{kind=link}
Events
Mar 31, 11 PM - Apr 2, 11 PM
The biggest Fabric, Power BI, and SQL learning event. March 31 – April 2. Use code FABINSIDER to save $400.
Register todayThis browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
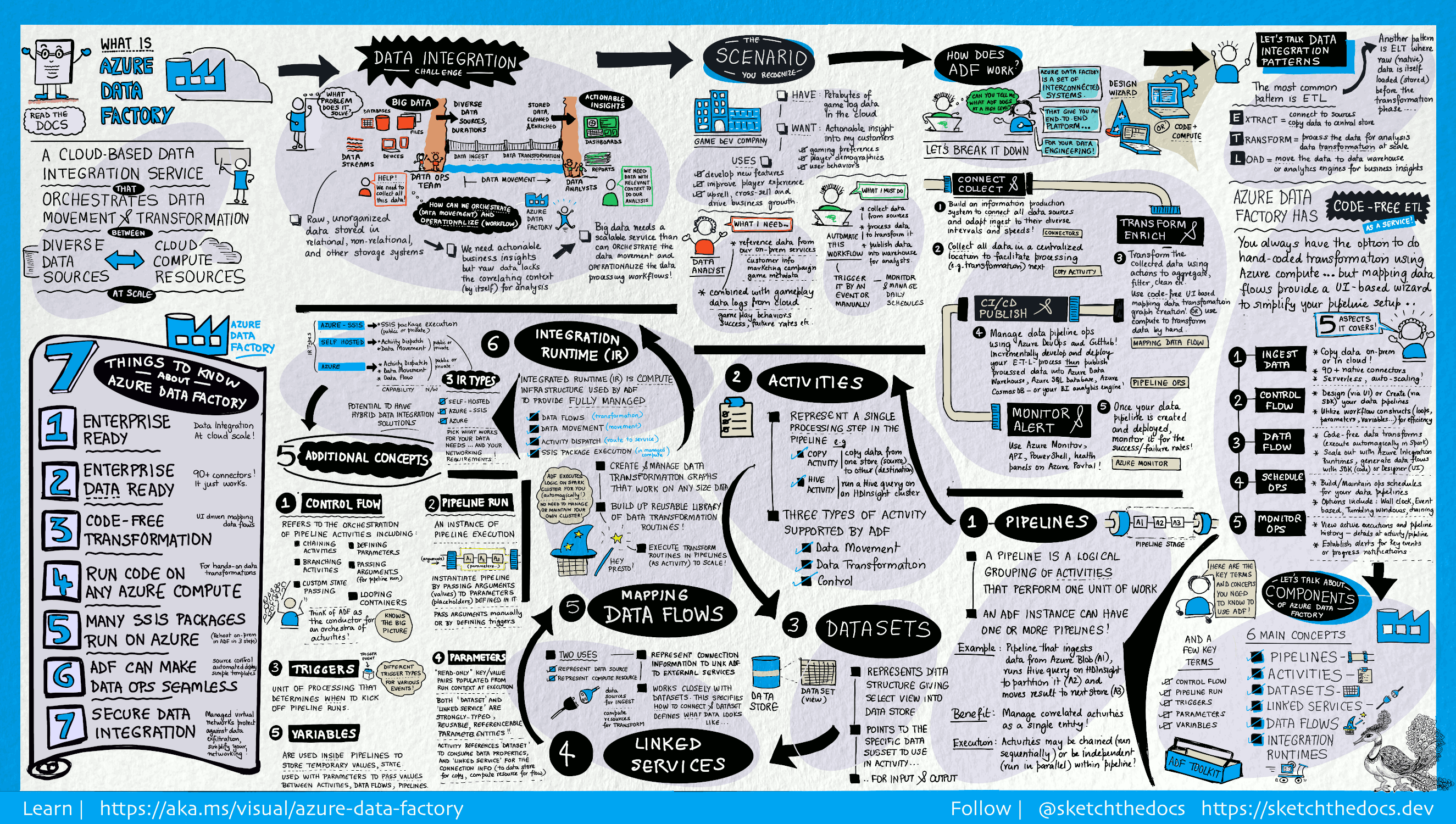
APPLIES TO:  Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Tip
Try out Data Factory in Microsoft Fabric, an all-in-one analytics solution for enterprises. Microsoft Fabric covers everything from data movement to data science, real-time analytics, business intelligence, and reporting. Learn how to start a new trial for free!
In the world of big data, raw, unorganized data is often stored in relational, non-relational, and other storage systems. However, on its own, raw data doesn't have the proper context or meaning to provide meaningful insights to analysts, data scientists, or business decision makers.
Big data requires a service that can orchestrate and operationalize processes to refine these enormous stores of raw data into actionable business insights. Azure Data Factory is a managed cloud service that's built for these complex hybrid extract-transform-load (ETL), extract-load-transform (ELT), and data integration projects.
Data Compression: During the Data Copy activity, it is possible to compress the data and write the compressed data to the target data source. This feature helps optimize bandwidth usage in data copying.
Extensive Connectivity Support for Different Data Sources: Azure Data Factory provides broad connectivity support for connecting to different data sources. This is useful when you want to pull or write data from different data sources.
Custom Event Triggers: Azure Data Factory allows you to automate data processing using custom event triggers. This feature allows you to automatically execute a certain action when a certain event occurs.
Data Preview and Validation: During the Data Copy activity, tools are provided for previewing and validating data. This feature helps you ensure that data is copied correctly and written to the target data source correctly.
Customizable Data Flows: Azure Data Factory allows you to create customizable data flows. This feature allows you to add custom actions or steps for data processing.
Integrated Security: Azure Data Factory offers integrated security features such as Entra ID integration and role-based access control to control access to dataflows. This feature increases security in data processing and protects your data.
For example, imagine a gaming company that collects petabytes of game logs that are produced by games in the cloud. The company wants to analyze these logs to gain insights into customer preferences, demographics, and usage behavior. It also wants to identify up-sell and cross-sell opportunities, develop compelling new features, drive business growth, and provide a better experience to its customers.
To analyze these logs, the company needs to use reference data such as customer information, game information, and marketing campaign information that is in an on-premises data store. The company wants to utilize this data from the on-premises data store, combining it with additional log data that it has in a cloud data store.
To extract insights, it hopes to process the joined data by using a Spark cluster in the cloud (Azure HDInsight), and publish the transformed data into a cloud data warehouse such as Azure Synapse Analytics to easily build a report on top of it. They want to automate this workflow, and monitor and manage it on a daily schedule. They also want to execute it when files land in a blob store container.
Azure Data Factory is the platform that solves such data scenarios. It is the cloud-based ETL and data integration service that allows you to create data-driven workflows for orchestrating data movement and transforming data at scale. Using Azure Data Factory, you can create and schedule data-driven workflows (called pipelines) that can ingest data from disparate data stores. You can build complex ETL processes that transform data visually with data flows or by using compute services such as Azure HDInsight Hadoop, Azure Databricks, and Azure SQL Database.
Additionally, you can publish your transformed data to data stores such as Azure Synapse Analytics for business intelligence (BI) applications to consume. Ultimately, through Azure Data Factory, raw data can be organized into meaningful data stores and data lakes for better business decisions.
Data Factory contains a series of interconnected systems that provide a complete end-to-end platform for data engineers.

This visual guide provides a detailed overview of the complete Data Factory architecture:

To see more detail, select the preceding image to zoom in, or browse to the high resolution image.
Enterprises have data of various types that are located in disparate sources on-premises, in the cloud, structured, unstructured, and semi-structured, all arriving at different intervals and speeds.
The first step in building an information production system is to connect to all the required sources of data and processing, such as software-as-a-service (SaaS) services, databases, file shares, and FTP web services. The next step is to move the data as needed to a centralized location for subsequent processing.
Without Data Factory, enterprises must build custom data movement components or write custom services to integrate these data sources and processing. It's expensive and hard to integrate and maintain such systems. In addition, they often lack the enterprise-grade monitoring, alerting, and the controls that a fully managed service can offer.
With Data Factory, you can use the Copy Activity in a data pipeline to move data from both on-premises and cloud source data stores to a centralization data store in the cloud for further analysis. For example, you can collect data in Azure Data Lake Storage and transform the data later by using an Azure Data Lake Analytics compute service. You can also collect data in Azure Blob storage and transform it later by using an Azure HDInsight Hadoop cluster.
After data is present in a centralized data store in the cloud, process or transform the collected data by using ADF mapping data flows. Data flows enable data engineers to build and maintain data transformation graphs that execute on Spark without needing to understand Spark clusters or Spark programming.
If you prefer to code transformations by hand, ADF supports external activities for executing your transformations on compute services such as HDInsight Hadoop, Spark, Data Lake Analytics, and Machine Learning.
Data Factory offers full support for CI/CD of your data pipelines using Azure DevOps and GitHub. This allows you to incrementally develop and deliver your ETL processes before publishing the finished product. After the raw data has been refined into a business-ready consumable form, load the data into Azure Data Warehouse, Azure SQL Database, Azure Cosmos DB, or whichever analytics engine your business users can point to from their business intelligence tools.
After you have successfully built and deployed your data integration pipeline, providing business value from refined data, monitor the scheduled activities and pipelines for success and failure rates. Azure Data Factory has built-in support for pipeline monitoring via Azure Monitor, API, PowerShell, Azure Monitor logs, and health panels on the Azure portal.
An Azure subscription might have one or more Azure Data Factory instances (or data factories). Azure Data Factory is composed of the following key components:
These components work together to provide the platform on which you can compose data-driven workflows with steps to move and transform data.
A data factory might have one or more pipelines. A pipeline is a logical grouping of activities that performs a unit of work. Together, the activities in a pipeline perform a task. For example, a pipeline can contain a group of activities that ingests data from an Azure blob, and then runs a Hive query on an HDInsight cluster to partition the data.
The benefit of this is that the pipeline allows you to manage the activities as a set instead of managing each one individually. The activities in a pipeline can be chained together to operate sequentially, or they can operate independently in parallel.
Create and manage graphs of data transformation logic that you can use to transform any-sized data. You can build-up a reusable library of data transformation routines and execute those processes in a scaled-out manner from your ADF pipelines. Data Factory will execute your logic on a Spark cluster that spins-up and spins-down when you need it. You won't ever have to manage or maintain clusters.
Activities represent a processing step in a pipeline. For example, you might use a copy activity to copy data from one data store to another data store. Similarly, you might use a Hive activity, which runs a Hive query on an Azure HDInsight cluster, to transform or analyze your data. Data Factory supports three types of activities: data movement activities, data transformation activities, and control activities.
Datasets represent data structures within the data stores, which simply point to or reference the data you want to use in your activities as inputs or outputs.
Linked services are much like connection strings, which define the connection information that's needed for Data Factory to connect to external resources. Think of it this way: a linked service defines the connection to the data source, and a dataset represents the structure of the data. For example, an Azure Storage-linked service specifies a connection string to connect to the Azure Storage account. Additionally, an Azure blob dataset specifies the blob container and the folder that contains the data.
Linked services are used for two purposes in Data Factory:
To represent a data store that includes, but isn't limited to, a SQL Server database, Oracle database, file share, or Azure blob storage account. For a list of supported data stores, see the copy activity article.
To represent a compute resource that can host the execution of an activity. For example, the HDInsightHive activity runs on an HDInsight Hadoop cluster. For a list of transformation activities and supported compute environments, see the transform data article.
In Data Factory, an activity defines the action to be performed. A linked service defines a target data store or a compute service. An integration runtime provides the bridge between the activity and linked Services. It's referenced by the linked service or activity, and provides the compute environment where the activity either runs on or gets dispatched from. This way, the activity can be performed in the region closest possible to the target data store or compute service in the most performant way while meeting security and compliance needs.
Triggers represent the unit of processing that determines when a pipeline execution needs to be kicked off. There are different types of triggers for different types of events.
A pipeline run is an instance of the pipeline execution. Pipeline runs are typically instantiated by passing the arguments to the parameters that are defined in pipelines. The arguments can be passed manually or within the trigger definition.
Parameters are key-value pairs of read-only configuration. Parameters are defined in the pipeline. The arguments for the defined parameters are passed during execution from the run context that was created by a trigger or a pipeline that was executed manually. Activities within the pipeline consume the parameter values.
A dataset is a strongly typed parameter and a reusable/referenceable entity. An activity can reference datasets and can consume the properties that are defined in the dataset definition.
A linked service is also a strongly typed parameter that contains the connection information to either a data store or a compute environment. It is also a reusable/referenceable entity.
Control flow is an orchestration of pipeline activities that includes chaining activities in a sequence, branching, defining parameters at the pipeline level, and passing arguments while invoking the pipeline on-demand or from a trigger. It also includes custom-state passing and looping containers, that is, For-each iterators.
Variables can be used inside of pipelines to store temporary values and can also be used in conjunction with parameters to enable passing values between pipelines, data flows, and other activities.
Here are important next step documents to explore:
Events
Mar 31, 11 PM - Apr 2, 11 PM
The biggest Fabric, Power BI, and SQL learning event. March 31 – April 2. Use code FABINSIDER to save $400.
Register todayTraining
Module
Orchestrating data movement and transformation in Azure Data Factory - Training
Orchestrate data movement and transformation in Azure Data Factory or Azure Synapse Pipeline
Certification
Microsoft Certified: Azure Data Engineer Associate - Certifications
Demonstrate understanding of common data engineering tasks to implement and manage data engineering workloads on Microsoft Azure, using a number of Azure services.