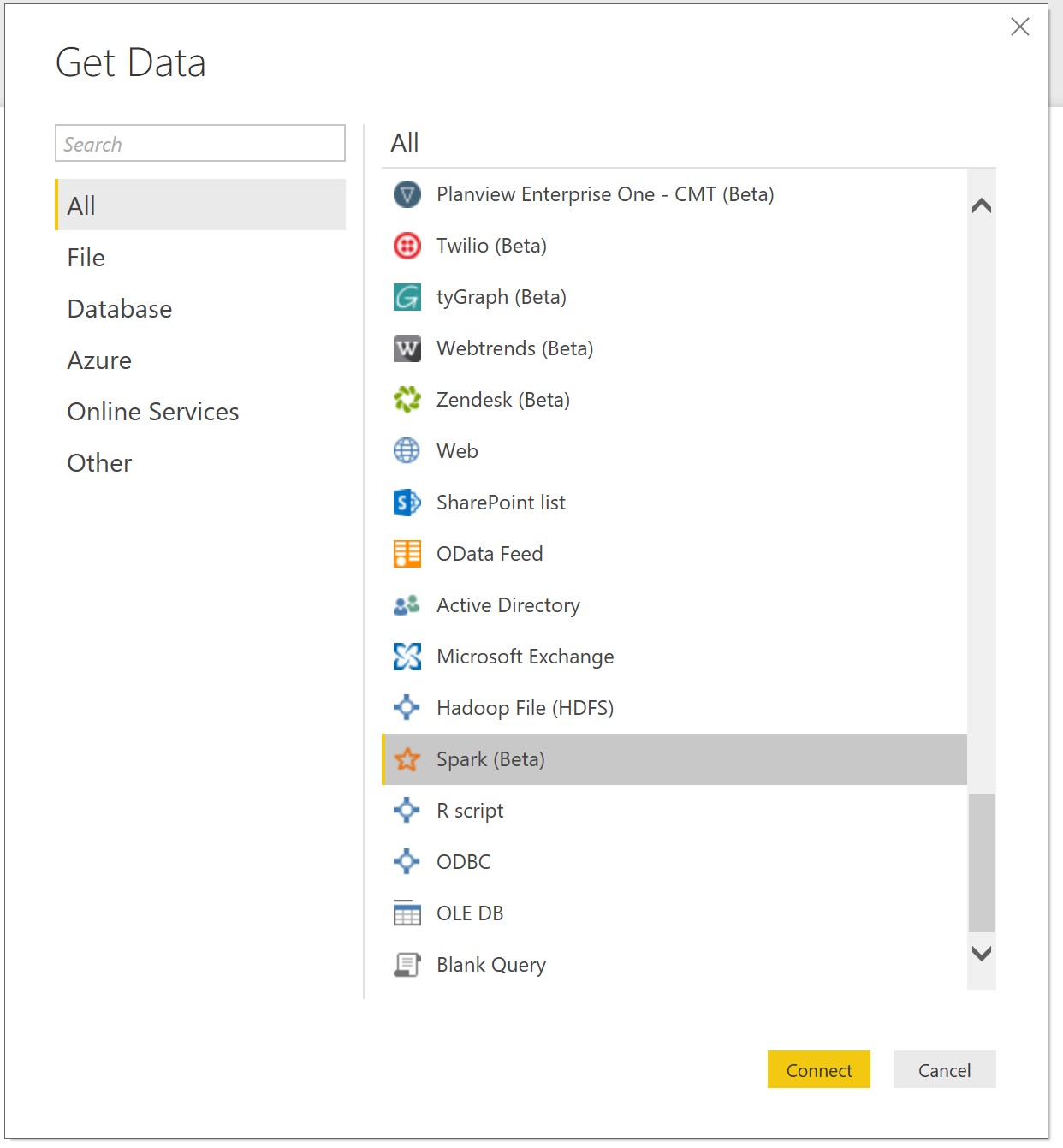
Figure 22: Selecting the Spark connector from Power BI’s desktop list of Get Data options.
Enter the server address created earlier from the Databricks cluster string. Select HTTP connection protocol and DirectQuery which will offload processing to Spark.
This is ideal when working with a large volume of data or when near-real-time analysis is required.
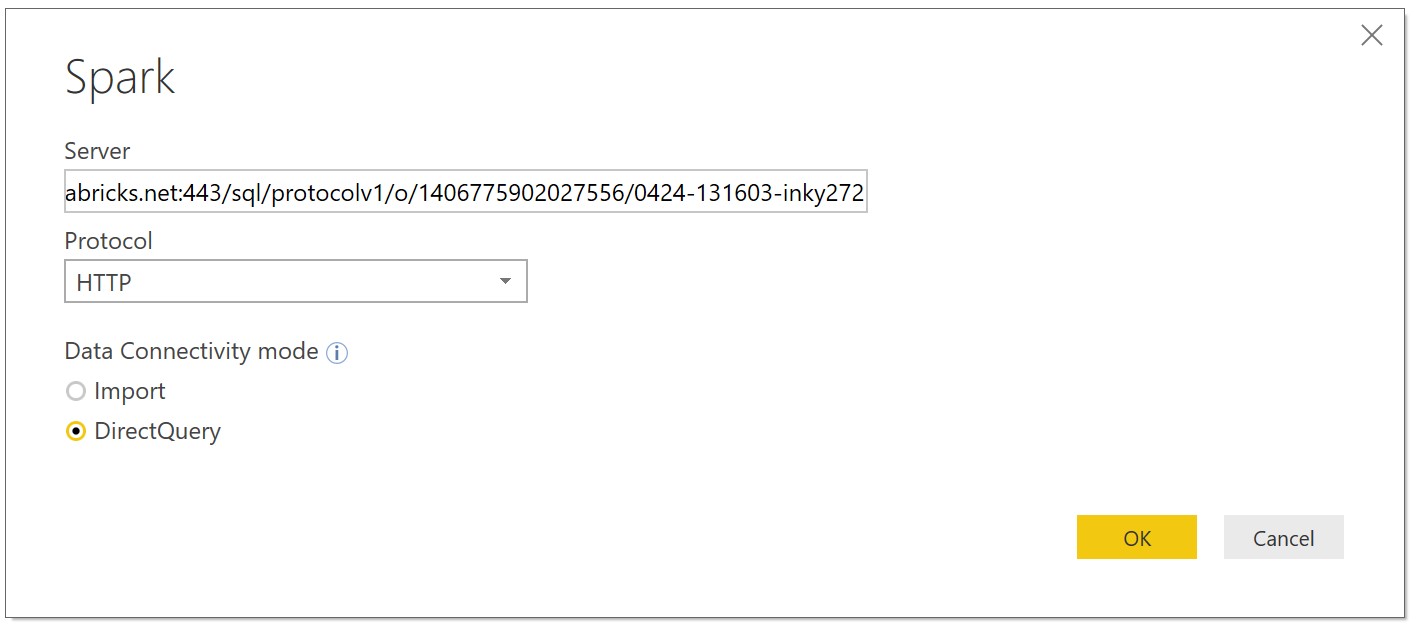
Figure 23: Inputting the server details and selecting the connectivity mode for Azure Databricks and Power BI
On the next screen, enter token as the username field and the personal access token from Databricks. 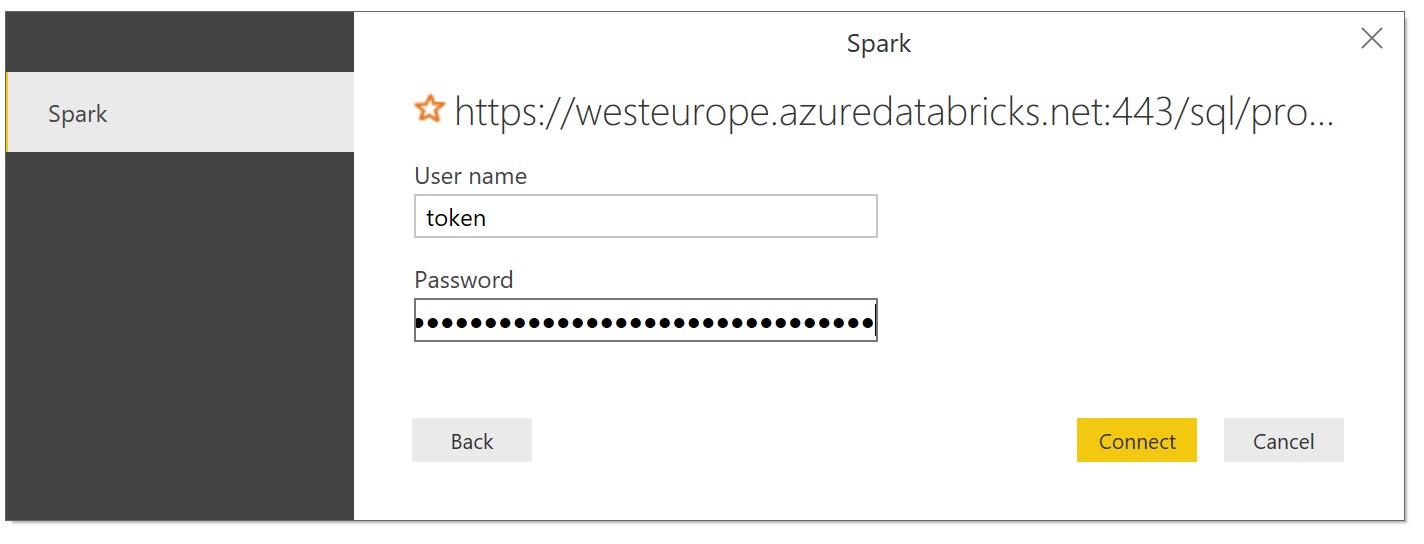
Figure 24: Passing in the token and password value into Power BI.
Once Power BI is connected to the Databricks cluster the dataset should be available to view through the built in Navigator like follows: 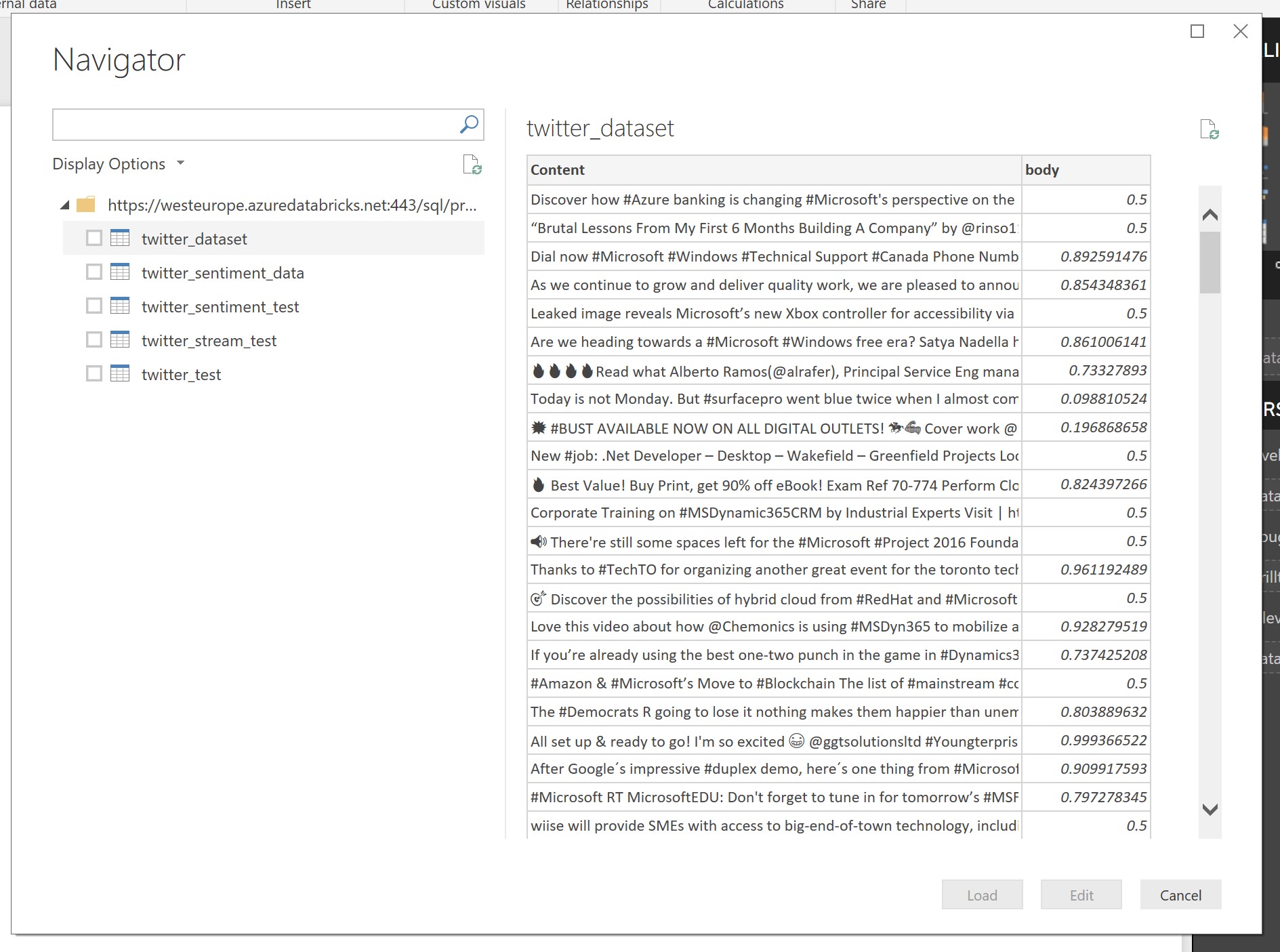
Figure 25: Power BI Navigator displaying the loaded table data from Azure Databricks containing the Tweets and assigned sentiment.
From here its possible to drill down into the data, apply data dissection and manipulation for more insights. The dataset will be refreshed based on the schedule defined from within the Databricks notebook. That’s it! You have successfully ingested a streaming dataset in a structured format into Databricks, applied sentiment analysis directly from within a Databricks spark notebook calling the Cognitive Services API and outputted the data in near real-time as a batch view to Power BI! 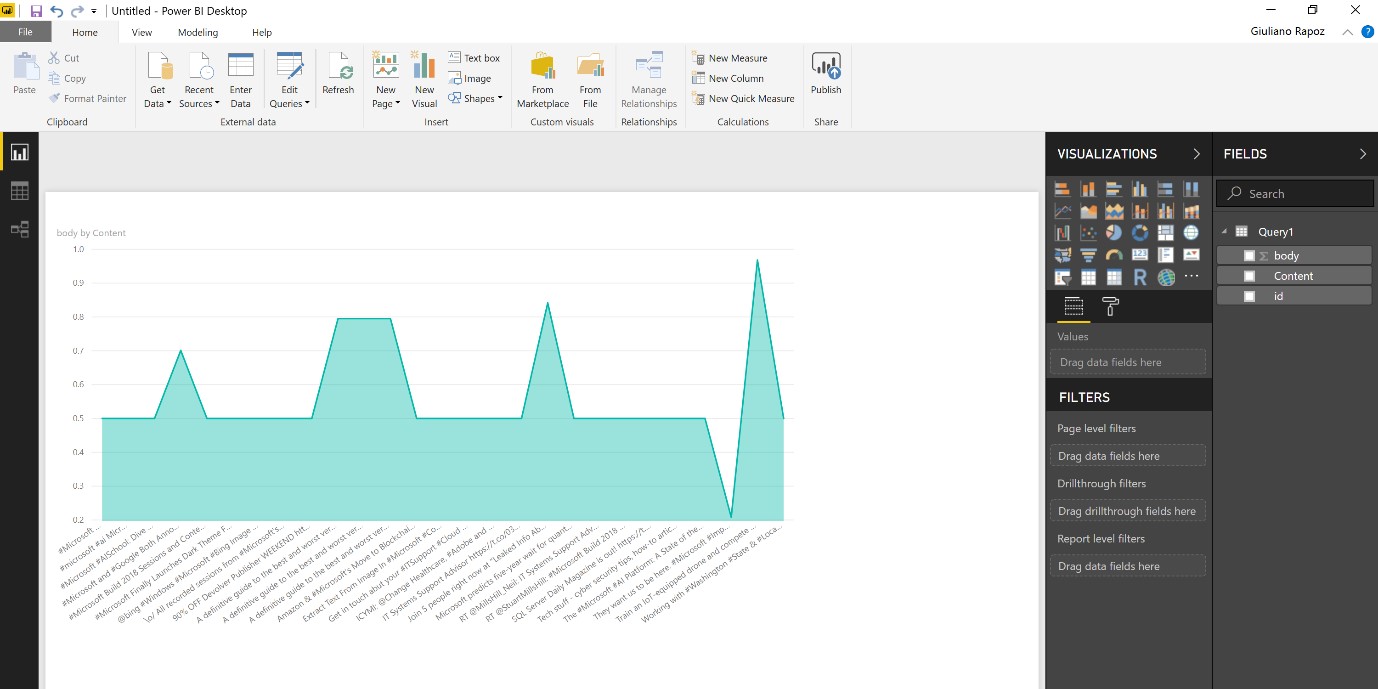
Figure 26: Visualising the Twitter Sentiment data within Power BI
Create CosmosDB Storage
If we wanted to write to a completely persistent data store, we can do so by getting Databricks to write to Cosmos DB. You could also To do this, first create a CosmosDB Data Store in the Azure portal. Note, Azure Databricks also supports the following Azure data sources: Azure Data Lake Store, Azure Blob Storage, and Azure SQL Data Warehouse.
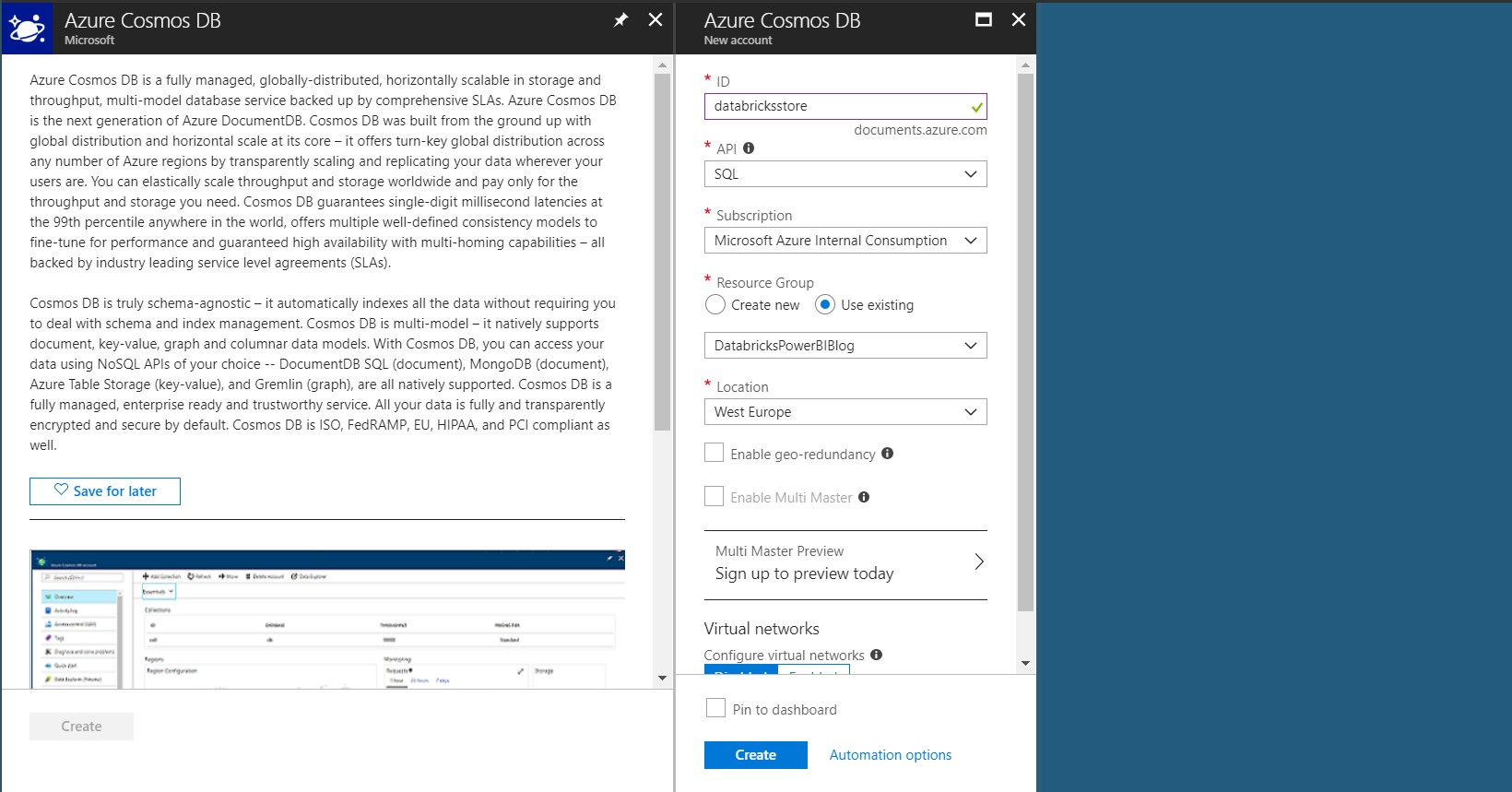
Figure 27: Azure CosmosDB configuration in Azure Portal.
Configure a new database and collection. For this demo, we don’t need a limit greater than 10GB so there is no need for a partition key. Take note of the Endpoint name, Master key, Database name, Collection Name and Region. These values will need to be passed into the Databricks notebook to enable the reading and writing of the Twitter data. 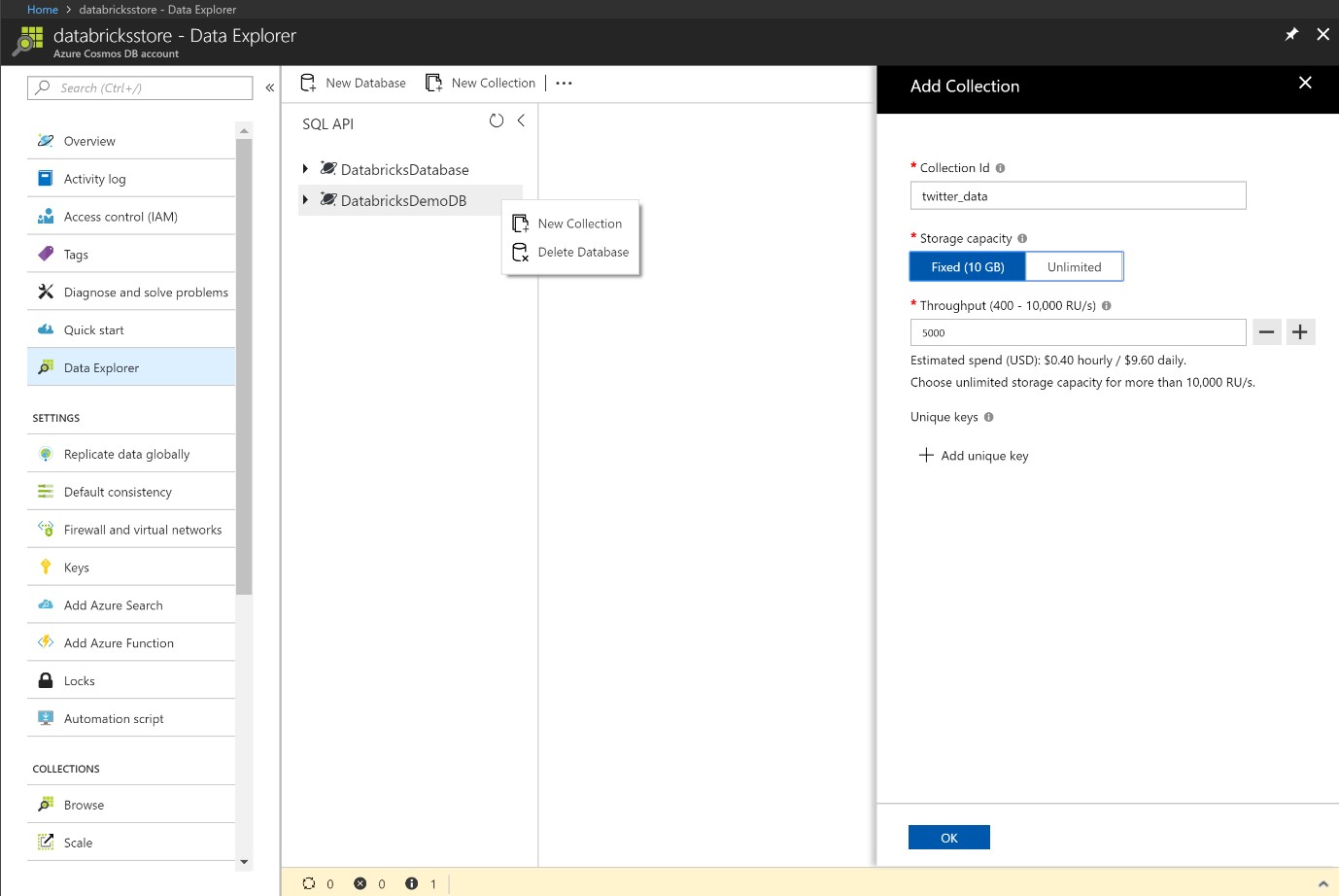
Figure 28: Creating a new Database within CosmosDB and a new Collection.
Create a new notebook named CosmosDBReadWrite and input the following code with the CosmosDB connection parameters and hit run. Again, this can be scheduled to write data to CosmosDB data store at regular intervals for an updated dataset.
1. ///////////////WRITE TO COSMOS DB////////////////////
2. import org.joda.time._
3. import org.joda.time.format._
4. import com.microsoft.azure.cosmosdb.spark.schema._
5. import com.microsoft.azure.cosmosdb.spark.CosmosDBSpark
6. import com.microsoft.azure.cosmosdb.spark.config.Config
7. import org.codehaus.jackson.map.ObjectMapper
8. import org.apache.spark.sql.functions._
9. import scala.collection.immutable.Map //Write to CosmosDB // Configure connection to the sink collection
10. val writeConfig = Config(Map("Endpoint" - > "YOUR COSMOS DB ENDPOINT",
11. "Masterkey" - > "YOUR COSMOS DB KEY",
12. "Database" - > "YOUR COSMOS DB DATABASE",
13. "PreferredRegions" - > "West Europe;",
14. "Collection" - > "YOUR COLLECTION NAME", "WritingBatchSize" - > "100")) val sentimentdata = spark.read.parquet("/mnt/LOCATION OF DATAPATH IN DATABRICKS") // Upsert the dataframe to Cosmos DB
15. import org.apache.spark.sql.SaveMode YOURTABLENAME.write.mode(SaveMode.Overwrite).cosmosDB(writeConfig)
To verify that the job has completed successfully navigate to the Azure portal and open up the Data Explorer within the CosmosDB instance. Hit refresh and the streaming Twitter data should be visible as follows: 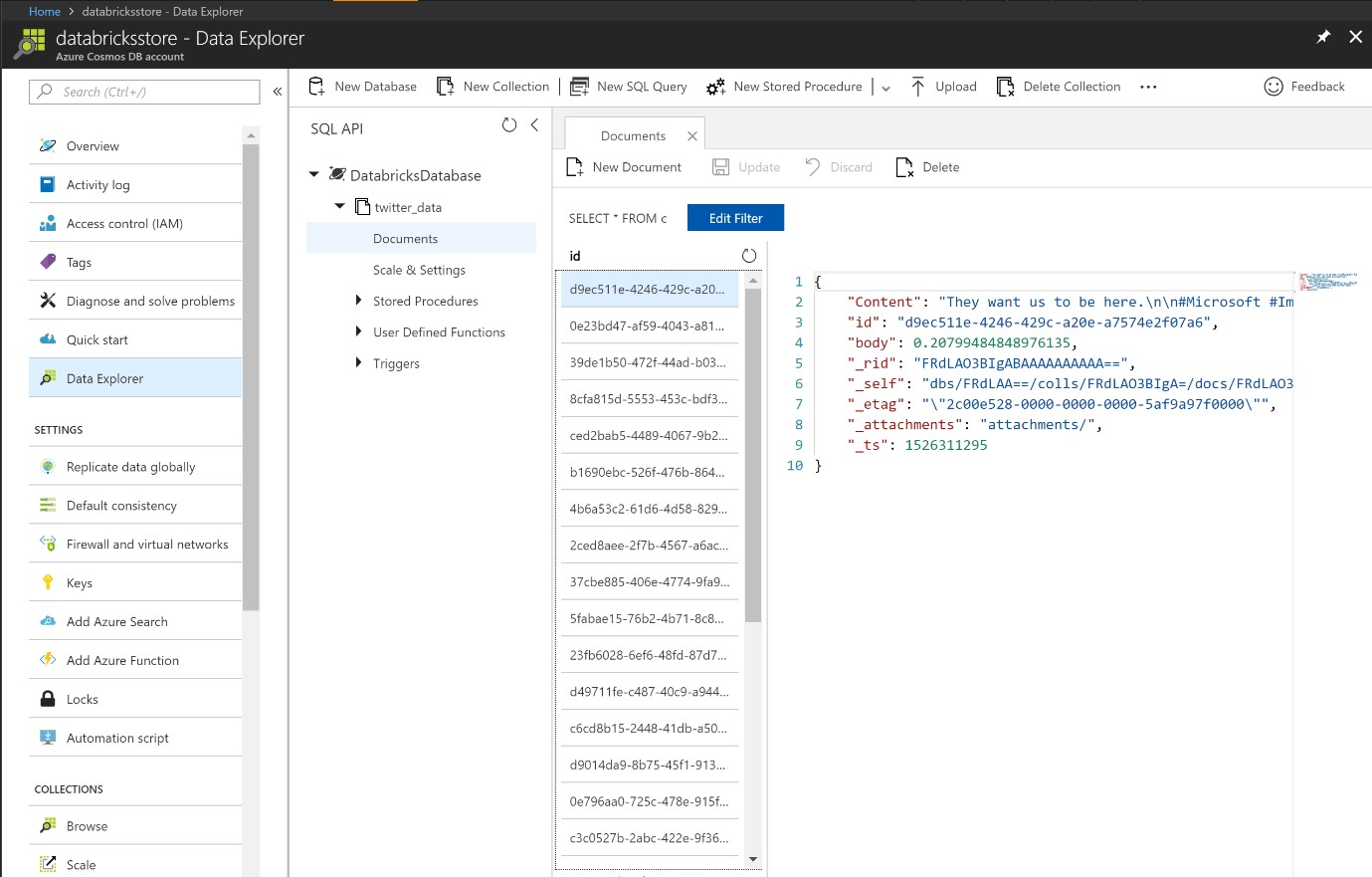
Figure 29: Exploring the streamed data within the CosmosDB store.
There are various steps you can take this data from here, but there you have it. A persistent data store of the Stream of Tweets with the calculated sentiment!
For more examples of Databricks see the official Azure documentation located here:
- Perform ETL operations in Databricks
- Structured Streaming in Databricks
- Stream Data from HDInsight Kafka
To read more on Stream Analytics with Power BI, go here.