Coding Tools
Improved Support For Parallelism In The Next Version Of Visual Studio
Stephen Toub and Hazim Shafi
This article is based on prerelease versions of Visual C++, Visual Studio, and the .NET Framework. All information herein is subject to change.
This article discusses:
|
This article uses the following technologies: Visual Studio, Multithreading |
Contents
Expressing Parallelism in Managed Code
Expressing Parallelism in Native Code
Debugging Parallel Applications
Profiling Parallel Applications
Looking Forward
It wasn't too long ago that many software performance bottlenecks could be fixed simply by a trip to the local computer store. Consumers and companies with the means and motivation to buy new computers every 18 to 24 months would find with every new purchase their compute-intensive applications running twice as fast as before.
Alas, those good old days would appear to be behind us. Gone are the days of exponential increases in CPU speed, largely due to pesky laws of physics that are preventing hardware manufacturers from economically and ecologically scaling clock speeds at rates anywhere near to what we're accustomed to—and to what modern advances in software demand. Instead, the influx of transistors as outlined by Moore's law is enabling chip manufacturers to exponentially scale the number of cores available in commodity hardware. Today, it's rare to find single-core machines on sale in the United States, with dual-core being the norm. Next year, expect the typical consumer machine on sale to be a quad-core, with eight-core as the norm to follow shortly thereafter.
Unfortunately, the majority of the software today will not automatically take advantage of such exponential growth in processor count. To do so, software must be written in a manner that supports safe and effective decomposition of its constituent components such that these individual parts can be computed in parallel and distributed across all of the cores, thus realizing the potential that multicore and manycore systems promise.
Such expression of parallelism with today's preeminent programming languages, frameworks, and development environments is no cakewalk. Multithreaded programming, for anything but the most trivial of systems, is incredibly difficult and error prone today. Parallel patterns are not prevalent, well-known, or easy to implement. Even when an application can be constructed to take advantage of concurrency, functional correctness and performance problems frequently arise, from the most well-known race conditions and deadlocks to the more obscure cache coherency overheads, lock convoys, and priority inversion.
Moreover, even if developers were able to conquer such patterns, the time and effort involved in doing so places a burden on businesses, where the best (and the best-compensated) developers are expected to focus on business problems that affect the bottom line rather than on concurrency problems that are a mere cost of staying competitive in a performance-centric industry. Compounding these problems significantly, the tools available for developers to debug and analyze their parallel applications are rudimentary at best.
As a result, the big players in software development are taking strides to make parallelism much easier for all developers to employ, and Microsoft is helping to lead the way. Plans for the next version of Visual Studio include a solid foundation for parallelism, encompassing significant improvements for native and managed code alike, both in the core platform and in tooling support.
Expressing Parallelism in Managed Code
Consider the following problem statement: given a list of baby birth information, search for babies of a given name, born in a given state, in a specific range of years, and return the results. Here is what a typical solution in C# might look like:
IEnumerable<BabyInfo> Search(
IEnumerable<BabyInfo> babies, QueryInfo qi) {
foreach (var baby in babies) {
if (baby.Name == qi.Name && baby.State == qi.State &&
baby.Year >= qi.YearStart && baby.Year <= qi.YearEnd) {
yield return baby;
}
}
}
This is largely an "embarrassingly parallel" problem. Each individual baby can be analyzed independently, in theory making it easy to parallelize their processing by partitioning the work across all available processors. Unfortunately, that which is theoretical doesn't always translate into practical.
Figure 1 shows one attempt at parallelizing this solution. As you can tell from the length of the code figure, the task is not as easy with today's Microsoft .NET Framework as the parallelization-friendly description of the problem would suggest. Even with all of this code, the solution is far from ideal. Manual partitioning is employed to distribute the processing to multiple cores. Detailed knowledge of synchronization primitives is necessary to understand how to coordinate between threads. The overheads of locking will likely dominate the implementation due to the contention on the enumerator and the ratio of work done inside versus outside of the critical regions. The list goes on.
Figure 1 Naive Manual Parallelization
IEnumerable<BabyInfo> Search(
IEnumerable<BabyInfo> babies, QueryInfo qi) {
var results = new List<BabyInfo>();
int partitionsCount = Environment.ProcessorCount;
int remainingCount = partitionsCount;
var enumerator = babies.GetEnumerator();
try {
using (ManualResetEvent done = new ManualResetEvent(false)) {
for (int i = 0; i < partitionsCount; i++) {
ThreadPool.QueueUserWorkItem(delegate {
while(true) {
BabyInfo baby;
lock (enumerator) {
if (!enumerator.MoveNext()) break;
baby = enumerator.Current;
}
if (baby.Name == qi.Name &&
baby.State == qi.State &&
baby.Year >= qi.YearStart &&
baby.Year <= qi.YearEnd) {
lock(results) results.Add(baby);
}
}
if (Interlocked.Decrement(ref remainingCount) == 0)
done.Set();
});
}
done.WaitOne();
}
}
finally {
IDisposable d = enumerator as IDisposable;
if (d != null) d.Dispose();
}
return results;
}
What's even more disheartening when looking at this solution is seeing the ratio of parallel boilerplate code to the code actually implementing the method's business logic. It would be much more useful if all of that boilerplate could be handled by the system, such that the developer could focus on the problem statement on hand:
IEnumerable<BabyInfo> Search(
IEnumerable<BabyInfo> babies, QueryInfo qi) {
var results = new ConcurrentStack<BabyInfo>();
Parallel.ForEach(babies, baby => {
if (baby.Name == qi.Name && baby.State == qi.State &&
baby.Year >= qi.YearStart && baby.Year <= qi.YearEnd) {
results.Push(baby);
}
});
return results;
}
Astute readers may notice that the problem statement also lends itself quite nicely to an implementation using LINQ-to-Objects. Imagine if we augmented the original problem statement such that we also want the baby information back in order sorted by year. That additional requirement would add a quite a bit of code to the previous manual implementation, especially if we wanted the sort done in parallel. With LINQ, that solution can be coded as shown at the beginning of Figure 2 . Now imagine that the LINQ query could be parallelized automatically, simply by appending AsParallel to the babies enumerable, as shown at the bottom of Figure 2 .
Figure 2 Parallelization with PLINQ
Sequential
IEnumerable<BabyInfo> Search(
IEnumerable<BabyInfo> babies, QueryInfo qi) {
return from baby in babies
where baby.Name == qi.Name && baby.State == qi.State &&
baby.Year >= qi.YearStart && baby.Year <= qi.YearEnd
orderby baby.Year ascending
select baby;
}
Parallel
IEnumerable<BabyInfo> Search(
IEnumerable<BabyInfo> babies, QueryInfo qi) {
return from baby in babies.AsParallel()
where baby.Name == qi.Name && baby.State == qi.State &&
baby.Year >= qi.YearStart && baby.Year <= qi.YearEnd
orderby baby.Year ascending
select baby;
}
Luckily, these constructs are not imaginary at all. Some readers may recognize Parallel.ForEach as being a part of the Task Parallel Library (TPL), which has been available publicly as part of a Community Technology Preview (CTP) for Parallel Extensions to the .NET Framework since December 2007. Others may recognize AsParallel as being a part of Parallel LINQ (PLINQ), also available through the Parallel Extensions CTPs.
As of the next version of Visual Studio, these will become part of the core .NET Framework, available for all developers using .NET to consume from any .NET-compliant language: Parallel.ForEach as part of mscorlib.dll and AsParallel as part of System.Core.dll right alongside the sequential LINQ implementation.
TPL, exposed through the System.Threading and System.Threading.Tasks namespaces, has changed quite a bit since it was introduced to the world in the October 2007 issue of MSDN Magazine (see msdn.microsoft.com/magazine/cc163340), but its core principles remain the same. It delivers replacements for high-level constructs used in sequential applications today, such as Parallel.For to parallelize for loops, Parallel.ForEach as shown in a previous example to parallelize foreach loops, and Parallel.Invoke to parallelize a set of statements. These methods all accept delegates representing the code to execute in parallel, which means they work especially well with languages that support anonymous methods and lambda expressions.
For example, the code in Figure 3 is an excerpt from a ray tracer written in F# by Luke Hoban (Program Manager for F# at Microsoft) that utilizes the Parallel.For method to parallelize the rendering of a scene. You should note that the main difference between the two implementations falls to a single line. Here's that line from the original code:
for y = 0 to screenHeight - 1 do
Figure 3 Using Parallel.For from F#
Sequential
member this.Render(scene, rgb : int[]) =
for y = 0 to screenHeight - 1 do
let stride = y * screenWidth
for x = 0 to screenWidth - 1 do
let color = TraceRay(
{Start = scene.Camera.Pos;
Dir = GetPoint x y scene.Camera },
scene, 0)
let intColor = color.ToInt ()
rgb.[x + stride] <- intColor
Parallel
member this.Render(scene, rgb : int[]) =
Parallel.For(0, screenHeight, fun y ->
let stride = y * screenWidth
for x = 0 to screenWidth - 1 do
let color = TraceRay(
{Start = scene.Camera.Pos;
Dir = GetPoint x y scene.Camera },
scene, 0)
let intColor = color.ToInt ()
rgb.[x + stride] <- intColor)
And here's the parallel version:
Parallel.For(0, screenHeight, fun y ->
The partitioning and execution of the iterations that make up the scene rendering is then handled automatically by TPL.
As another example, the following sequential code executes a delegate for each node in a tree:
static void WalkTree<T>(Tree<T> tree, Action<T> handler) {
if (tree == null) return;
handler(tree.Data);
WalkTree(tree.Left, handler);
WalkTree(tree.Right, handler);
}
We can use Parallel.Invoke to easily parallelize the execution of this tree walk:
static void WalkTree<T>(Tree<T> tree, Action<T> handler) {
if (tree == null) return;
Parallel.Invoke(
() => handler(tree.Data),
() => WalkTree(tree.Left, handler),
() => WalkTree(tree.Right, handler));
}
These higher-level constructs in TPL are built on top of a lower-level set of constructs that form the foundation for task-based parallelism. This includes a Task class that represents an individual work item that can be scheduled for execution, a Future<T> class that represents the promise of a computed value at some point in the future, a TaskManager class that represents a scheduler used to execute tasks and computational futures, and a handful of supporting types for effectively constructing and managing tasks. With these solutions, incredibly complex parallel systems can be built with much less effort than is required today.
They can also be executed more efficiently on more powerful hardware, thanks to a new concurrency scheduler built into mscorlib. This scheduler is represented publicly through the aforementioned TaskManager class, which enables individual schedulers to be constructed that give isolated tasks discrete policies for how they should be executed. A shared resource manager coordinates amongst scheduler instances to ensure that the processing resources of the system are utilized effectively in a manner that limits oversubscription as much as possible. The scheduler is designed with optimizations for solutions that typically occur when using fine-grained parallelism, such as enabling recursive algorithms to take better advantage of the caches in the machine.
It's important to note that the .NET Framework has supported multithreaded development since its inception. The System.Threading namespace provides a plethora of low-level synchronization primitives, such as monitors, mutexes, semaphores, events, and thread-local storage, many of them since version 1.0. Languages like C# and Visual Basic expose support through constructs such as their lock and SyncLock keywords, respectively. However, authoring parallel systems effectively with libraries like TPL often requires higher-level coordination and synchronization types.
As a result, the next version of the .NET Framework will also see the System.Threading namespace rounded out with additional constructs that make multithreaded applications easier to write. As an example, lazy initialization is a common technique used in applications to load and initialize data only when it's first needed. This is typically done either to delay the processing to a point where the processing time will be less noticeable (such as to offload some work that might otherwise be done during start-up in order to improve start-up time), or to completely eliminate the processing if the lazily initialized data is used infrequently enough that some runs of the application may not need it at all. Either way, to implement this technique in a multithreaded application can be error-prone and repetitive to code manually, as it frequently involves multiple threads racing to initialize the data.
To solve this, the .NET Framework will include the LazyInit<T> type, which makes the most common patterns of thread-safe lazy initialization a breeze. Accessing the Value property of the LazyInit<T> forces the initialization if it hasn't already occurred, and returns the initialized data; the application will still maintain its correctness even if multiple threads race to retrieve the Value.
Here we have Visual Basic code that takes advantage of a LazyInit<T> in several ways:
Private _d1 As LazyInit(Of MyData)
Private _d2 As LazyInit(Of MyData) = New LazyInit(Of MyData)( _
Function() MyData.Load())
Private Shared _d3 As LazyInit(Of MyData) = New LazyInit(Of MyData)( _
Function() MyData.Load(), LazyInitMode.EnsureSingleExecution)
Private _d4 As LazyInit(Of MyData) = New LazyInit(Of MyData)( _
Function() MyData.Load(), LazyInitMode.ThreadLocal)
The _d1 variable is an instance member to be lazily-initialized. This example assumes that the MyData type has a public, parameterless constructor, allowing LazyInit<T> to construct an instance of MyData using Activator.CreateInstance.
The _d2 variable is also an instance member. However, this example uses a developer-provided lambda expression as the code for initializing the variable when it's accessed.
Like _d2, the _d3 variable is also initialized with a custom delegate. However, this time the variable is static (Shared in Visual Basic). The developer has also opted to override the default initialization mode to ensure that the provided delegate is only executed once, even if there's a race with multiple threads accessing the Value property. (The default mode allows the delegate to be executed multiple times, but ensures that only one result is ever published publicly through Value.)
Finally, the _d4 variable uses the ThreadLocal mode. For those readers familiar with the ThreadStaticAttribute, note that LazyInitMode.ThreadLocal is similar in that it ensures that each accessing thread gets its own copy of the data. However, while ThreadStatic is likely more efficient due to optimizations for it in the runtime, LazyInit<T> trumps ThreadStaticAttribute in capabilities. For one, ThreadStaticAttribute can only be used with static variables, whereas LazyInit<T> can have thread-locals as instance members.
Additionally, the ThreadStaticAttribute can bite a lot of developers when trying to use it. Consider the following code:
[ThreadStatic]
private static MyData _d5 = new MyData();
If no other code in the application sets the _d5 variable, would you be surprised to access _d5 and find its value null? That situation is perfectly possible. The issue here is that the C# compiler hoists the initialization of _d5 into the containing type's static constructor. The static constructor is only executed just before the type is needed (a great example of lazy initialization), and it's only executed once. This means the first thread to access the type will find _d5 initialized, but other threads will see the value as null. LazyInit<T> addresses this situation with its ThreadLocal mode to ensure that all threads accessing the LazyInit<T>'s Value property will find it properly initialized.
This is just one example of the new threading constructs that will be available in the next version of the .NET Framework. Others include CountdownEvent, Barrier, and SpinWait.
Additionally, the new support also includes a key set of thread-safe collections that aid in the manipulation of shared data. These collections appear in the System.Collections.Concurrent namespace (note that previous CTPs had them in the System.Threading.Collections namespace), and address a variety of situations. Types like ConcurrentQueue<T> and ConcurrentStack<T> (which was shown in an earlier example) represent thread-safe and scalable alternatives to the generic Queue<T> and Stack<T>, and types like BlockingCollection<T> make it easy to implement blocking producer/consumer scenarios, where multiple threads are producing data for consumption by a host of consumer threads, as well as pipeline patterns, where data is flowing through a series of filters that can be executed in parallel.
As already mentioned, PLINQ is a core part of the next version of the .NET Framework. For read-only queries that process large amounts of data, PLINQ provides a simple, declarative path towards parallelization. By adding AsParallel to the data source as shown in the earlier baby names example, the developer is switching over to the PLINQ implementation of the .NET Standard Query Operators. (This switch is made explicit so that developers are forced to opt-in to the parallelization support. This is important given that, while most LINQ queries are read-only, some do perform mutations. If PLINQ is used with those mutations, the mutations would need to be thread-safe in order for the parallelization to be safe.)
Under the covers, PLINQ uses classic data parallelism techniques to partition the input data, process it on multiple threads, and merge the data back together in a manner that is appropriate to how the data is being produced and consumed. For more information on PLINQ, see the October 2007 issue of MSDN Magazine (msdn.microsoft.com/magazine/cc163329), where it was first discussed in detail.
Expressing Parallelism in Native Code
Over the last few years, we've heard several developers question the devotion shown at Microsoft to native C++. While we understand the concerns, we also see all of the effort being directed at native code in the Developer Division at Microsoft and we can say with a clear conscience that we see those fears being addressed. For example, the Visual C++ team recently released a fully supported implementation of Technical Report 1 (TR1) as well as significant updates to MFC, both of which are available as part of the Visual C++ 2008 Feature Pack (see go.microsoft.com/fwlink/?LinkId=124366). With regard to concurrency, support for parallelizing native C++ applications has been one of the most frequently requested features, and providing that support is a primary goal of both the Visual C++ and Parallel Computing Platform teams. The next version of Visual Studio and Visual C++ will reflect that.
As with managed code, enabling fine-grained parallelism and the migration of sequential applications to parallel applications are at the heart of the concurrency support in Visual C++. Consider the motivating example of a simple matrix multiplication:
void MatrixMult(int size, double** m1,
double** m2, double** result) {
for (int i = 0; i < size; i++) {
for (int j = 0; j < size; j++) {
result[i][j] = 0;
for (int k = 0; k < size; k++) {
result[i][j] += m1[i][k] * m2[k][j];
}
}
}
}
An attempt to parallelize this method is shown in Figure 4 .
Figure 4 Parallelizing MatrixMult
void MatrixMult(int size, double** m1, double** m2, double** result) {
int N = size;
int P = 2 * NUMPROCS;
int Chunk = N / P;
HANDLE hEvent = CreateEvent(NULL, TRUE, FALSE, NULL);
long counter = P;
for (int c = 0; c < P; c++) {
std::thread t ([&,c] {
for (int i = c * Chunk;
i < (c + 1 == P ? N : (c + 1) * Chunk);
i++) {
for (int j = 0; j < size; j++) {
result[i][j] = 0;
for (int k = 0; k < size; k++) {
result[i][j] += m1[i][k] * m2[k][j];
}
}
}
if (InterlockedDecrement(&counter) == 0) SetEvent(hEvent);
});
}
WaitForSingleObject(hEvent,INFINITE);
CloseHandle(hEvent);
}
This code demonstrates some useful new functionality being introduced in the next version of Visual C++, including support for the C++0x std::thread type as well as lambda expressions, which greatly simplify the development of asynchronous patterns.
However, even with these additions, this solution still leaves a lot to be desired. Static partitioning is used to divide the work across all available processors, but if there's any unevenness in the computation, or if there's anything else happening on the machine that could cause partitions to be processed at different speeds, many threads could end up waiting for (and offering no assistance to) one or more threads that need to finish their portions of the work.
The solution still requires knowledge of synchronization primitives like events—and how many readers can say, without looking at the documentation, how those CreateEvent parameters NULL, TRUE, FALSE, and NULL affect the synchronization?
The solution is error prone, with great potential for difficult-to-detect off-by-one errors in the partitioning step. Explicit interlocked operations are necessary to track the number of outstanding threads. The solution isn't taking advantage of the thread that's calling MatrixMult to engage in the processing, preferring instead to block it and thus waste some potentially valuable system resources. And so on.
We need an easier solution, and the next version of Visual C++ provides one:
void MatrixMult(int size, double** m1, double** m2, double** result) {
parallel_for(0, size, 1, [&](int i) {
for (int j = 0; j < size; j++) {
result[i][j] = 0;
for (int k = 0; k < size; k++) {
result[i][j] += m1[i][k] * m2[k][j];
}
}
});
}
This example still takes advantage of lambda expressions, but it's also using the new parallel_for method, part of the Parallel Pattern Library (PPL) to be shipped in the Visual C++ runtime libraries. Note that parallel_for is one of several high-level parallelization functions that are being developed, along with others like parallel_for_each, parallel_accumulate, and parallel_invoke. Many of these methods should feel familiar, as they provide direct parallel counterparts to their Standard Template Library (STL) equivalents, and enable easy substitution of the parallel method for the sequential method with minimal code rewriting (assuming, of course, that the operation being performed in parallel is thread-safe).
For example, consider a for_each call that iterates over a std::vector of objects representing enemies in a game, and updates each of their positions based on their capabilities and locations:
for_each(enemies.begin(), enemies.end(), [&](AIEnemy& cur) {
cur.updatePosition();
})
As long as the vector in question contains no duplicates, and as long as the updatePosition member function only modifies the local object, this method can be parallelized simply by prepending parallel_ to the method call:
parallel_for_each(enemies.begin(), enemies.end(), [&](AIEnemy& cur) {
cur.updatePosition();
});
Just as how in managed code the System.Threading.Parallel class is built on top of lower-level types for handling task parallelism, so too in the native solution are the parallel_ methods. (Where appropriate, the native and managed solutions will feel similar, enabling developers to more easily take knowledge from one domain and apply it to the other.) The two core types that serve as the foundation of PPL are task_handle and task_group. Both of these are shown in Figure 5 .
Figure 5 task_handle and task_group
template <class _Func>
class task_handle {
public:
task_handle(const _Func& f);
};
class task_group {
public:
task_group ();
task_group(tr1::function<void(exception_ptr)> Fn);
~task_group ();
template <class _Func> void run(const _Func& Fn);
template <class _Func> void run(task_handle<_Func>& t);
void cancel();
task_group_status wait();
void copy_exception(exception_ptr);
};
As an example of how these constructs can be used, consider a quicksort implementation as shown in David Callahan's article in this issue of MSDN Magazine (available at msdn.microsoft.com/magazine/cc872852). David's solution follows the typical quicksort pattern, falling back to a sort with less overhead when the length of the data being sorted is small enough, partitioning the data into two halves, and recursively using quicksort to sort each of the halves. The solution he shows uses parallel_invoke, but parallel_invoke is built on top of task_group, and an implementation that uses it directly might look something like this:
template<class T>
void QuickSort(T * data, int length, T* scratch) {
if(length < THRESHOLD) InsertionSort(data, length);
else {
int mid = Partition(data[0], data, length, scratch, true);
task_group g;
g.run([&]{QuickSort(data, mid);});
g.run([&]{QuickSort(data+mid, length-mid);});
g.wait();
}
}
Note that very little boilerplate was necessary to enable the implementation, simply creating a task_group, running each recursive call as a separate task, and then waiting on both to complete. That wait operation may not be a true kernel wait at all, instead preferring to inline a scheduled task onto the current thread rather than wasting that thread's resources.
Other core types are also provided. For example, the task_group type previously shown is thread-safe in that it enables multiple, unrelated threads to schedule tasks to it concurrently. For structured parallelism, where only tasks in parent/child relationships will ever schedule to the same group concurrently, the structured_task_group type provides optimized support for the same functionality.
As on the managed side, tasks are executed on an underlying and efficient scheduler. The scheduler uses work-stealing algorithms to enable efficient execution of fine-grained operations, supports cooperative blocking to enable efficient reuse of resources, provides detailed control over the policies employed by the scheduler for its operation, and more. Additionally, the scheduler has built-in support for primitives focused more on intra-process messaging than on fine-grained task execution.
One of the great concurrency features provided in the next version of Visual C++ is support for messaging and asynchronous agents. This gives developers an approach to writing parallel applications where they define coarse-grained components and enable them to interact. This interaction is accomplished through an in-process messaging infrastructure, allowing applications to tolerate latencies, to support component composition, and to utilize isolation as a mechanism for thread safety.
The core support revolves around several messaging functions (send, receive, asend, and try_receive) as well as ISource and ITarget interfaces that support being sent to and received from. The library includes several messaging blocks that implement these interfaces, such as unbounded_buffer, overwrite_buffer, single_assignment, choice, call, transform, and timer.
The system was also designed to encourage custom messaging blocks to be implemented as are necessary for the systems being developed. Messaging blocks support the ability to store messages and the ability to forward messages on to other message blocks. Blocks can be linked together, such that when messages arrive to one block, the block processes them as is appropriate to its semantics and then forwards on any resulting messages to blocks that have been linked to it in a network.
For example, the code in Figure 6 shows two unbounded_buffers, both linked to a join block, which is in turn linked to a transform block, which is in turn linked to a call block. When data arrives at both of the unbounded_buffers, that data will be passed through the join block to the transform block, which can manipulate the data with a developer-provided function and send the results to the call block, which will provide that data to another developer-provided method. (The messaging code samples shown use the currently intended syntax, which may differ slightly from that available in initial preview releases.)
Figure 6 Passing Messaging Blocks
unbounded_buffer<int> unboundedBuf1;
unbounded_buffer<int> unboundedBuf2;
join<int,int> join1;
transform<tr1::tuple<int,int>,int>
transform1([](tr1::tuple<int,int>& input){
return tr1::get<0>(input) * tr1::get<1>(input);
};
call<int> call1([](int& input){
cout << "result: " << input << endl;
};
unboundedBuf1.link_target(join1);
unboundedBuf2.link_target(join1);
join1.link_target(transform1);
transform1.link_target(call1);
Agent-based apps can also benefit from the new agent_task class, which is in effect a dedicated thread from the scheduler that is meant to interact with other tasks by sending and receiving messages. Agent_task can be quite useful in producer/consumer designs.
For example, consider the code at the top of Figure 7 , a simple log file parser that continually reads lines of text from a log file and processes them. That processing can be overlapped with the I/O for reading the file by having one thread dedicated to reading the file and another dedicated to processing its contents, as shown at the bottom of the figure. An unbounded_buffer is created for storing the messages sent from the reader to the parser, and the parser agent is spun up to continually receive from the buffer and process the resulting message. Meanwhile, as in the sequential example, the ParseFile method opens the file and reads lines from it, but rather than directly parsing each line, it simply sends each to the unbounded_buffer for the parser agent to consume. When the file has been completely read, it sends an exit message to the parser agent and waits for the agent to complete.
Figure 7 Parsing a File with Agents
Sequential
HRESULT LogChunkFileParser::ParseFile() {
HRESULT hr = S_OK;
WCHAR wszLine[MAX_LINE] = {0};
hr = reader->OpenFile(pFileName);
if (SUCCEEDED(hr)){
while(!reader->EndOfFile()){
hr = reader->ReadLine(wszLine, MAX_LINE);
if (SUCCEEDED(hr)){
Parse(wszLine);
}
}
}
return S_OK;
}
Parallel
HRESULT LogChunkFileParser::ParseFile() {
unbounded_buffer<AgentMessage> msgBuffer =
new unbounded_buffer<AgentMessage>();
agent_task* pParserAgent = agent_task::start([&] {
AgentMessage msg;
while((msg = receive(msgBuffer))->type != EXIT) {
Parse(msg->pCurrentLine);
delete msg->pCurrentLine;
}
});
HRESULT hr = reader->OpenFile(pFileName);
if (SUCCEEDED(hr)){
while(!reader->EndOfFile()) {
WCHAR* wszLine = new WCHAR[MAX_LINE];
hr = reader->ReadLine(wszLine, MAX_LINE);
if (SUCCEEDED(hr)) {
send(msgBuffer, AgentMessage(wszLine));
}
}
send(msgBuffer, AgentMessage(EXIT));
hr = agent_task::wait_for_completion(pParserAgent);
}
return hr;
};
As you can see, there's a great deal of useful functionality on its way to the development platform, for both native and managed code developers. However, it's worth pointing out that all of these new constructs are not a panacea. Much of this support is focused on enabling developers to more easily express parallelism in their applications, to remove the boilerplate that was previously necessary in doing so, and to aid in the replacement of sequential programming constructs with parallel ones. Yet constructs like parallel_for and AsParallel don't automatically make your code safe to run in concurrent contexts; race conditions, deadlocks, and the like are all still possible, and by making it so much easier to develop parallel applications, such issues will likely become even more common.
Debugging Parallel Applications
The challenges in parallel programming are not limited to programming models. Tool support is a critical ingredient in a successful platform for parallel programming. This is due to the increased complexity that developers face in debugging and performance tuning parallel applications. Thus, Visual Studio is investing in improving tool support for parallel programming on both the legacy and new programming models.
This is not to say that the tools in Visual Studio 2008 don't already offer support for multithreading. In fact, Visual Studio 2008 sports several useful features to aid in the development of multithreaded applications.
For example, an interesting dilemma for a debugging tool for parallel applications is the nature of breakpoint semantics as they relate to multiple execution contexts. Specifically, the question is whether to stop all execution contexts or just the one that encounters a breakpoint. The default behavior is typically to stop all threads at a breakpoint; however, it is sometimes desirable to allow one or more other execution contexts, such as threads, to proceed even when another thread is at a breakpoint. You can imagine how such a capability might be very useful in situations where race conditions do not manifest themselves with an all-blocking debugger implementation. The debugger offers a feature to freeze and thaw threads as users see fit. Initially, when a breakpoint is hit, all threads stop. At this point, a user may choose to thaw a subset of threads before proceeding with the debugging session. The user is also able to freeze threads as she sees fit.
However, there is still much more that needs to be done to improve productivity while developing and debugging parallel applications. Programming models such as those provided by TPL and PPL reduce the complexity threshold for developing well-performing parallel applications. A common theme for these programming models is the existence of a runtime system that abstracts away the details of partitioning work, scheduling it, and adding any necessary synchronization to ensure proper ordering constraints are met. In fact, a primary goal of these models is that developers no longer need to think about parallelism at the thread level, instead thinking about it at the fine-grained task level and higher.
Additionally, while having a runtime that does automatic parallelization eases the burden on the developer by removing the need to write all of the boilerplate code, it also means that the runtime chooses how to partition work, potentially into many thousands of tasks that are divided among many virtual processors that are further mapped onto an execution abstraction such as a thread. From a developer's perspective, if there's a need to debug the execution of individual tasks, it may be difficult, if not impossible, to trace the path of execution that led to a certain piece of code. This creates a dichotomy between the programming model and the debugger, which today focuses on threads.
Two new features in the next version of Visual Studio, MultiStack and a Task List views, are intended to address this difficulty by reducing the burden of debugging applications that make use of parallel programming runtimes.
The MultiStack view, as shown in Figure 8 , graphs the logical call stacks for all (or a selected set of) tasks, where a logical call stack is one in which a child task's stackframes are linked back through its parent. The view coalesces common stack prefixes into a single node and tags the node with a count of the tasks sharing the prefix. Thus the graph presents a global view of the execution state of the set of tasks. The user can then traverse the call stacks of any running task at a breakpoint and switch to show the particular instance of a method in the editor.
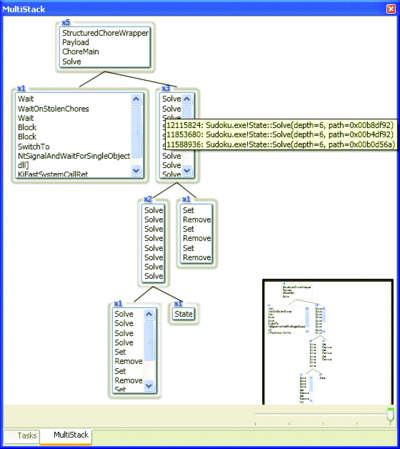
Figure 8 MultiStack (Click the image for a larger view)
The Task List in Figure 9 shows all tasks known to the runtime system at a breakpoint, their respective execution states, as well as the method currently being executed, with a list of arguments and their values. The list may be sorted, grouped by, or searched on any column, and it allows a developer to quickly switch among tasks and use the various other debugger features to further examine execution state.
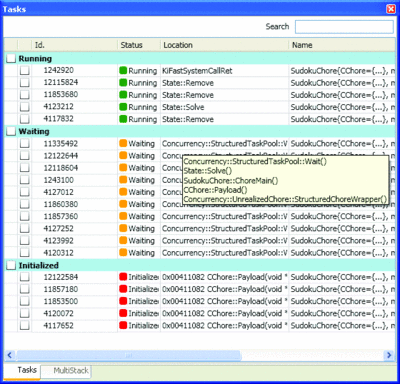
Figure 9 Task List (Click the image for a larger view)
Another challenging area in parallel programming, especially in a shared memory platform, is the ability to examine memory contents within multiple execution contexts simultaneously, while providing the usual expression evaluation capability efficiently. The next version of Visual Studio includes a MultiWatch view that specifically addresses this need. This feature allows the developer to add variable names and expressions to a watch window, where the expressions are evaluated at each debugger step or breakpoint and for every thread or task in the system. This makes it much easier to spot inconsistencies in data across threads in order to find problem areas and causes of otherwise insidious bugs.
Profiling Parallel Applications
Parallelism is all about performance (whether responsiveness or throughput), so a good set of performance analysis tools is critical to a platform's success. Exploiting parallelism for compute-bound operations can be challenging, but it is definitely less daunting than the task of parallelizing complex client applications. The added complexity is due to the fact that rich client applications include phases of varying bottlenecks, including disk and network I/O.
From a developer's perspective, the key to parallelizing such applications is to understand enough of their behavior to identify opportunities for parallelism. Once that is done, the developer can apply many of the programming patterns and abstractions available to accomplish the job. A key point to remember during this phase is that concurrency can be a technique for hiding latency, not just for speeding up computation. Once the application is written, there are additional sources of inefficiency (such as synchronization) that need to be understood, measured, and tuned in order to arrive at a well-performing solution.
The performance analysis tools in Visual Studio 2008 offer a significant number of features to aid developers of managed and native applications in their tuning efforts. The existing profiler supports sampling and instrumentation based profiling. Sample profiling intercepts the application program at user-defined intervals, captures a call stack per thread, and continues execution. At analysis time, all the call stacks are collected and collated to identify the functions where most samples were taken, along with the application paths that lead there.
One drawback of this technique is that it does not account for time during which the application's threads are blocked due to synchronization or I/O calls. As a result, sample profiling is recommended only for CPU-bound applications.
Besides sampling on-time intervals, the Visual Studio profiler allows sampling on other important events such as page faults or microprocessor performance monitoring counters (for example, L2 cache misses). These capabilities can be extremely valuable tools for understanding important aspects of application behavior such as cache and/or memory page locality. (See the .NET Matters column in this issue of MSDN Magazine at msdn.microsoft.com/magazine/cc872851 for further exploration of this topic.)
Instrumentation-based profiling, as the name implies, works by augmenting the code of each function in the target application or module. Such instrumentation is typically inserted at the entry and exit points of the function, including any call sites to other methods. This level of instrumentation allows the profiler to account for all delays in the application's execution, albeit at the expense of a significantly higher execution time and trace logging overhead. These overheads can significantly perturb execution and increase the time needed to analyze data. To reduce such overheads, the Visual Studio profiler allows users to partially instrument the application at the granularity of a function or a module (DLL). In addition, the profiler provides an API that allows programmers to tailor performance data collection during execution time.
From a parallel programmer's perspective, the current profiler experience lacks several features that are desirable such as higher-level support for the new parallel programming runtimes, as well as specific scenarios that address common parallel performance issues, such as synchronization. In the next version of Visual Studio, the profiler is augmented with tools that specifically address the needs of multithreaded application developers.
A crucial step in parallel development is understanding the degree of concurrency or the potential for performance improvement using parallelism in an application. This is important both prior to implementing parallelization and during tuning phases.
When examining an application that is a target for parallelism, it is necessary to determine the phases of the application that are candidates for parallelization. Usually, those phases are CPU bound, but there are currently no tools to easily determine such phases of execution and map them to application code.
The next release of Visual Studio will include concurrency analysis support, as shown in Figure 10 . With time on the x-axis and the number of cores in the system on the y-axis, the graph shows how core utilization varies with time for the application of interest (shown in green). This view allows users to determine the phases of an application that are CPU bound, their relative durations and the level of system core utilization, then to zoom in on them to determine what the application was doing during those phases to start considering the forms of parallelism that may exist and how they may be exploited. During the performance-tuning phase, this view can confirm whether the expected concurrency is indeed observed during execution time.
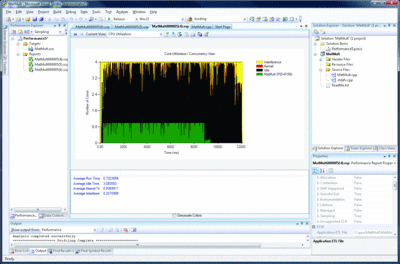
Figure 10 Concurrency Analysis (Click the image for a larger view)
In addition, basic timing measurements can be made to estimate speed improvements achieved compared to a previous or sequential execution. Finally, the concurrency view also gives the user an idea of the interaction between the application in question and other processes in the system, or the kernel. In the view, idle time is shown in black, while other non-kernel processes are shown in yellow. Kernel activity (minimal in this example) is shown in red.
Once the developer has identified a phase of interest using the Concurrency View, she can then further analyze the behavior of the application using a Thread Blocking View, shown in Figure 11 . This view provides a wealth of information about the behavior of each thread in the application.
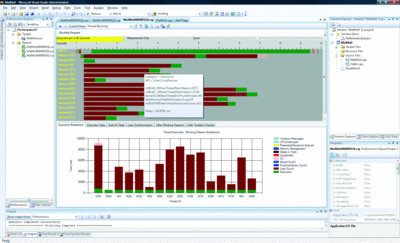
Figure 11 Thread Execution and Blocking Analysis (Click the image for a larger view)
First, it generates a bar graph with an execution breakdown of each thread, depicting the fraction of each thread's lifetime that was spent executing code or blocking. Blocking delays are further broken down into various categories, such as I/O or synchronization.
Second, the view provides a timeline view with time on the x-axis and threads and physical disk I/O as lanes on the y-axis. For disk I/O, the display shows reads and writes as they occur in time on disk, as well as the files being accessed using tooltips. For threads, it shows when they are executing, when they are blocked, and for what category of delay using colors.
Third, call stack analysis allows the developer to hover over any blocking segment in the timeline view to understand in detail what each thread was doing when it was blocked. The screenshot in Figure 11 shows an example where the mouse is hovering over a synchronization blocking segment that is about 83ms long due to a call to EnterCriticalSection. It also shows the call stack, including line numbers, that resulted in the blocking attempt to acquire the critical section. Such details are crucial to allow developers to examine the root cause of an inefficiency and address it. Other features include detailed execution, blocking, and disk I/O statistics and reports that are available in the lower tabs.
Another important aspect of parallel performance analysis is thread migration due to its interaction with cache working sets. In Figure 12 we show the Core Execution and Thread Migration view, in which we associate a unique color with each thread, and then we display how the threads are scheduled to execute on the system's processor cores. A thread migration event would be graphically depicted by a color moving across cores. For each thread migration event that we are interested in, we can identify it in an application phase, make a note of the thread ID by hovering over the thread involved, and then switch to the thread blocking view. The thread blocking view can then illustrate the nature of the blocking event preceding the thread migration and indicate where it occurred in the app. The developer can then decide whether to optimize this type of problem by either reducing that class of blocking events and/or enforcing affinity if that is deemed to be acceptable for the app's execution environment.
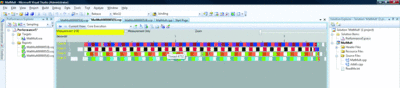
Figure 12 Core Execution and Thread Migration (Click the image for a larger view)
Looking Forward
At the time of this writing, no dates have yet been announced for when the next version of Visual Studio, which contains all of the aforementioned concurrency support, will be released. Nevertheless, very soon managed and native developers alike will be given the ability to effectively develop applications that efficiently utilize all of the computing power multicore systems have to offer. With such systems quickly becoming the standard in the enterprise and in the home, the time to start learning about such support is now.
Thanks to Rick Molloy, David Callahan, and Paul Maybee for their assistance with this article.
Stephen Toub is a Senior Program Manager Lead on the Parallel Computing Platform team at Microsoft, where he focuses his efforts on programming models for concurrency. He is also a Contributing Editor for MSDN Magazine .
Hazim Shafi is a Principal Architect responsible for performance tools on the Parallel Computing Platform team at Microsoft. He also teaches courses on parallel programming at Microsoft.