January 2019
These features and Azure Databricks platform improvements were released in January 2019.
Note
Releases are staged. Your Azure Databricks account may not be updated until up to a week after the initial release date.
Upcoming change: Python 3 to become the default when you create clusters
January 29, 2019
When Databricks platform version 2.91 releases in mid-February, the default Python version for new clusters will switch from Python 2 to Python 3. Existing clusters will not change their Python versions, of course. But if you’ve been in the habit of taking the Python 2 default when you create new clusters, you’ll need to start paying attention to your Python version selection.

Databricks Runtime 5.2 for Machine Learning (Beta) release
January 24, 2019
Databricks Runtime 5.2 ML is built on top of Databricks Runtime 5.2 (unsupported). It contains many popular machine learning libraries, including TensorFlow, PyTorch, Keras, and XGBoost, and provides distributed TensorFlow training using Horovod. In addition to library updates since Databricks Runtime ML 5.1, Databricks Runtime 5.2 ML includes the following new features:
- GraphFrames now supports the Pregel API (Python) with Databricks’s performance optimizations.
- HorovodRunner adds:
- On a GPU cluster, training processes are mapped to GPUs instead of worker nodes to simplify the support of multi-GPU instance types. This built-in support allows you to distribute to all of the GPUs on a multi-GPU machine without custom code.
HorovodRunner.run()now returns the return value from the first training process.
See the complete release notes for Databricks Runtime 5.2 ML. d
Databricks Runtime 5.2 release
January 24, 2019
Databricks Runtime 5.2 is now available. Databricks Runtime 5.2 includes Apache Spark 2.4.0, new Delta Lake and Structured Streaming features and upgrades, and upgraded Python, R, Java, and Scala libraries. For details, see Databricks Runtime 5.2 (unsupported).
Cluster configuration JSON view
January 15-22, 2019
The cluster configuration page now supports a JSON view:
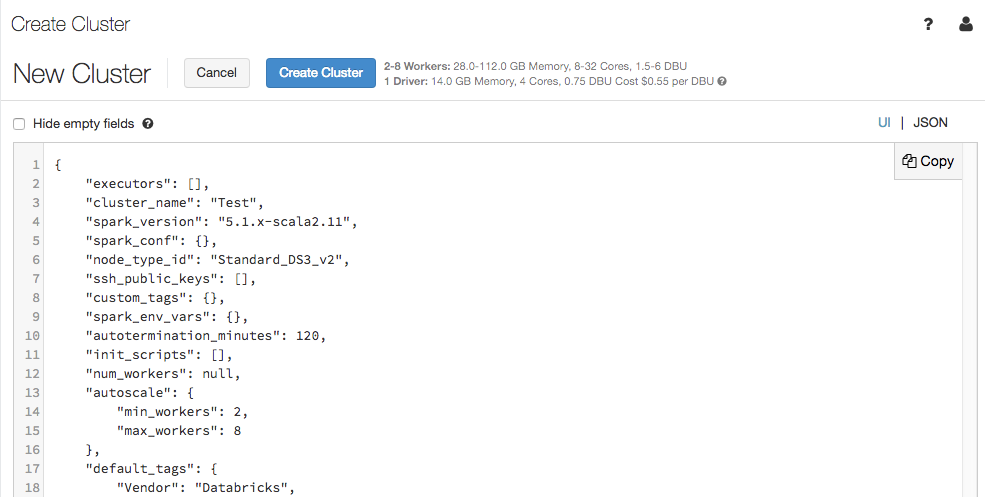
The JSON view is read-only. However, you can copy the JSON and use it to create and update clusters with the Clusters API.
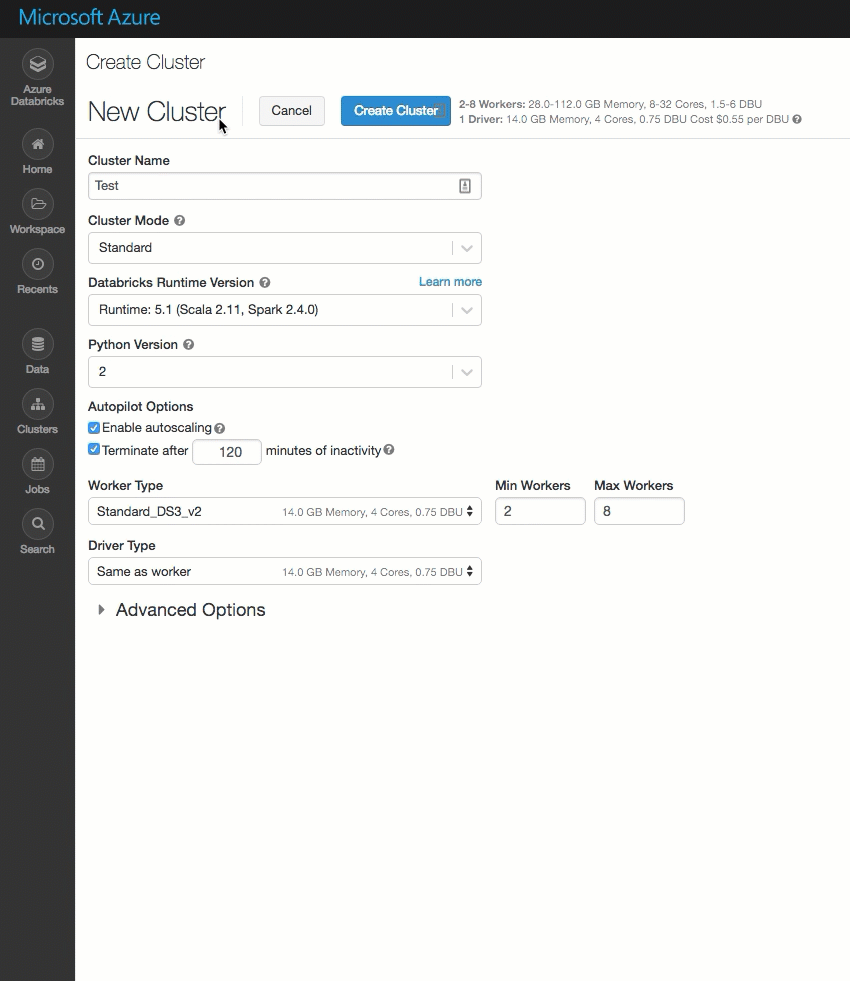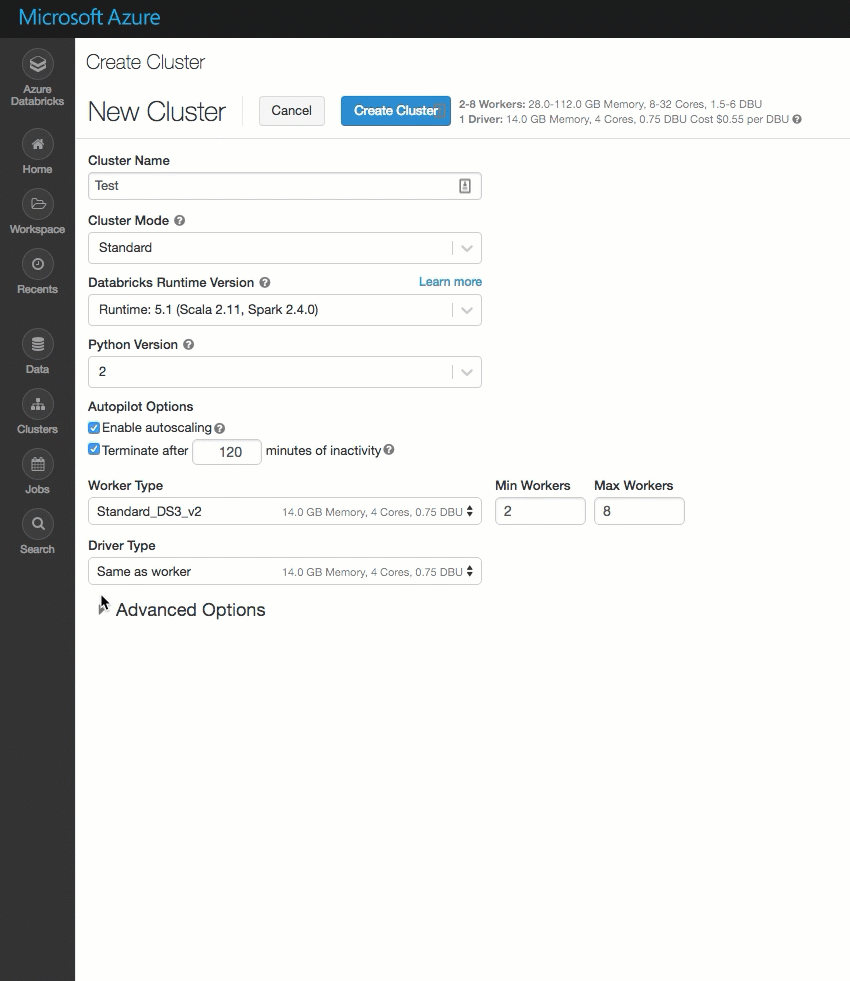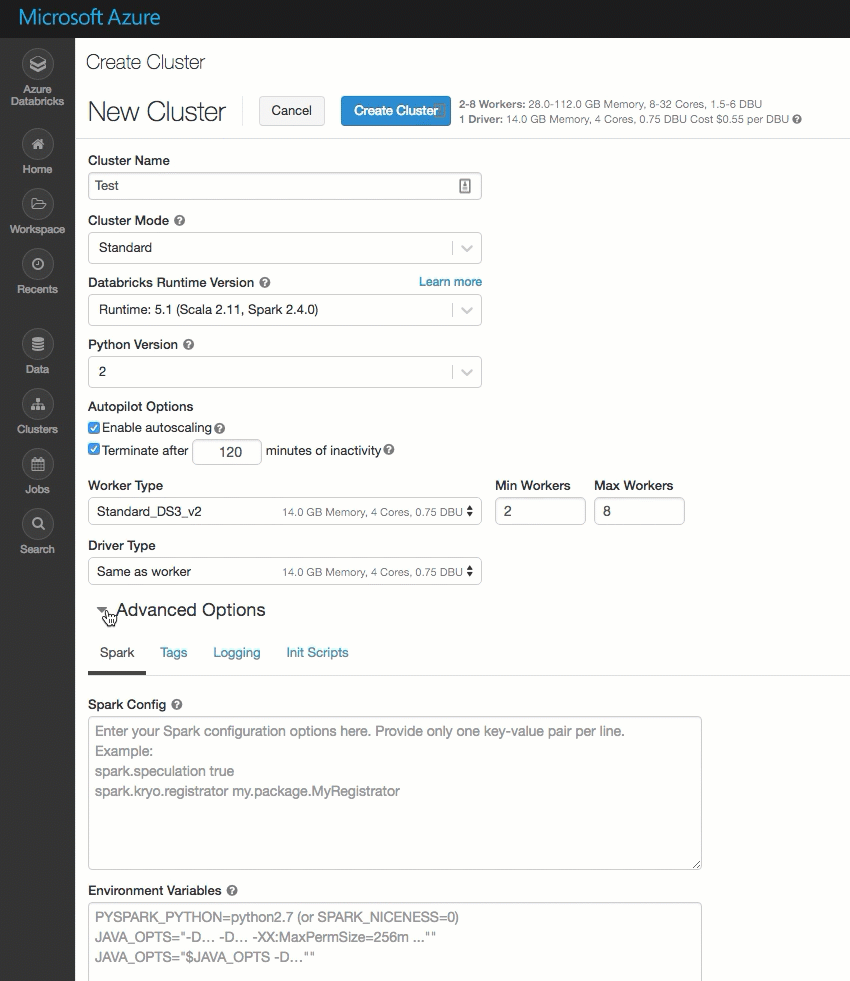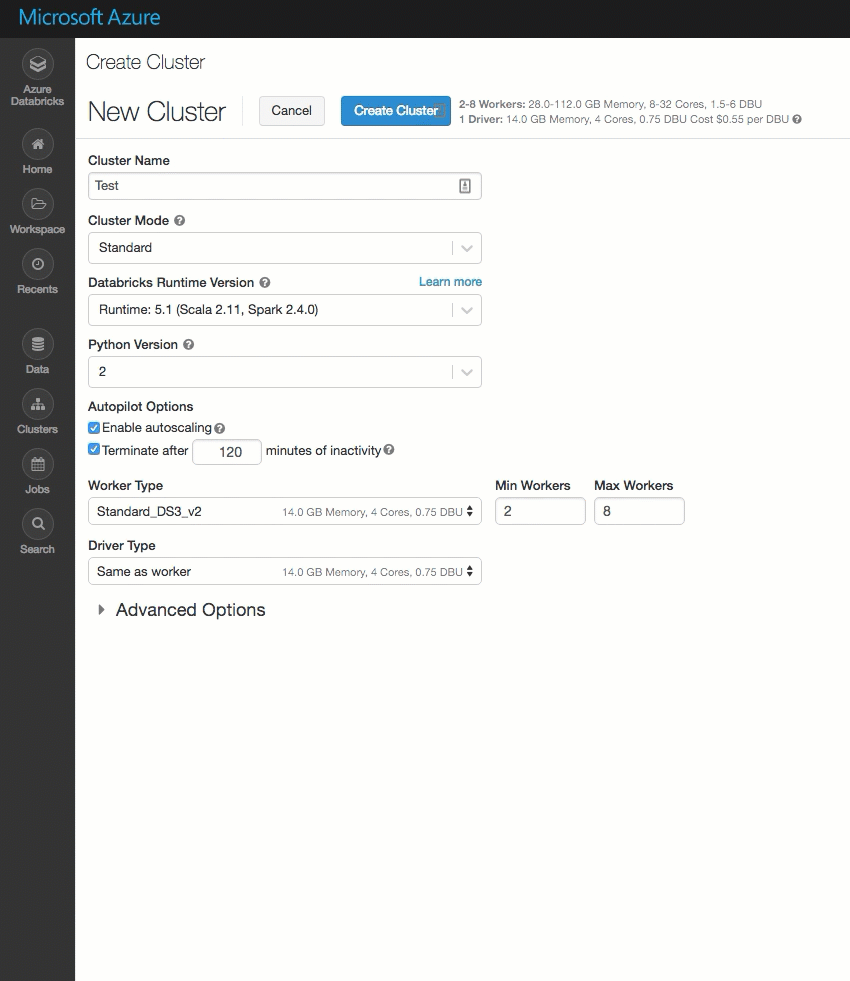
Cluster UI
January 15-22, 2019: Version 2.89
The cluster creation page has been cleaned up and reorganized for ease of use, including a new Advanced Options toggle.
Deploy Azure Databricks in your own Azure virtual network (VNet injection)
January 10, 2019
Important
This feature is in Public Preview.
The default deployment of Azure Databricks is a fully managed service on Azure: all compute plane resources, including a virtual network (VNet) that all clusters will be associated with, are deployed to a locked resource group. If you require network customization, however, you can now deploy Azure Databricks in your own virtual network (sometimes called VNet injection), enabling you to:
- Connect Azure Databricks to other Azure services (such as Azure Storage) in a more secure manner using service endpoints.
- Connect to on-premises data sources for use with Azure Databricks, taking advantage of user-defined routes.
- Connect Azure Databricks to a network virtual appliance to inspect all outbound traffic and take actions according to allow and deny rules.
- Configure Azure Databricks to use custom DNS.
- Configure network security group (NSG) rules to specify egress traffic restrictions.
- Deploy Azure Databricks clusters in your existing virtual network.
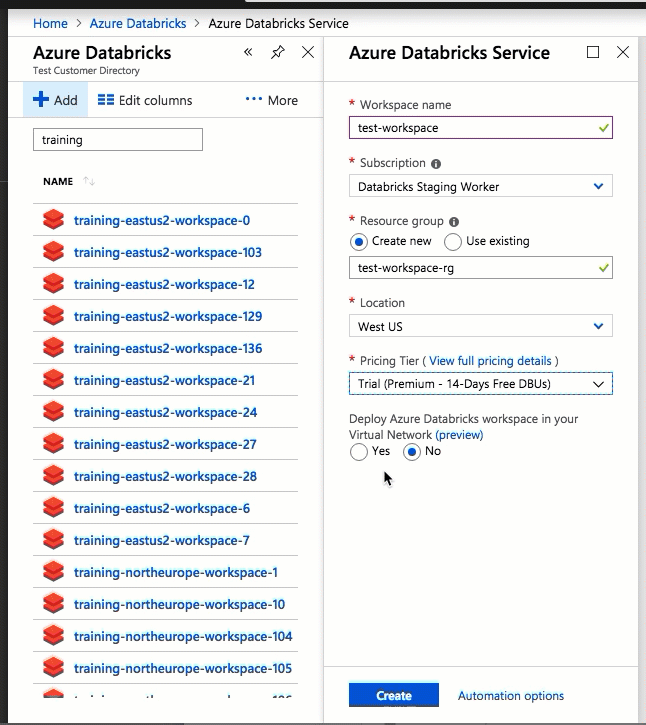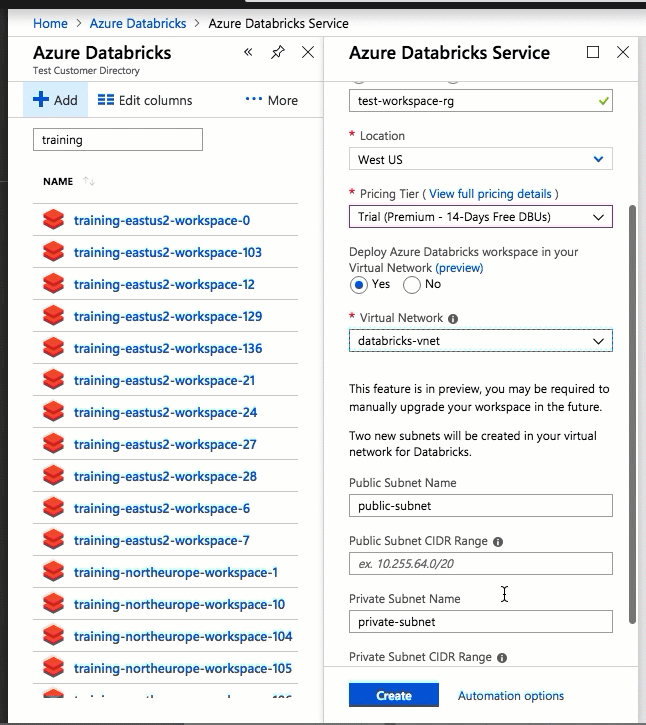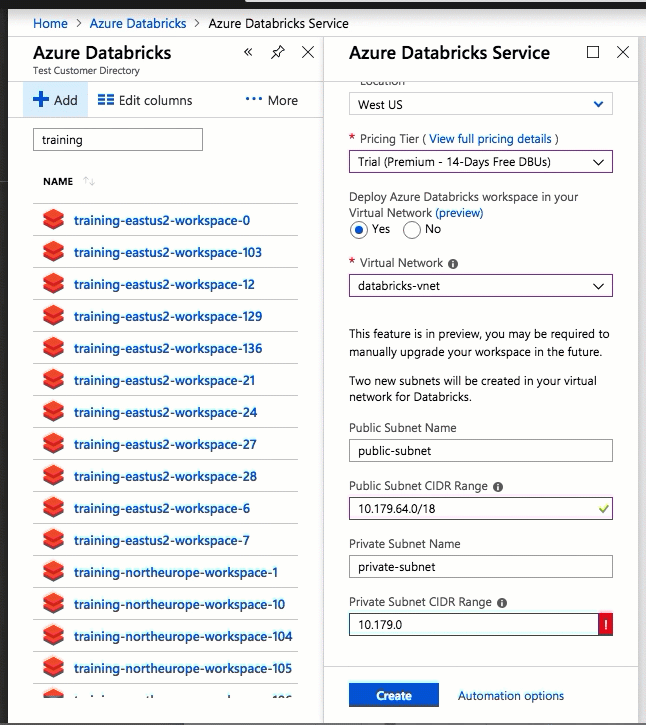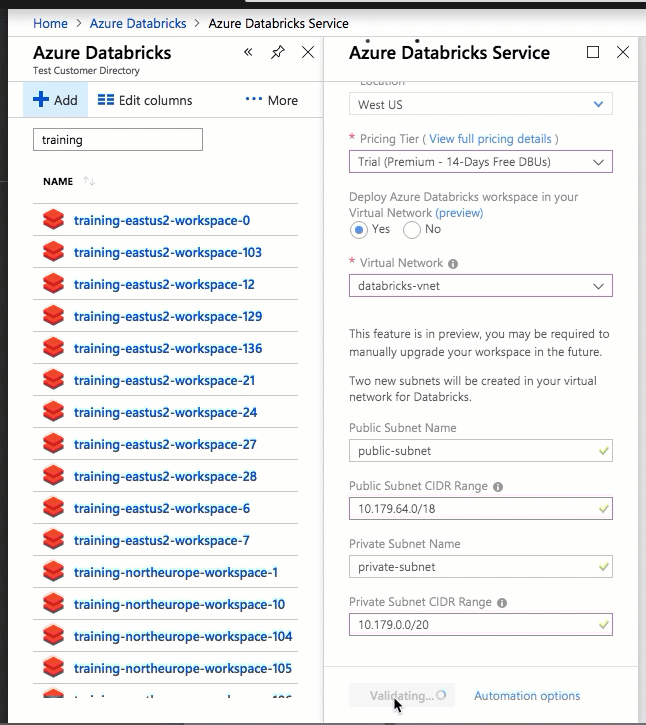
Deploying Azure Databricks to your own virtual network also lets you take advantage of flexible CIDR ranges (anywhere between /16-/24 for the virtual network and between /18-/26 for the subnets).
Configuration using the Azure portal UI is quick and easy: when you create a workspace, just select Deploy Azure Databricks workspace in your Virtual Network, select your virtual network, and provide CIDR ranges for two subnets. Azure Databricks updates the virtual network with two new subnets and network security groups using CIDR ranges provided by you, allows access to inbound and outbound subnet traffic, and deploys the workspace to the updated virtual network.
If you prefer to configure the virtual network for VNet injection yourself—for example, you want to use existing subnets, use existing network security groups, or create your own security rules—you can use Azure-Databricks-supplied ARM templates instead of the portal UI.
Note
This feature was previously available by enrollment only. It remains in Preview but is now fully self-service.
For details, see Deploy Azure Databricks in your Azure virtual network (VNet injection) and Connect your Azure Databricks workspace to your on-premises network.
Library UI
January 2-9, 2019: Version 2.88
The library UI improvements that were originally released in November 2018 and reverted shortly thereafter have been re-released. These updates make it easier to upload, install, and manage libraries for your Azure Databricks clusters.
The Azure Databricks UI now supports both workspace libraries and cluster-installed libraries. A workspace library exists in the Workspace and can be installed on one or more clusters. A cluster-installed library is a library that exists only in the context of the cluster that it is installed on. In addition:
- You can now create a library from a file uploaded to object storage.
- You can now install and uninstall libraries from the library details page and a cluster’s Libraries tab.
- Libraries installed using the API now display in a cluster’s Libraries tab.
For details, see Libraries.
Cluster Events
January 2-9, 2019: Version 2.88
New cluster events were added to reflect Spark driver status. For details, see Clusters API.
Notebook Version Control using Azure DevOps Services
January 2-9, 2019: Version 2.88
Azure Databricks now makes it easy to use Azure DevOps Services (formerly VSTS) to version-control your notebooks. Authentication is automatic, setup is straightforward, and you manage your notebook revisions just like you do with our GitHub integration.
For details, see Git version control for notebooks (legacy).
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for