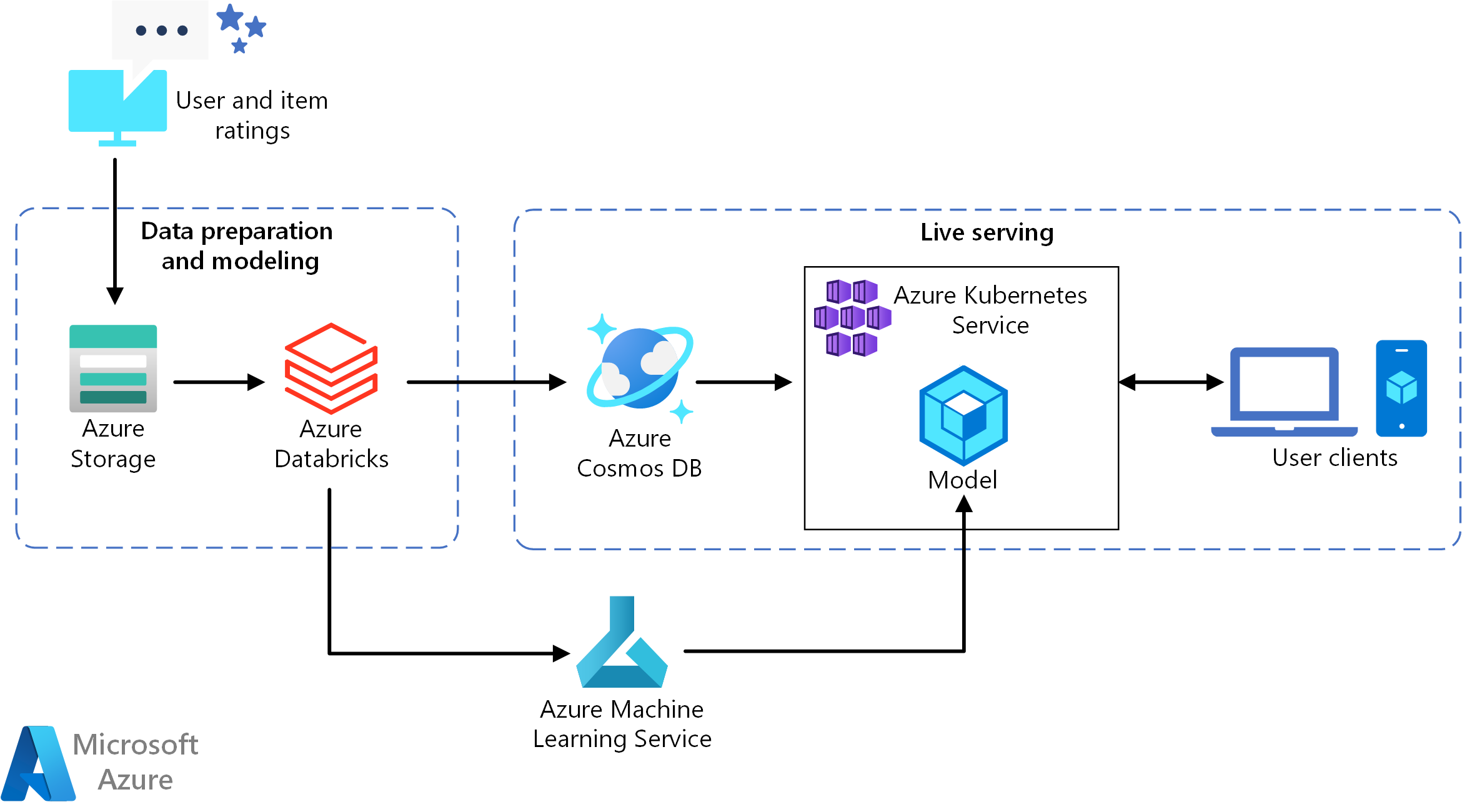
This reference architecture shows how to train a recommendation model by using Azure Databricks, and then deploy the model as an API by using Azure Cosmos DB, Azure Machine Learning, and Azure Kubernetes Service (AKS). For a reference implementation of this architecture see Building a Real-time Recommendation API on GitHub.
Architecture
Download a Visio file of this architecture.
This reference architecture is for training and deploying a real-time recommender service API that can provide the top 10 movie recommendations for a user.
Dataflow
- Track user behaviors. For example, a back-end service might log when a user rates a movie or clicks a product or news article.
- Load the data into Azure Databricks from an available data source.
- Prepare the data and split it into training and testing sets to train the model. (This guide describes options for splitting data.)
- Fit the Spark Collaborative Filtering model to the data.
- Evaluate the quality of the model using rating and ranking metrics. (This guide provides details about the metrics that you can use to evaluate your recommender.)
- Precompute the top 10 recommendations per user and store as a cache in Azure Cosmos DB.
- Deploy an API service to AKS using the Machine Learning APIs to containerize and deploy the API.
- When the back-end service gets a request from a user, call the recommendations API hosted in AKS to get the top 10 recommendations and display them to the user.
Components
- Azure Databricks. Databricks is a development environment used to prepare input data and train the recommender model on a Spark cluster. Azure Databricks also provides an interactive workspace to run and collaborate on notebooks for any data processing or machine learning tasks.
- Azure Kubernetes Service (AKS). AKS is used to deploy and operationalize a machine learning model service API on a Kubernetes cluster. AKS hosts the containerized model, providing scalability that meets your throughput requirements, identity and access management, and logging and health monitoring.
- Azure Cosmos DB. Azure Cosmos DB is a globally distributed database service used to store the top 10 recommended movies for each user. Azure Cosmos DB is well-suited for this scenario, because it provides low latency (10 ms at 99th percentile) to read the top recommended items for a given user.
- Machine Learning. This service is used to track and manage machine learning models, and then package and deploy these models to a scalable AKS environment.
- Microsoft Recommenders. This open-source repository contains utility code and samples to help users get started in building, evaluating, and operationalizing a recommender system.
Scenario details
This architecture can be generalized for most recommendation engine scenarios, including recommendations for products, movies, and news.
Potential use cases
Scenario: A media organization wants to provide movie or video recommendations to its users. By providing personalized recommendations, the organization meets several business goals, including increased click-through rates, increased engagement on its website, and higher user satisfaction.
This solution is optimized for the retail industry and for the media and entertainment industries.
Considerations
These considerations implement the pillars of the Azure Well-Architected Framework, which is a set of guiding tenets that can be used to improve the quality of a workload. For more information, see Microsoft Azure Well-Architected Framework.
Batch scoring of Spark models on Azure Databricks describes a reference architecture that uses Spark and Azure Databricks to execute scheduled batch scoring processes. We recommend this approach for generating new recommendations.
Performance efficiency
Performance efficiency is the ability of your workload to scale to meet the demands placed on it by users in an efficient manner. For more information, see Performance efficiency pillar overview.
Performance is a primary consideration for real-time recommendations, because recommendations usually fall in the critical path of a user request on your website.
The combination of AKS and Azure Cosmos DB enables this architecture to provide a good starting point to provide recommendations for a medium-sized workload with minimal overhead. Under a load test with 200 concurrent users, this architecture provides recommendations at a median latency of about 60 ms and performs at a throughput of 180 requests per second. The load test was run against the default deployment configuration (a 3x D3 v2 AKS cluster with 12 vCPUs, 42 GB of memory, and 11,000 Request Units (RUs) per second provisioned for Azure Cosmos DB).
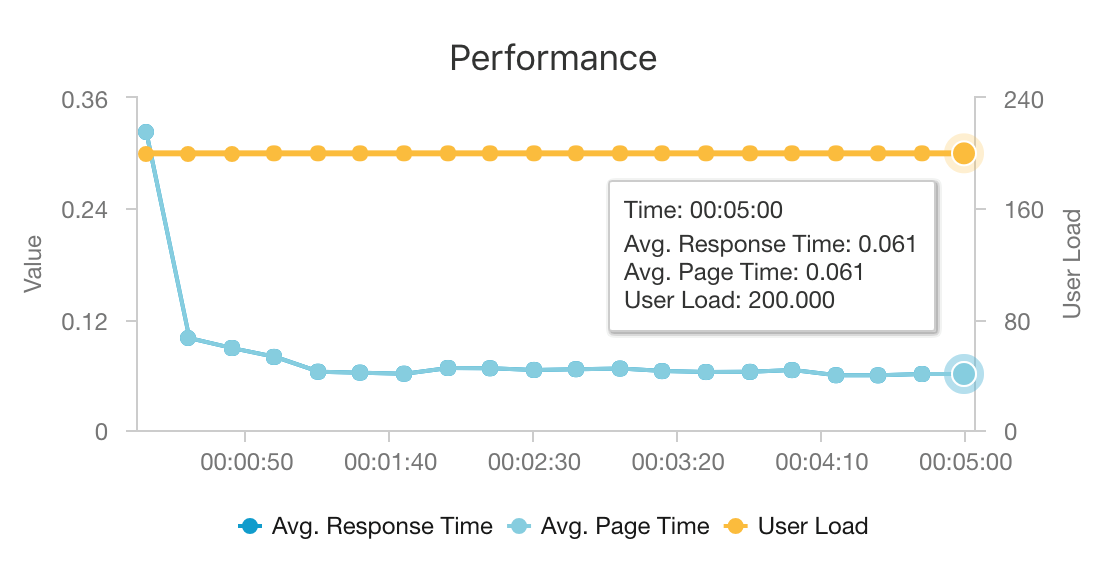
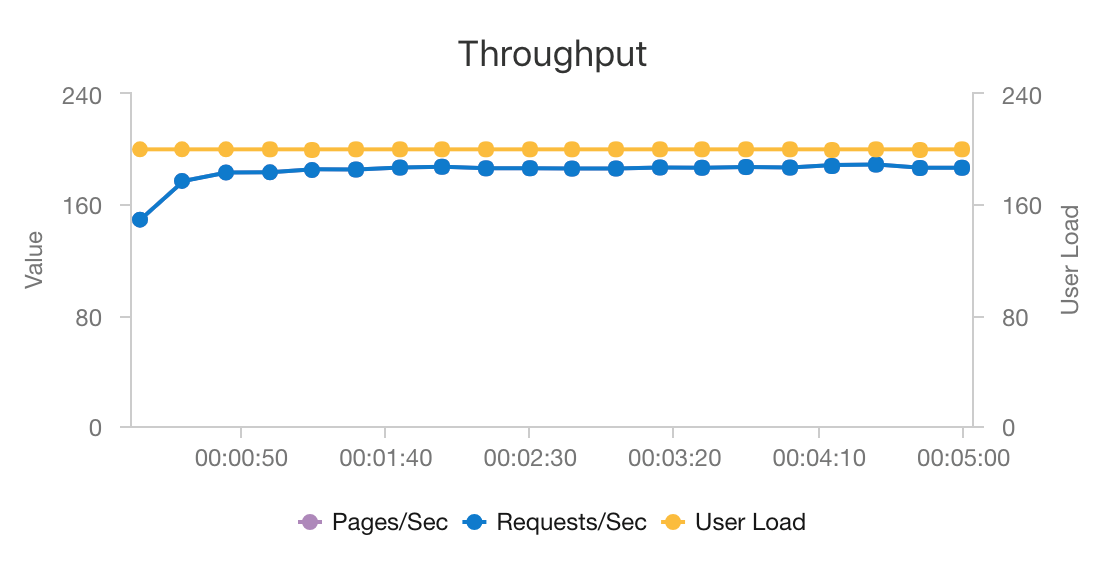
Azure Cosmos DB is recommended for its turnkey global distribution and usefulness in meeting any database requirements your app has. To reduce latency slightly, consider using Azure Cache for Redis instead of Azure Cosmos DB to serve lookups. Azure Cache for Redis can improve performance of systems that rely heavily on data in back-end stores.
Scalability
If you don't plan to use Spark, or you have a smaller workload that doesn't need distribution, consider using a Data Science Virtual Machine (DSVM) instead of Azure Databricks. A DSVM is an Azure virtual machine with deep learning frameworks and tools for machine learning and data science. As with Azure Databricks, any model you create in a DSVM can be operationalized as a service on AKS via Machine Learning.
During training, either provision a larger fixed-size Spark cluster in Azure Databricks, or configure autoscaling. When autoscaling is enabled, Databricks monitors the load on your cluster and scales up and down as needed. Provision or scale out a larger cluster if you have a large data size and you want to reduce the amount of time it takes for data preparation or modeling tasks.
Scale the AKS cluster to meet your performance and throughput requirements. Take care to scale up the number of pods to fully utilize the cluster, and to scale the nodes of the cluster to meet the demand of your service. You can also set autoscaling on an AKS cluster. For more information, see Deploy a model to an Azure Kubernetes Service cluster.
To manage Azure Cosmos DB performance, estimate the number of reads required per second, and provision the number of RUs per second (throughput) needed. Use best practices for partitioning and horizontal scaling.
Cost optimization
Cost optimization is about looking at ways to reduce unnecessary expenses and improve operational efficiencies. For more information, see Overview of the cost optimization pillar.
The main drivers of cost in this scenario are:
- The Azure Databricks cluster size required for training.
- The AKS cluster size required to meet your performance requirements.
- Azure Cosmos DB RUs provisioned to meet your performance requirements.
Manage the Azure Databricks costs by retraining less frequently and turning off the Spark cluster when not in use. The AKS and Azure Cosmos DB costs are tied to the throughput and performance required by your site and will scale up and down depending on the volume of traffic to your site.
Deploy this scenario
To deploy this architecture, follow the Azure Databricks instructions in the setup document. Briefly, the instructions require you to:
- Create an Azure Databricks workspace.
- Create a new cluster with the following configuration in Azure Databricks:
- Cluster mode: Standard
- Databricks runtime version: 4.3 (includes Apache Spark 2.3.1, Scala 2.11)
- Python version: 3
- Driver type: Standard_DS3_v2
- Worker type: Standard_DS3_v2 (min and max as required)
- Auto termination: (as required)
- Spark configuration: (as required)
- Environment variables: (as required)
- Create a personal access token within the Azure Databricks workspace. See the Azure Databricks authentication documentation for details.
- Clone the Microsoft Recommenders repository into an environment where you can execute scripts (for example, your local computer).
- Follow the Quick install setup instructions to install the relevant libraries on Azure Databricks.
- Follow the Quick install setup instructions to prepare Azure Databricks for operationalization.
- Import the ALS Movie Operationalization notebook into your workspace. After signing in to your Azure Databricks workspace, do the following:
- Click Home on the left side of the workspace.
- Right-click on white space in your home directory. Select Import.
- Select URL, and paste the following into the text field:
https://github.com/Microsoft/Recommenders/blob/main/examples/05_operationalize/als_movie_o16n.ipynb - Click Import.
- Open the notebook within Azure Databricks and attach the configured cluster.
- Run the notebook to create the Azure resources required to create a recommendation API that provides the top-10 movie recommendations for a given user.
Contributors
This article is maintained by Microsoft. It was originally written by the following contributors.
Principal authors:
- Miguel Fierro | Principal Data Scientist Manager
- Nikhil Joglekar | Product Manager, Azure algorithms and data science
To see non-public LinkedIn profiles, sign in to LinkedIn.
Next steps
- Building a Real-time Recommendation API
- What is Azure Databricks?
- Azure Kubernetes Service
- Welcome to Azure Cosmos DB
- What is Azure Machine Learning?