Test Run
Test Harness Design Patterns
James McCaffrey and James Newkirk
Code download available at:TestRun0508.exe(147 KB)
Contents
The Six Basic Lightweight Test Harness Patterns
Flat Test Case Data
Hierarchical Test Case Data
Relational Test Case Data
The TDD Approach with the NUnit Framework
Conclusion
The Microsoft® .NET Framework provides you with many ways to write software test automation. But in conversations with my colleagues I discovered that most engineers tend to use only one or two of the many fundamental test harness design patterns available to them. Most often this is true because many developers and testers simply aren't aware that there are more possibilities.
Furthermore I discovered that there is some confusion and debate about when to use a lightweight test harness and when to use a more sophisticated test framework like the popular NUnit. In this month's column James Newkirk, the original author of NUnit, joins me to explain and demonstrate how to use fundamental lightweight test harness patterns and also show you their relation to the more powerful NUnit test framework.
The best way to show you where the two of us are headed is with three screen shots. Suppose you are developing a .NET-based application for Windows®. The screen shot in Figure 1 shows the fairly simplistic but representative example of a poker game. The poker application references a PokerLib.dll library that has classes to create and manipulate various poker objects. In particular there is a Hand constructor that accepts a string argument like "Ah Kh Qh Jh Th" (ace of hearts through 10 of hearts) and a Hand.GetHandType method that returns an enumerated type with a string representation like RoyalFlush.
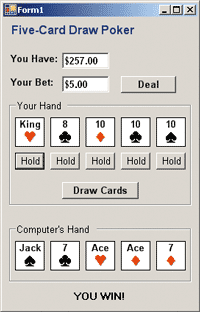
Figure 1** System Under Test **
Now suppose you want to test the underlying PokerLib.dll methods for functional correctness. Manually testing the library would be time-consuming, inefficient, error-prone, and tedious. You have two better testing strategies. A first alternative to manual testing is to write a lightweight test harness that reads test case input and expected values from external storage, calls methods in the library, and compares the actual result with the expected result. When using this approach, you can employ one of several basic design patterns. Figure 2 shows a screen shot of a test run that uses the simplest of the design patterns. Notice that there are five test cases included in this run; four cases passed and one failed. The second alternative to manual testing is to use a test framework. Figure 3 shows a screen shot of a test run which uses the NUnit framework.

Figure 2** Lightweight Test Harness Run **
In the sections that follow, we will explain fundamental lightweight test harness design patterns, show you a basic NUnit test framework approach, give you guidance on when each technique is most appropriate, and describe how you can adapt each technique to meet your own needs. You'll learn the pros and cons of multiple test design patterns, and this information will be a valuable addition to your developer, tester, and manager skill sets.
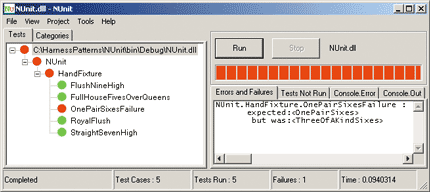
Figure 3** NUnit Test Framework Run **
The Six Basic Lightweight Test Harness Patterns
It is useful to classify lightweight data-driven test harness design patterns into six categories based on type of test case storage and test case processing model. There are three fundamental types of test case storage: flat file, hierarchical, and relational. Additionally, there are two fundamental processing models: streaming and buffered. This categorization leads to six test harness design patterns, the cross-product of the storage types with the processing models.
Of course you can think of many other possibilities, but these six categories give you a practical way to think about structuring your lightweight test harnesses. Notice that this assumes that the test case storage is external to the test harness code. In general, external test case storage is better than embedding test case data with the harness code because external storage can be edited and shared more easily than embedded data. However, as we'll explain later, the test-driven approach is primarily a developer activity and typically uses embedded test case data which does have certain advantages over external data. Separately, NUnit can be used with external test case storage and can support both streaming and buffered processing models.
Flat Test Case Data
The most rudimentary type of test case data is flat data. The data in Figure 4 is the test case file used to generate the test run shown in Figure 2. Compared with hierarchical data and relational data, flat data is most appropriate when you have simple test case input and expected values, you are not in an XML-dominated environment, and you do not have a large test management structure.

Figure 4** Flat Test Case Data **
At a minimum every test case has an ID, one or more inputs, and one or more expected results. There is nothing profound about how to store test case data. Examples of flat data are text files, Excel worksheets, and individual tables in a database. Examples of hierarchical data stores are XML files and some .ini files. SQL Server™ databases and Access databases are examples of relational data stores when multiple tables are used in conjunction through relationships. Here you can see we're using a simple text file with a test case ID field, a single input field, and a single expected result field—simple and effective. We will discuss the pros and cons of each of the three storage types later in this column.
This pseudocode shows the basic streaming processing model:
open test case data store loop read a test case parse id, input, expected send input to system under test if actual result == expected result write pass result to external results file else write fail result to external results file end if end loop
The code in Figure 5 shows the main loop. The algorithm is implemented in Visual Basic® .NET, but any .NET-targeted language could be used. The complete source code for all examples is available in the code download that accompanies this column.
Figure 5 Streaming Flat Data Design
while ((line = sr.ReadLine()) != null) // main loop { tokens = line.Split(':'); // parse input caseid = tokens[0]; cards = tokens[1].Split(' '); expected = tokens[2]; Hand h = new Hand(cards[0],cards[1],cards[2],cards[3],cards[4]); // test actual = h.GetHandType().ToString(); Console.Write(caseid + " "); sw.Write(caseid + " "); if (actual == expected) // determine result { string rv = string.Format(" Pass {0} = {1}", h.ToShortString(), actual); Console.WriteLine(rv); sw.WriteLine(rv); } else { string rv = string.Format(" *FAIL* actual = {0} expected = {1}", actual, expected); Console.WriteLine(rv); sw.WriteLine(rv); } } //main loop
Notice that we echo test results to the command shell with a Console.WriteLine statement and write test results to an external text file with a call to StreamWriter.WriteLine. In general, it makes sense to save test case results to the same type of storage as your test case data, but this is considered to be more a matter of consistency than a technical issue.
We call the algorithm a streaming model because it resembles the .NET input-output streaming model; there is a continuous stream of test case input and test results. Now let's look at the buffered model. The pseudocode in Figure 6 is what we'll call the buffered processing model.
Figure 6 Buffered Algorithm
open test case data store loop read a test case from external storage save test data to in-memory data store end loop loop read a test case parse test case id, input, expected send input to system under test if actual result == expected result write pass result to in-memory data store else write fail result to in-memory data store end if end loop loop read test result from in-memory store write test result to external storage end loop
With the buffered test harness model we read all test case data into memory before executing any test cases. All test results are saved to an in-memory data store and then emitted to external storage after all test cases have been executed. In other words, test case input and results are buffered through the test system rather than streamed through the system. The code snippet in Figure 7 shows you how we implemented the buffered model using the test case data file that is shown in Figure 4.
Figure 7 Flat Data Buffered Design
// 1. read test case data into memory ArrayList cases = new ArrayList(); string line; while ((line = sr.ReadLine()) != null) cases.Add(line); // 2. main test processing loop ArrayList results = new ArrayList(); string caseid, expected, actual, result; string[] tokens, cards; for (int i = 0; i < cases.Count; ++i) { tokens = cases[i].ToString().Split(':'); // parse input caseid = tokens[0]; cards = tokens[1].Split(' '); expected = tokens[2]; Hand h = new Hand(cards[0],cards[1],cards[2],cards[3],cards[4]); actual = h.GetHandType().ToString(); result = caseid + " " + (actual == expected ? " Pass " + h.ToShortString() + " = " + actual : " *FAIL* actual = " + actual + " expected = " + expected); results.Add(result); // store result into memory } // 3. emit results to external storage for (int i = 0; i < results.Count; ++i) { Console.WriteLine(results[i].ToString()); sw.WriteLine(results[i]); }
If you compare the streaming processing model with the buffered model, it's pretty clear that the streaming model is both simpler and shorter. So why would you ever want to use the buffered model? There are two common testing scenarios where you should consider using the buffered processing model instead of the streaming model. First, if the aspect in the system under test involves file input/output, you often want to minimize the test harness file operations. This is especially true if you are monitoring performance. Second, if you need to perform some pre-processing of your test case input or post-processing of your test case results (for example aggregating various test case category results), it's almost always more convenient to have all results in memory where you can process them. The NUnit test framework is very flexible and can use external test case storage primarily with the buffered processing models. However, a complete discussion of how to use NUnit in these ways would require an entire article by itself and is outside the scope of this column.
Hierarchical Test Case Data
Hierarchical test case data, especially XML, has become very common. In this section we will show you the streaming and buffered lightweight test harness processing models when used in conjunction with XML test case data. Compared with flat test case data and relational data, hierarchical XML-based test case data is most appropriate when you have relatively complex test case input or expected results, or you are in an XML-based environment (your development and test effort infrastructure relies heavily on XML technologies). Here is a sample of XML-based test case data that corresponds to the flat file test case data in Figure 4:
<?xml version="1.0" ?> <TestCases> <case caseid="0001"> <input>Ah Kh Qh Jh Th</input> <expected>RoyalFlush</expected> </case> <case caseid="0002"> <input>Qh Qs 5h 5c 5d</input> <expected>FullHouseFivesOverQueens</expected> </case> ... </TestCases>
Because XML is so flexible there are many hierarchical structures we could have chosen. For example, the same test cases could have been stored as follows:
<?xml version="1.0" ?> <TestCases> <case caseid="0001" input="Ah Kh Qh Jh Th" expected="RoyalFlush" /> <case caseid="0002" input="Qh Qs 5h 5c 5d" expected=" FullHouseFivesOverQueens" /> ... </TestCases>
Just as with flat test case data, you can use a streaming processing model or a buffered model. In each case the algorithm is the same as shown in the basic streaming processing model algorithm and in the buffered algorithm that was shown in Figure 6. Interestingly though, the XML test case data model implementations are quite different from their flat data counterparts. Figure 8 shows key code from a C#-based streaming model implementation.
Figure 8 XML Data Streaming Design
xtw.WriteStartDocument(); xtw.WriteStartElement("TestResults"); while (!xtr.EOF) // main loop { if (xtr.Name == "TestCases" && !xtr.IsStartElement()) break; while (xtr.Name != "case" || !xtr.IsStartElement()) xtr.Read(); // advance to a <case> element if not there yet caseid = xtr.GetAttribute("caseid"); xtr.Read(); // advance to <input> input = xtr.ReadElementString("input"); // advance to <expected> expected = xtr.ReadElementString("expected"); // advance to </case> xtr.Read(); // advance to next <case> or </TestCases> cards = input.Split(' '); Hand h = new Hand(cards[0],cards[1],cards[2],cards[3],cards[4]); actual = h.GetHandType().ToString(); xtw.WriteStartElement("result"); xtw.WriteStartAttribute("caseid", null); xtw.WriteString(caseid); xtw.WriteEndAttribute(); xtw.WriteString(actual == expected ? " Pass " + h.ToShortString() + " = " + actual : " *FAIL* actual = " + actual + " expected = " + expected); xtw.WriteEndElement(); // </result> } // main loop
With a streaming model, we use an XmlTextReader object to read one XML node at a time. But because XML is hierarchical it is a bit tricky to keep track of exactly where we are within the file, especially when the nested becomes more extreme (in this particular example, the data is little more than a flat file, but it could be significantly more complex). We use an XmlTextWriter object to save test results in XML form. Now we'll show you a buffered approach for XML test case data. Figure 9 shows key code from a buffered processing model implementation.
Figure 9 XML Data Buffered Design
// 1. read test case data into memory XmlSerializer xds = new XmlSerializer(typeof(TestCases)); TestCases tc = (TestCases)xds.Deserialize(sr); // 2. processing loop string expected, actual; string[] cards; TestResults tr = new TestResults(tc.Items.Length); for (int i = 0; i < tc.Items.Length; ++i) // test loop { SingleResult res = new SingleResult(); res.caseid = tc.Items[i].caseid; cards = tc.Items[i].input.Split(' '); expected = tc.Items[i].expected; Hand h = new Hand(cards[0],cards[1],cards[2],cards[3],cards[4]); actual = h.GetHandType().ToString(); res.result = (actual == expected) ? // store results into memory "Pass " + h.ToShortString() + " = " + actual : "*FAIL* " + "actual = " + actual + " expected = " + expected; tr.Items[i] = res; } // 3. emit results to external storage XmlTextWriter xtw = new XmlTextWriter("..\\..\\TestResults.xml",System.Text.Encoding.UTF8); XmlSerializer xs = new XmlSerializer(typeof(TestResults)); xs.Serialize(xtw,tr);
We use an XmlSerializer object from the System.Xml.Serialization namespace to read the entire XML test case file into memory with a single line of code and also to write the entire XML result file with a single line of code. Of course, this requires us to prepare appropriate collection classes (TestCases and TestResults in the code) to hold the data.
Unlike flat test case data, with XML data the buffered model test harness code tends to be shorter and simpler. So when might you consider using a streaming model in conjunction with XML test case data? Most often you will want to use a streaming model when you have a lot of test cases to deal with. Reading a huge amount of test case data into memory all at once may not always be possible, especially if you are running stress tests under conditions of reduced internal memory.
Relational Test Case Data
In this section we'll describe the streaming and buffered lightweight test harness processing models when used in conjunction with SQL test case data. Compared with flat data and hierarchical data, relational SQL-based test case data is most appropriate when you have a very large number of test cases, or you are in a relatively long product cycle (because you will end up having to store lots of test results), or you are working in a relatively sophisticated development and test infrastructure (because you will have lots of test management tools). Figure 10 shows test case data thas has been stored in a SQL database.

Figure 10** SQL-based Test Case Data **
Just as with flat test case data and hierarchical data, you can use a streaming processing model or a buffered model. The basic streaming and buffered models described earlier will be the same.
The streaming model implementation is included in this column's download. If you examine the code you'll see that for a streaming model we like to use a SqlDataReader object and its Read method. For consistency we insert test results into a SQL table rather than save to a text file or XML file. We prefer to use two SQL connections—one to read test case data and one to insert test results. As with all the techniques in this column, there are many alternatives available to you.
The code for the buffered processing model can be downloaded from the MSDN Magazine Web site. Briefly, we connect to the test case database, fill a DataSet with all the test case data, iterate through each case, test, store all results into a second DataSet, and finally emit all results to a SQL table.
Using relational test case data in conjunction with ADO.NET provides you with many options. Assuming memory limits allow, we typically prefer to read all test case data into a DataSet object. Because all the test case data is in a single table, we could also have avoided the relatively expensive overhead of a DataSet by just using a DataTable object. However in situations where your test case data is contained in multiple tables, reading into a DataSet gives you an easy way to manipulate test case data using a DataRelation object. Similarly, to hold test case results we create a second DataSet object and a DataTable object. After running all the test cases we open a connection to the database that holds the results table (in this example it's the same database that holds the test case data) and write results using the SqlDataAdapter.Update method.
Recall that when using flat test case data, a streaming processing model tends to be simpler than a buffered model, but that when using hierarchical XML data, the opposite is usually true. When using test case data stored in a single table in SQL Server, a streaming processing model tends to be simpler than a buffered model and the technique of choice. When test case data spans multiple tables, you'll likely want to use a buffered processing model.
The TDD Approach with the NUnit Framework
In the previous sections you've seen six closely related lightweight test harness design patterns. A significantly different but complementary approach is to use an existing test framework. The best known framework for use in a .NET environment is the elegant NUnit framework as shown in Figure 3. See the MSDN®Magazine article by James Newkirk and Will Stott at Test-Driven C#: Improve the Design and Flexibility of Your Project with Extreme Programming Techniques for details. The code snippet in Figure 11 shows how you can use NUnit to create a DLL that can be used by NUnit's GUI interface. And the code snippet in Figure 12 shows how you can use NUnit with external XML test case data to create a DLL that can be used by NUnit's command-line interface.
Figure 12 NUnit Approach with External XML Test Cases
[Suite] public static TestSuite Suite { get { TestSuite testSuite = new TestSuite("XML Buffered Example"); using(StreamReader reader = new StreamReader("TestCases.xml")) { XmlSerializer xds = new XmlSerializer(typeof(TestCases)); TestCases testCases = (TestCases)xds.Deserialize(reader); foreach(Case testCase in testCases.cases) { string[] cards = testCase.input.Split(' '); HandType expectedHandType = (HandType)Enum.Parse( typeof(HandType), testCase.expected); Hand hand = new Hand(cards[0], cards[1], cards[2], cards[3], cards[4]); testSuite.Add(new HandTypeFixture( testCase.id, expectedHandType, hand.GetHandType())); } } return testSuite; } }
Figure 11 NUnit Approach with Embedded Test Cases
using NUnit.Framework; using PokerLib; [TestFixture] public class HandFixture { [Test] public void RoyalFlush() { Hand hand = new Hand("Ah", "Kh", "Qh", "Jh", "Th"); Assert.AreEqual(HandType.RoyalFlush, hand.GetHandType()); } ... // other tests here }
You may be wondering whether it's better to use NUnit or to write a custom test harness. The best answer is that it really depends on your scenarios and environment, but using both test techniques together ensures a thorough test effort. The NUnit framework and lightweight test harnesses are designed for different testing situations. NUnit was specifically designed to perform unit testing in a test-driven development (TDD) environment, and it is a very powerful tool. A lightweight test harness is useful in a wide range of situations, such as when integrated into the build process, and is more traditional than the NUnit framework in the sense that a custom harness assumes a conventional spiral-type software development process (code, test, fix).
A consequence of NUnit's TDD philosophy is that test case data is typically embedded with the code under test. Although embedded test case data cannot easily be shared (for example when you want to test across different system configurations), embedded data has the advantage of being tightly coupled with the code it's designed to test, which makes your test management process easier. Test-driven development with NUnit helps you write code and test it. This is why embedded tests with NUnit are acceptable—you change your tests as you change your code. Now this is not to say that the two test approaches are mutually exclusive; in particular NUnit works nicely in a code-first, test-later environment, and can utilize an external test case data source. And a lightweight test harness can be used in conjunction with a TDD philosophy.
The NUnit framework and custom lightweight test harnesses have different strengths and weaknesses. Some of NUnit's strengths are that it is a solid, stable tool, it is a nearly a de-facto standard because of widespread use, and it has lots of features. The strengths of custom test harnesses are that they are very flexible, allowing you to use internal or external storage in a variety of environments, test for functionality as well as performance, stress, security and other types of testing, and execute sets of individual test cases or multiple state change test scenarios.
Conclusion
Let's briefly summarize. When writing a data-driven lightweight test harness in a .NET environment you can choose one of three types of external test case data storage: flat data (typically a text file), hierarchical data (typically an XML file), or relational data (typically a SQL Server database). Often you will have no choice about the type of data store to use because you will be working in an already existing development environment. Flat data is good for simple test case scenarios, hierarchical data works very well for technically complex test case scenarios, and relational data is best for large test efforts.
When writing a lightweight test harness you can employ either a streaming processing model or you can choose a buffered processing model. A streaming processing model is usually simpler except when used with truly hierarchical or relational data, in which case the opposite is true. A streaming model is useful when you have a very large number of test cases, and a buffered model is most appropriate when you are testing for performance or when you need to process test cases and results. Using a test framework like NUnit is particularly powerful for unit testing when you are employing a TDD philosophy.
With the .NET environment and powerful .NET-based tools like NUnit, it's possible to write great test automation quickly and efficiently. The release of Visual Studio® 2005 will only enhance your ability to write test automation and the Team System version in Visual Studio 2005 will have many NUnit-like features. With software systems increasing in complexity, testing is more important than ever. Knowledge of these test harness patterns as well as of frameworks like NUnit will help you test better and produce better software systems.
Send your questions and comments for James to testrun@microsoft.com.
James McCaffrey works for Volt Information Sciences Inc., where he manages technical training for software engineers working at Microsoft. He has worked on several Microsoft products including Internet Explorer and MSN Search. James can be reached at jmccaffrey@volt.com or v-jammc@microsoft.com.
James Newkirk is the development lead for the Microsoft Platform Architecture Guidance team, building guidance and reusable assets for enterprise customers through the patterns & practices series. He is the coauthor of Test Driven Development in Microsoft .NET (Microsoft Press, March 2004).