Surrogate key transformation in mapping data flow
APPLIES TO:  Azure Data Factory
Azure Synapse Analytics
Azure Data Factory
Azure Synapse Analytics
Tip
Try out Data Factory in Microsoft Fabric, an all-in-one analytics solution for enterprises. Microsoft Fabric covers everything from data movement to data science, real-time analytics, business intelligence, and reporting. Learn how to start a new trial for free!
Data flows are available both in Azure Data Factory and Azure Synapse Pipelines. This article applies to mapping data flows. If you are new to transformations, please refer to the introductory article Transform data using a mapping data flow.
Use the surrogate key transformation to add an incrementing key value to each row of data. This is useful when designing dimension tables in a star schema analytical data model. In a star schema, each member in your dimension tables requires a unique key that is a non-business key.
Configuration
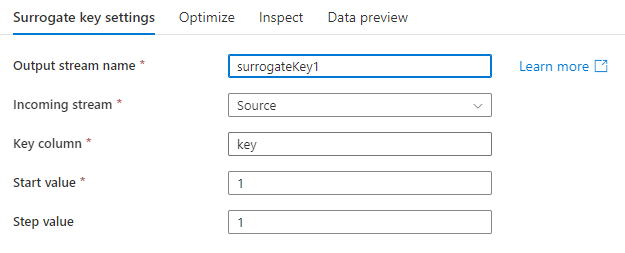
Key column: The name of the generated surrogate key column.
Start value: The lowest key value that will be generated.
Increment keys from existing sources
To start your sequence from a value that exists in a source, we recommend to use a cache sink to save that value and use a derived column transformation to add the two values together. Use a cached lookup to get the output and append it to the generated key. For more information, learn about cache sinks and cached lookups.

Increment from existing maximum value
To seed the key value with the previous max, there are two techniques that you can use based on where your source data is.
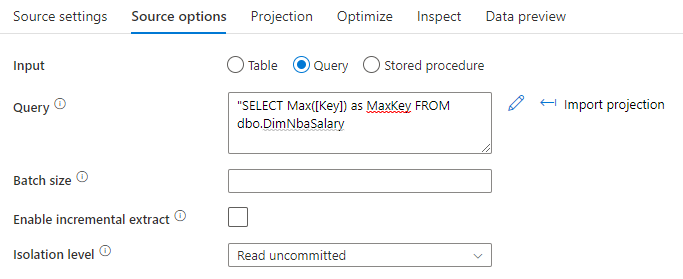
Database sources
Use a SQL query option to select MAX() from your source. For example, Select MAX(<surrogateKeyName>) as maxval from <sourceTable>.
File sources
If your previous max value is in a file, use the max() function in the aggregate transformation to get the previous max value:

In both cases, you will need to write to a cache sink and lookup the value.
Data flow script
Syntax
<incomingStream>
keyGenerate(
output(<surrogateColumnName> as long),
startAt: <number>L
) ~> <surrogateKeyTransformationName>
Example
The data flow script for the above surrogate key configuration is in the code snippet below.
AggregateDayStats
keyGenerate(
output(key as long),
startAt: 1L
) ~> SurrogateKey1
Related content
These examples use the Join and Derived Column transformations.
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for