span.sup { vertical-align:text-top; }
CLR Inside Out
Unhandled Exception Processing In The CLR
Gaurav Khanna
Please note that although referenced in the print version of this article, there is no code download.
Contents
Managed Exception Handling
Thread Base and Unhandled Managed Exceptions
Unhandled Managed Exceptions on CLR-Created Threads
Unhandled Exceptions on Non-CLR-Created Threads
Unhandled Exception Processing
AppDomain.UnhandledException Event Notification
Future Concerns
Unhandled exception processing shouldn't be a mystery. It's actually quite useful to understand what happens during the process since it gives a crashing application an opportunity to perform last-minute diagnostic logging about what went wrong. This diagnostic information is valuable and may save you time in understanding the crash.
So what is unhandled exception processing? It's a phase of the regular exception processing mechanism that is only triggered for an exception after all of the thread's stack frames have been searched for an exception handler and none has been found.
Here I will be discussing how unhandled exception processing for managed exceptions is implemented by the CLR. But before I get into its specifics, let's see how managed exception handling works in general.
Note that I am assuming that you are familiar with the Windows ® Structured Exception Handling (SEH) mechanism and related concepts. To learn more about them, you may want to refer to this excellent article by Matt Pietrek, "A Crash Course on the Depths of Win32 Structured Exception Handling," available at microsoft.com/msj/0197/Exception/Exception.aspx .
Managed Exception Handling
The managed programming model uses the concept of exceptions to notify callers up the stack about error conditions during run time. Typically, the caller of a method would know what kind of exception the method may throw (or raise), and, accordingly, the call is made from within the confines of a try block with an associated catch block or a managed filter with a handler block.
When an exception is thrown by managed code (or one is raised asynchronously, like an access violation in unsafe managed code), the CLR will begin walking the managed stack from the first managed frame it finds closest to the point of the exception and will begin looking for a managed exception handler.
Unless otherwise noted, the stack grows downward and each row represents a managed frame that calls into the frame below it. If a managed frame calls into a native one, the native frame will be explicitly called out. The topmost frame is the entry point frame and the bottommost frame is the one most recently executing code.
Figure 1 is an example of one such call stack. Here, Bar throws an exception, and thus the CLR will start walking the managed stack from Bar all the way up to Main, looking for an exception handler. In this example, Main serves as the entry point managed frame for the thread in question.

Figure 1 Bar Throws an Exception
The diagram in Figure 2 shows another call stack where the managed code in Bar calls, using P/Invoke, into native function Nfunc, which throws an exception (for example, throws a C++ exception). Since the exception happened in native code, the CLR remains unaware of it unless the exception is not caught in the native function and reaches the managed Bar method. In such a case, the CLR will create a managed exception object corresponding to the native exception and will start looking for exception handlers starting from the frame containing Bar and continuing all the way up to the Main method.
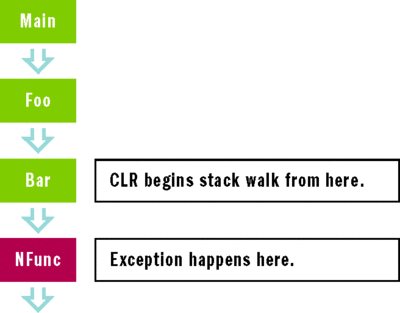
Figure 2 Nfunc Throws an Exception
In the two examples, the exception handler could be either a catch block that matches the thrown exception's managed type per the type-matching rules, or a managed filter that agrees to handle the exception after examining the exception object passed to it by the CLR.
For this example, let's assume that Main has a catch block to handle the exception. When it is found, but before execution is resumed inside it, the CLR initiates the exception unwind operation (also known as the second pass in SEH terms) to invoke the finally clauses all the way from the point where the exception was raised to the point just before the exception handler that agreed to handle the exception. For managed frames, this also results in the invocation of the fault clauses if they are present. You may refer to the ECMA 335 specification (see go.microsoft.com/fwlink/?LinkId=121873 ) for specific details on fault clauses and managed exception handling in general.
Under typical scenarios, the finally/fault blocks will execute and perform required cleanup. Once all such blocks are executed, the CLR will resume execution in the catch block (or the handler block for a managed filter) that agreed to handle the exception.
Thread Base and Unhandled Managed Exceptions
In the previous examples, I had defined Main as the entry point managed frame for the thread—in other words, it is the first managed frame the thread will execute. If a managed exception handler is not found in it, the CLR will proceed to trigger its unhandled exception process. How this unhandled exception processing is triggered depends on how the thread was created. Let's delve into this topic a bit more.
Threads that can run managed code can be classified into two types. There are threads that are created by the CLR, and for such threads, the CLR controls the base (the starting frame) of the thread. The stack shown inFigures 1 and 2 is an example of this scenario. Figure 3 shows the true stack of such a thread when it starts within the CLR.

Figure 3 Thread Created by the CLR
There are also threads that are created outside the CLR but enter it at some later point to execute managed code; for such threads, the CLR does not control the thread base. The diagram in Figure 4 exemplifies this case.
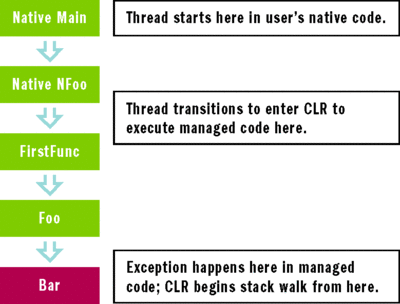
Figure 4 Thread Created outside the CLR
Unhandled Managed Exceptions on CLR-Created Threads
In the case of Figure 3 , if the CLR can't find a managed exception handler in Main, the exception will reach the native frame within the CLR where the thread started. In this frame, the CLR has established an exception filter that will apply the policy to swallow (which is semantically equivalent to blindly catching) exceptions, if applicable. If the policy indicates not to swallow the exception (which is the default in the Microsoft ® .NET Framework 2.0 and later), the filter triggers the CLR's unhandled exception processing.
At this point, you will likely want to know what kind of threads belong to the case depicted in Figure 3 and what the exception- swallowing policy is. The answer to the first question is easy: any managed threads you create using the System.Threading.Thread class belong to this category. Additionally, the Finalizer thread and CLR thread pool threads also belong here. The only exception is a managed thread that is created in the default domain. Though such a thread would check the exception-swallowing policy, it will follow the same pattern as the thread in Figure 4 from the perspective of triggering unhandled exception processing, assuming the exception is not swallowed.
The answer to the second question requires knowing a bit of the history of exception handling. In the .NET Framework 1.0 and 1.1, unhandled exceptions on threads that were created within the CLR were swallowed at the thread base (in other words, the native function at which the thread started in the CLR). In retrospect, this behavior could have been just the opposite since the CLR has no clue about the reason the exception was raised in the first place. Thus, swallowing such an exception, which none of the managed frames on the stack wanted to handle, is a mistake since the extent of application or process state corruption cannot be determined.
What if the exception was the kind that would indicate a corrupted process state such as Access Violation, for instance? Unless you are working with unsafe managed code, there is no sense in swallowing such an exception. Most importantly, swallowing exceptions hides from the developer what actually went wrong in the application.
Thus, in the .NET Framework 2.0, this behavior was changed. Unhandled exceptions on threads created by the CLR are no longer swallowed. If the exception is not handled by any managed frame on the stack, the CLR will let it go unhandled to the OS after triggering the unhandled exception process. The unhandled exception, then, will result in an application crash, and the details of the crash will help the developer to understand what went wrong.
However, since certain applications built for the CLR 1.0 and 1.1 relied on the original behavior of swallowing unhandled exceptions, and subsequently wouldn't work as expected against CLR 2.0, a flag was introduced that could be set in the application configuration file's runtime section, as you see here:
<legacyUnhandledExceptionPolicy enabled="1"/>
Once set, exceptions would be swallowed just like they were in the CLR 1.0 and 1.1. This constitutes the exception swallowing policy of the CLR. If this policy is not applied, the CLR will proceed to trigger unhandled exception processing.
As you may have deduced, then, unhandled exceptions are good in that they will help you better understand the reason for a crash. In fact, this should also indicate to you that using patterns like catch(Exception ex) are bad since they imply that you will catch any managed exception, which is semantically similar to what the CLR did in versions 1.0 and 1.1. Such patterns should be replaced with those that have a more specific exception type and should be as close to the source of the exception as possible. The further away you catch the exception from the point it was raised, the less context you will have about the cause of the exception.
Unhandled Exceptions on Non-CLR-Created Threads
Figure 4 illustrated the case of a thread that was created outside the CLR and later entered in to execute managed code. In the example, if the exception was not handled even in the FirstFunc method, the exception would exit the CLR but continue to propagate up the stack as a native SEH exception (managed exceptions are represented as native SEH exceptions). This propagation is performed by the OS as it goes about looking for an exception handler. Examples of such threads include the entry point thread (a native thread that calls into managed code using a pointer to a delegate), native threads that use COM interop, or the CLR Hosting API.
In this case two things can happen. First, the OS could find an SEH exception handler in one of the native frames in the user (or CLR) code. This would result in a second pass of SEH exception handling to run the finally clauses from the frame in which the exception was raised all the way up to the point just before the exception handler that agreed to handle the exception. Once that step is complete, execution is resumed in the exception handler (for example, a catch clause) that caught the exception. Native threads that enter the CLR using the hosting API or COM interop to execute managed code fall into this category.
The second possible outcome is that the OS will not be able to find an SEH exception handler even in the top-most native frame in user code. If this happens, the exception is deemed unhandled and the OS triggers its own unhandled exception processing mechanism that the CLR relies on to, in turn, trigger its unhandled exception processing. Native threads that invoke managed delegates outside the protection of any native exception handling, using the pointer obtained from the Marshal.GetFunctionPointerForDelegate managed API, fall into this category.
The OS unhandled exception filter (UEF) mechanism may not always result in triggering the CLR's unhandled exception processing. Before I explain, let's see how the OS's UEF mechanism works.
Unhandled Exception Processing
Windows exposes the mechanism of registering a process-wide callback called the UEF that will be invoked by the OS whenever any thread that is in the process has an exception of any type that goes unhandled.
This callback can be registered using the SetUnhandledExceptionFilter Windows API. When a component in the process registers its callback, the OS returns the address of the last callback that was registered with it (or NULL if there was none). Note that this means that the OS tracks only the most recently registered UEF callback.
If the callback determines it cannot process the exception, it is expected that the component that got the callback will invoke the previously registered callback using the pointer the OS returned when SetUnhandledExceptionFilter was used. Similarly, that callback is expected to call into its predecessor, and so on.
This process of invoking the previously registered callback is known as the chaining back of unhandled exception filters. By nature, this chain is weak since it can be easily broken if one of the components in the chain does not chain back (or, for instance, terminates the process). This has an important implication for the CLR's unhandled exception processing. When the CLR is initializing, it registers its UEF callback with the OS as well, in the hope that it will be invoked when a managed exception goes unhandled on a thread that was created outside the CLR.
Under normal circumstances, this will work as expected and the CLR's unhandled exception processing will be triggered. However, in certain instances this may not happen. One such case is when the managed code makes a P/Invoke call into a native component that registers its UEF callback with the OS. Assuming the CLR was the last one to register a UEF callback prior to the native component, this component will get the address of the CLR's callback. Now, when an exception goes unhandled on the thread, the OS will invoke the UEF callback of the native component (since it is the latest registration). If this component does not call back into the CLR's UEF callback (using the pointer the OS gave it), then the CLR's unhandled exception processing will not be initiated.
Another case in which the CLR's unhandled exception processing will not be triggered is when a native component registers its UEF callback and then loads the CLR (either via COM interop or explicitly via CLR hosting). In that case the CLR will register its UEF callback and save the original one.
When an exception goes unhandled and the OS invokes the topmost UEF, it will end up invoking the CLR's UEF callback. When this happens, the CLR will behave like a good citizen and will first chain back to the UEF callback that was registered prior to it. Again, if the original UEF callback returns indicating that it has handled the exception, then the CLR won't trigger its unhandled exception processing. Thus, if you see that the CLR's unhandled exception processing is not being triggered, you have likely encountered one of these two scenarios.
So far, you have seen how the base of the thread executing managed code influences how the CLR's unhandled exception processing is triggered. But what happens during the CLR's unhandled exception processing? There are essentially three parts to that process, which I'll explain next. At a high level, though, the process notifies the crashing application about the exception that went unhandled and the CLR triggers some mechanisms to log details about the crash.
AppDomain.UnhandledException Event Notification
The AppDomain class exposes an event that is known as UnhandledException. This event is triggered when an exception goes unhandled on a thread executing managed code and the CLR's unhandled exception processing is triggered ("and" is the key word here since there are scenarios in which it may not be triggered at all, as I explained earlier).
This event is always raised for the default domain. Additionally, if the thread was created in the CLR and in a non-default AppDomain, this notification will be delivered to that AppDomain as well.
When the CLR's unhandled exception processing is triggered, the process is close to termination since the exception has gone unhandled all the way up the thread's stack. Thus, this is the last chance to do some sort of logging about what went wrong. The event handler gets the exception object pertaining to the unhandled exception so that it can be used for the diagnosis of the failure. The code in Figure 5 registers for and uses this notification.
Figure 5 Register for Notification
class Program
{
static void Main(string[] args)
{
AppDomain.CurrentDomain.UnhandledException += new
UnhandledExceptionEventHandler(CurrentDomain_UnhandledException);
throw new Exception("This will go unhandled");
}
static void CurrentDomain_UnhandledException(object sender, UnhandledExceptionEventArgs e)
{
Exception ex = (Exception)e.ExceptionObject;
Console.WriteLine("Observed unhandled exception: {0}", ex.ToString());
}
}
Next, the CLR will collect the managed bucket details pertaining to the unhandled exception and write them to the event log (under the Application Log), as shown in Figure 6 .
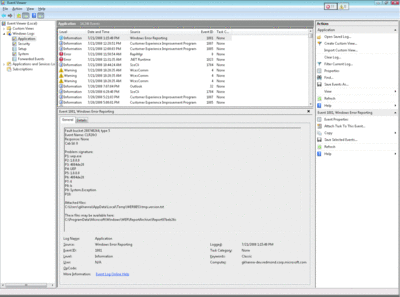
Figure 6 Exceptions in the Event Log
Bucketing is the process that groups crashes of applications based upon the point of crash. In case of unhandled managed exceptions, it is based upon nine details that the CLR collects pertaining to the managed exception that went unhandled. These are collectively known as the Watson buckets, and in the context of managed code they include details such as the name of the module that was responsible for the crash, the intermediate language (IL) offset at which the crash happened, and the MethodDef of the method in which the crash happened (for details, see the ECMA 335 specification). For instance, bucket P4 describes the faulting module, bucket P9 displays the type of exception that went unhandled, and bucket P8 represents the IL offset at which the exception was originally thrown.
Figure 7 shows the disassembly of the managed method that raised the unhandled exception leading to the bucket details shown in Figure 6 . You will see that the IL offset (P8) in Figure 6 will match the IL offset at which the exception was thrown in Figure 7 .
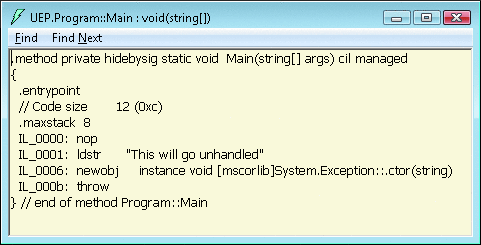
Figure 7 Disassembled Method
The thing you need to keep in mind here is that the information in the buckets corresponds to the last managed exception that was thrown and went unhandled. This statement is important since exceptions can be rethrown or packaged as an inner exception of a new exception that is thrown and goes unhandled. They could have also been thrown originally in a non-default AppDomain into which the thread transitioned.
In the first two cases (rethrown and packaged as an inner exception), it will be the IL offset of the rethrow or the throw of the new exception that will be used in bucketing. The third case I mentioned is special since it's based upon the fact that objects created in one AppDomain cannot be used in another AppDomain unless they are marshaled (the CLR's way of transforming objects for use across various boundaries such as AppDomains). Thus, when an exception thrown in an AppDomain remains unhandled and reaches an AppDomain transition boundary, the CLR will marshal the exception object from the AppDomain where it was raised into the AppDomain from where the call originated and raise the exception using the marshaled exception object.
As a result, the IL offset in the P8 bucket will belong to the first managed frame in the calling AppDomain that sees the exception. Simply put, this will typically be an offset in the method where the AppDomain transition was initiated on the thread.
A CLR host is able to retrieve the bucket parameters for the current exception on the thread by using the ICLRErrorReportingManager::GetBucketParametersForCurrentException hosting API.
Finally, at this point you would typically see a dialog that will prompt you to debug or close the application. Clicking Close Program would terminate the process, while clicking on Debug would launch the managed just-in-time (JIT) debugger that is specified in the DbgManagedDebugger entry under the HKLM\Software\Microsoft\.NetFramework registry key.
In the final step of the CLR's unhandled exception process, the CLR will attempt to display details pertaining to the exception that went unhandled on the standard error console. Typically, you will see the managed stack trace dump.
If the exception is a more serious one (such as a StackOverflowException or OutOfMemoryException), a simple string is displayed in the place of the stack dump. This is done because you may not have enough stack to execute or memory to form the extensive stack trace to display on the console. If the CLR is not cautious in such a situation, it could run into a recursive exception scenario. Once the process is complete, the CLR's unhandled exception processing mechanism returns control to its caller, which may be either the OS or the CLR itself.
Future Concerns
This column is based on the version of the CLR that ships with the .NET Framework 2.0 and thus may have touched on some implementation details that could possibly change in the future. However, my goal here wasn't to have you focus on the implementation but rather help you to try and understand the bigger picture of unhandled exception processing.
Now you should understand what constitutes unhandled exception processing, its dependencies, and how it relates to the OS UEF mechanism. This knowledge will help you design better exception handling strategies and diagnostics mechanisms in your applications for any unexpected crashes you may encounter.
Send your questions and comments to clrinout@microsoft.com .
Gaurav Khanna is a Software Development Engineer on the CLR team at Microsoft where he works on managed exception handling implementation and CLR Hosting.