Cutting Edge
DataSets vs. Collections
Dino Esposito
Contents
Where's the Problem?
DataSet—The Good Side
DataSet—The Dark Side
Typed DataSet—Good and Bad
Custom Entities and Collections
Make Your Choice
When to Use Which
Wrap Up
In software, five years is like a geological era. Five years ago, the Microsoft® .NET Framework had just been announced. Since then, the DataSet has emerged as the key object for performing a variety of data-related tasks in .NET-based applications. Five years ago, the DataSet was hailed as a greatly enhanced version of the ADO Recordset. How would you have designed a data access layer (DAL) before the advent of the .NET Framework? I'm sure you would have built it around ADO and its almighty Recordset object, which was disconnected and XML-serializable.
Few developers were employing custom collections, implementing a true object-oriented programming model, or pursuing strongly typed data access at a time when object-oriented programming was either a feature for a few C++ programmers or an advanced trick for the brave developer using Visual Basic®.
Fortunately there are now better options for building an enterprise system back-end, but you still have to choose the right approach for the job. Let's explore how you can best make the decision.
Where's the Problem?
Imagine you need to architect a multitier, distributed .NET-based app with three logical layers—presentation and interface services, business logic with core functionalities, and data access, where all database stuff and messaging happens. For this type of app, layering is the key. If the lowest layer could be completely ignorant of the upper layers, the system would be nearly perfect.
When designing a layered system you must consider factors such as the ability to cascade changes (such as new data schemas) through layers and the amount of overhead involved when data is moved from one layer to the next. Plus you need a business tier to execute your business logic, and you need a DAL to provide Create/Read/Update/Delete (CRUD) functions to the rest of the system. There are two primary ways to provide this functionality—by using a commercial Object/Relational (O/R) mapping tool or by rolling your own DAL.
An O/R mapper works by mapping custom objects to entities into a relational database. Through an XML file or any other form of a settings container, the tool shields you from relying on any knowledge of the underlying database. You work with domain-specific objects provided to you by the mapper. On the opposite end of the spectrum is the other more common approach, building your own DAL. Here your primary problem is making a decision about the mechanism used to pass data around.
All things considered, I'd say that four options are worth spending some time on: DataSets, typed DataSets, custom collections, and plain XML. Using plain XML text is the least attractive option even though it provides full integration with any other platform. It is weakly typed, hard to maintain, performs poorly, and is not a powerful programming interface in the context of an enterprise app. Now let's review the pros and cons of the other three options.
DataSet—The Good Side
Frankly, writing data access code is rarely fun. In fact, it's frequently boring and tedious, and it requires you to think relationally. So when Microsoft introduced the DataSet with the first version of the .NET Framework everybody looked at the new API with great interest because the DataSet and its companion classes were more intuitive. In addition, there are lots of wizards and designers in and around Visual Studio® .NET to generate code and inject it directly into source files.
The DataSet is designed to be a general-purpose container of any information that can be expressed in a tabular format—a container of relational information like that resulting from a database query. The DataSet looks and behaves like an in-memory database. However, it has no notion of connection strings, commands, stored procedures, hosts, and logins. It is purely a container class that stores tables of data and allows relations to be defined between pairs of contained tables, which in turn can include constraints, build indexes, and perform data retrieval and filter operations. It also supports the concept of computed expression columns in tables.
The DataSet was not specifically designed to work with databases, but it does fit well into a pure database scenario. The DataSet was designed to be a datacentric container which you can populate with tabular data from virtually any source—the file system, memory, real-time devices and, of course, database queries.
ADO.NET provides a family of objects that bridge DataSets to databases in an intelligent way. These objects are known as data adapters. By calling methods on a data adapter, you can execute database commands using the contents of the DataSet as the input (batch update) or as the output stream. However, regardless of the .NET Framework facilities for connecting DataSets and databases, the DataSet class remains a datacentric object with a database-oriented programming model.
With a DataSet object you can easily pack and transmit any sort of data and combine interrelated data from different sources and tables. In addition, the DataSet is serializable, has integrated XML capabilities, has built-in support for optimistic concurrency, and the ability to define and handle complex relationships between contained tables. By using the DataSet to represent data, you don't need to change anything in your DAL API should the database schema change. Using a DataSet also allows you to take advantage of data binding in both Web Forms and Windows® Forms.
If you think of your application design with a SQL Server™ or ADO.NET mindset, opting for the DataSet is a natural choice, and probably the only one you would ever think of.
DataSet—The Dark Side
In light of the favorable characteristics of the DataSet, using it in enterprise applications is definitely a reasonable choice, but consider the drawbacks before you make a final decision. Sometimes strengths can also be weaknesses. Take serialization and deserialization, for example.
The DataSet implements a serialization algorithm that performs less than optimally as the DataSet grows to thousands of rows. In the .NET Framework 1.x, the DataSet serializes itself to XML, resulting in a verbose data stream padded with schema information. The serialization algorithm has been radically improved in the .NET Framework 2.0, as I discussed in the October 2004 installment of Cutting Edge (Cutting Edge: Binary Serialization of DataSets). In this new version, the DataSet serialization can take place through a full binary stream, thus saving serious bandwidth. Additionally, typed DataSet serialization can be further optimized by setting the type DataSet.SchemaSerializationMode property to SchemaSerializationMode.ExcludeSchema. When this option is set, the serialized payload does not contain schema information, resulting in a smaller payload.
Figure 1 compares times for the classic XML-driven approach with a true binary serialization approach. As you can see, as long as the number of rows remains in the hundreds, the two approaches don't differ significantly in speed. When the row count enters the thousands, however, the gap grows significantly.
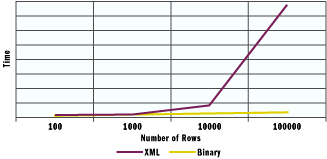
Figure 1** Remoting End-to-End Time **
Aside from serialization, the most significant problem with the DataSet is that it is too generic and too polymorphic a container, and it transfers this trait to the system architecture you're planning. DataSets don't represent data; they just contain it.
Here's the problem. Representing data means that the object exposes a programming interface to describe a given entity. The interface models the characteristics and attributes of the entity and provides methods to implement the expected behavior. Containing data means that the object incorporates all the attributes of a given entity, but can't provide any specific additional behavior. In complex scenarios, where you need to employ smarter objects with their own behavior that are fully representative of business entities, the DataSet is simply the wrong tool. It's the proverbial hammer that makes everything look like a nail.
As a general-purpose, serializable, disconnected data container, the DataSet is at home in the .NET Framework where it can serve in a variety of realistic scenarios. Having a DataSet class in the .NET Framework makes a lot of sense; having DataSets at work in a complex enterprise application with articulated business logic and interoperating entities may not.
Does this mean that the DataSet doesn't belong in any multitier system? No. Functionally speaking, using the DataSet doesn't limit your programming power. However, if your system is rich in interoperating business entities, there might be more effective tools that you can use for the job.
Finally, because DataSets contain data but don't represent business entities, you need additional components to manipulate DataSets and you are forced to embrace a database-oriented programming model. This is not necessarily bad as long as it's your decision and you're not forced into it unwittingly by wizards and IDEs.
Other considerations apply if the architecture includes Web services. DataSets should not be used with Web services or, at least, they should not be the sole possible return value of a Web method. You should use Web method overloading (each overload of the same functionality with its own exposed name) and return the same data in other simpler formats. The polymorphic nature (and inherent complexity) of DataSets often confuses any client that is not part of .NET and also violates at least one of the four service-oriented architecture (SOA) tenets—autonomy of the (Web) services.
Typed DataSet—Good and Bad
Aware of the logical limitations of the DataSet object, Microsoft also introduced the typed DataSet—a class that derives from DataSet and inherits all the members of a DataSet. In addition, a typed DataSet provides strongly typed members to access tables and columns by name, instead of using generic collection-based methods. This is beneficial for at least two reasons. First, it improves the overall readability of the code and provides significant help from the Visual Studio 2005 IDE through IntelliSense® and automatic code completion. Second, typed DataSets let you distinguish one table from the next using different objects to render each. Table Employees, for example, will be a different object from table Customers. In this way, type mismatch errors are caught at compile time rather than during execution.
Typed DataSets are still data containers, they're just a bit less generic and have a little more information about the data they contain. They can still hold any data, but you get some specialized members to speed up any work you need to do on a few particular types of data.
Typed DataSets include the same serialization algorithm as DataSets, but because they're derived classes it's easier to extend them further with manually written code to improve the serialization mechanism. For example, your typed DataSet can reimplement the ISerializable interface to reduce or compress the amount of data being moved if you find out that in the particular context in which it operates the XML-based serialization algorithm is too heavy. Speaking of this, let me add a brief remark. As Figure 1 shows, the XML algorithm performance is not so bad when you're moving only a few hundred rows. Sure, each system has its own size and data, but if you realize you're moving thousands of rows across the layers, spend some time making sure you're doing it right. It might be that a proper refactoring would reduce the need to transfer large DataSets from tier to tier too frequently.
A typed DataSet is automatically generated from an XML Schema Definition (XSD) schema file to give DataSet elements friendly names without altering the underlying schema. They have the same advantages of DataSets and they partially remedy the inherent "container" nature of DataSets by adding more specific members oriented to better represent real entities that are active in the domain of the system.
Another advantage of typed DataSets is their support for annotations. Using annotations, you can change the names of contained objects to more meaningful names without changing the underlying schema, making code easier for clients to use. To some extent this is possible with the DataSet, but it comes at the cost of modifying the queries or stored procedures to add T-SQL AS clauses. Annotations build a customized facade atop the resultsets that you get from the database.
Annotations can also be used to easily handle NULL values in DALs powered by the .NET Framework 1.x. Annotations allow you to define the value that a field will return if its actual value is NULL. Note, though, that the problem of dealing with NULLs is more general and can't be entirely avoided or delegated to built-in solutions. Annotations provide an interesting declarative shortcut that neither untyped DataSets nor custom business entities support natively. In custom entity classes, though, dealing with NULL values is a kind of false problem in the sense that it is a problem your classes should solve if they are to provide a good representation of business entities.
Personally, I'm not crazy about typed DataSets, although I recognize they are an improvement over untyped DataSets. The real alternative that I see to DataSets—with costs and benefits that must be carefully evaluated—are custom classes and collections.
Custom Entities and Collections
Orthogonal to the use of generic and polymorphic containers like DataSets is the use of custom objects (custom business entities). Imagine you're building software for an accounting system that manages invoices, customers, orders, and related details. You can represent the list of customers through a DataSet that also includes orders and order details in separate tables connected to each other through in-memory relations. The representation of data is flat; you get to data via a relational API that is generic (Tables and Relations properties) with untyped DataSets and a little more precise with typed DataSets.
When you access data for a customer, you need to have all orders and related details at hand, possibly in the same data structure and available through ad hoc methods and behaviors. You can also code this via custom classes and collections. Figure 2 illustrates the different approaches that are available.
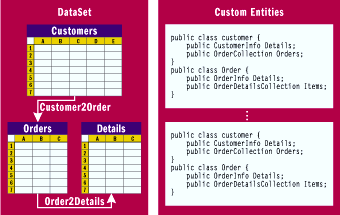
Figure 2** DataSets and Custom Entities **
Custom entities provide the means to expose real data in easy-to-access APIs without forcing every data model to fit in the relational model. Like it or not, in the real world all data is rarely entirely relational. By using DataSets, you render data with some approximation, albeit without loss of information.
Custom entities supply strong typing and more compact, faster objects. At the same time, they are abstract enough to require no changes to the DAL if the underlying database schema changes. Being custom classes, they enable you to incorporate information aggregated from multiple sources and represent free-form and hierarchical data. A custom class can be marked as serializable and serialized through any super-optimized algorithm. Of course, you have to write these custom classes yourself (or have a tool generate them for you), whereas the DataSet class already exists.
Make Your Choice
The key feature of custom entity classes is that they add behavior to your data. In doing so, they add expressivity to your code and enable the representation of any complex relationship. The key feature of DataSets is that they are good enough to do virtually everything and have no significant development costs associated with them. DataSets provide excellent support for optimistic concurrency scenarios and include a built-in mechanism for indexing, filtering, and searching tables and creating relations between tables. Moreover, DataViews enable you to create dynamic views of the data stored in a DataSet, a capability that is often used in data-binding applications. Using a DataView, you can expose the data in a table with various sort orders, and you can filter the data by row state or based on filter expressions. Another important difference between DataSets and custom classes is that a DataSet is already a special flavor of a collection class. For custom business entities you must implement a whole slew of collection interfaces in order to provide for effective containment and data-binding capabilities.
In my opinion, using custom business objects results in a far more elegant and neat solution where data is perfectly modeled on the domain of the problem. Maintenance and extensions are greatly facilitated, readability is assured, and technical documentation is easier. These benefits, though, frequently come at a significant development cost. And the cost is so high that many developers and architects using .NET sometimes don't even consider it.
Using custom business entities means that you write the following: collection classes to hold data (OrderCollection), classes to represent business entities (OrderInfo), factory classes to instantiate objects, and helper classes to take care of data access and persistence and to populate the facade classes exposed to the system. If you need data serialization across tiers, you have to ensure your classes are properly serializable. If you need to support aggregation of data sources or multiple versions of data, you need to provide that yourself, whereas DataSet provides aggregation capabilities through its merge functionality. If you need optimistic concurrency and batch update capabilities, you must implement that yourself. Unlike implementing ISerializable, creating a mechanism for concurrency is not trivial. With custom classes, you don't have an engine like ADO.NET relations to create logical links between tables. You also have to explicitly add support for the design-time scenarios already supported by a DataSet (for more info, see Paul Ballard's article in this issue). Mapping custom collections and entities to a database can also be a complicated process that can require a significant amount of code, although custom tools can frequently provide autogenerated classes to aid in this process.
However, data relations is not necessary in all cases. Relations are generally used to provide child trees of data—for example, details of an order or all invoices for a customer. With custom classes, you usually have free-form code that can easily incorporate hierarchical data (see Figure 2). Relations are used to implement referential integrity in memory and cascade changes through related objects. This feature, if needed, must be coded manually.
You'll need to be ready to write custom classes that represent entities and collection classes to group entities. In the .NET Framework 1.x, to write collections you can take advantage of the CollectionBase class or implement IList directly. In the .NET Framework 2.0, generics greatly simplify things. A fully functional collection is not enough, though. If you want to bind custom entities to the presentation layer through data binding, you need to implement more interfaces—in particular, IBindingList and ITypedList.
When to Use Which
Both DataSets and custom classes don't limit what you can do in any way, and both can be used to accomplish the same aims. That said, DataSets are fantastic tools for prototyping applications and represent excellent solutions for building systems in a kind of emergency—a limited budget, an approaching deadline, or a short application lifetime. For relatively simple applications, custom entities add a perhaps unnecessary level of complexity. In this case, I suggest that you seriously consider using DataSets.
In the economy of a large, durable, complex enterprise system that takes several months to complete, the cost of architecting and implementing a bunch of collections classes is relatively minimal and is incurred only once. The advantages in terms of performance, expressivity, readability, and ease of maintenance largely repay the investment. You are not bound to a tabular rendering of data. Business rules and custom business entities can't always be adapted to look like a collection of tables. In general, you should avoid adapting data to the data container—quite the reverse, I'd say. Finally, using custom classes makes for easier unit testing because classes and logic are more strictly related than with DataSets. In Figure 3, you find a synoptic table with DataSets, typed DataSets, and custom entities compared by several factors.
Figure 3 DataSets, Typed DataSets, and Custom Business Entities
| DataSet | Typed DataSet | Custom Entities | |
|---|---|---|---|
| Built-in support for concurrency | Yes | Yes | To be added |
| Data Relationship | Yes | Yes | No |
| Serialization | Inefficient in .NET Framework 1.x | Same as DataSet, but can be improved | To be added |
| NULL values | No | Yes | To be added |
| Schema abstraction | Yes | Yes | Yes |
| Strong typing | No | Yes | Yes |
| Support for hierarchical data | Yes, but through a relational API | Yes, but through a relational API | Yes |
| Free-form data | No | No | Yes |
| Custom behavior | No | To be added | Yes |
| Ease of development | Yes | Yes | No, but can be improved through custom wizards and code generation |
| .NET data binding | Yes | Yes | To be added; requires the implementation of several additional interfaces |
| Interfacing with Web services | Costly, unless knowledge of the object is assumed on the client | Schema information is more precise and can be handled by the client | Yes |
| XML integration | Yes | Yes | To be added |
| Expression language | Yes | Yes | To be added |
| Data aggregation | Yes | Yes | To be added |
In any case, bear in mind that your decision should be based on full awareness of the benefits, implications, and repercussions. If you go for custom classes, take a look at some commonly used enterprise design patterns. Figure 4 details a few of them.
Figure 4 Design Patterns for Building a DAL
| Pattern | Description |
|---|---|
| Active Record | The entity object stores its own data as well as any available methods. Clients get an instance of the object and work with it as needed. |
| Data Mapper | The entity object contains only its own data. A neat separation exists between data and behavior. Behavior is delegated to an array of separate classes specific to the object. |
| Table Data Gateway | Variation of Data Mapper that delegates the implementation of required behaviors to external, gateway classes not specific to the object. The gateway can take scalar and instance data and serve multiple business objects. |
Wrap Up
The DataSet versus custom collection disagreement is an old one that for various reasons has never escalated into an outright war. However, the advent of the .NET Framework 2.0 and generics enables developers to generate and manage collections much more quickly and effectively. For example, implementing IBindingList—which is required for data binding—is as easy as adding a couple of overrides to a generic class. This could push the use of custom entities by making it affordable for more developers and in more scenarios. For this reason, it's more important than ever to learn the underpinnings of DataSets and collections so you can make your choice consciously and wisely. For more information on these topics, take a look at the following blogs: Scott Hanselman's at Returning DataSets from WebServices is the Spawn of Satan and Represents All That Is Truly Evil in the World, Jelle Druyts' at DataSets Are Not Evil, Andrew Conrad's at Nix the DataSet??????, and ObjectSharp at DataSet FAQ.
Send your questions and comments for Dino to cutting@microsoft.com.
Dino Esposito is a Wintellect instructor and consultant based in Italy. Author of Programming ASP.NET and the new book Introducing ASP.NET 2.0 (both from Microsoft Press), he spends most of his time teaching classes on ASP.NET and ADO.NET and speaking at conferences. Get in touch with Dino at cutting@microsoft.com or join the blog at weblogs.asp.net/despos.