Apache Phoenix in Azure HDInsight
Apache Phoenix is an open source, massively parallel relational database layer built on Apache HBase. Phoenix allows you to use SQL-like queries over HBase. Phoenix uses JDBC drivers underneath to enable users to create, delete, alter SQL tables, indexes, views and sequences, and upsert rows individually and in bulk. Phoenix uses noSQL native compilation rather than using MapReduce to compile queries, enabling the creation of low-latency applications on top of HBase. Phoenix adds coprocessors to support running client-supplied code in the address space of the server, executing the code colocated with the data. This approach minimizes client/server data transfer.
Apache Phoenix opens up big data queries to non-developers who can use a SQL-like syntax rather than programming. Phoenix is highly optimized for HBase, unlike other tools such as Apache Hive and Apache Spark SQL. The benefit to developers is writing highly performant queries with much less code.
When you submit a SQL query, Phoenix compiles the query to HBase native calls and runs the scan (or plan) in parallel for optimization. This layer of abstraction frees the developer from writing MapReduce jobs, to focus instead on the business logic and the workflow of their application around Phoenix's big data storage.
Query performance optimization and other features
Apache Phoenix adds several performance enhancements and features to HBase queries.
Secondary indexes
HBase has a single index that is lexicographically sorted on the primary row key. These records can only be accessed through the row key. Accessing records through any column other than the row key requires scanning all of the data while applying the required filter. In a secondary index, the columns or expressions that are indexed form an alternate row key, allowing lookups and range scans on that index.
Create a secondary index with the CREATE INDEX command:
CREATE INDEX ix_purchasetype on SALTEDWEBLOGS (purchasetype, transactiondate) INCLUDE (bookname, quantity);
This approach can yield a significant performance increase over executing single-indexed queries. This type of secondary index is a covering index, containing all of the columns included in the query. Therefore, the table lookup isn't required and the index satisfies the entire query.
Views
Phoenix views provide a way to overcome an HBase limitation, where performance begins to degrade when you create more than about 100 physical tables. Phoenix views enable multiple virtual tables to share one underlying physical HBase table.
Creating a Phoenix view is similar to using standard SQL view syntax. One difference is that you can define columns for your view, in addition to the columns inherited from its base table. You can also add new KeyValue columns.
For example, here is a physical table named product_metrics with the following definition:
CREATE TABLE product_metrics (
metric_type CHAR(1) NOT NULL,
created_by VARCHAR,
created_date DATE NOT NULL,
metric_id INTEGER NOT NULL
CONSTRAINT pk PRIMARY KEY (metric_type, created_by, created_date, metric_id));
Define a view over this table, with additional columns:
CREATE VIEW mobile_product_metrics (carrier VARCHAR, dropped_calls BIGINT) AS
SELECT * FROM product_metrics
WHERE metric_type = 'm';
To add more columns later, use the ALTER VIEW statement.
Skip scan
Skip scan uses one or more columns of a composite index to find distinct values. Unlike a range scan, skip scan implements intra-row scanning, yielding improved performance. While scanning, the first matched value is skipped along with the index until the next value is found.
A skip scan uses the SEEK_NEXT_USING_HINT enumeration of the HBase filter. Using SEEK_NEXT_USING_HINT, the skip scan keeps track of which set of keys, or ranges of keys, are being searched for in each column. The skip scan then takes a key that was passed to it during filter evaluation, and determines whether it's one of the combinations. If not, the skip scan evaluates the next highest key to jump to.
Transactions
While HBase provides row-level transactions, Phoenix integrates with Tephra to add cross-row and cross-table transaction support with full ACID semantics.
As with traditional SQL transactions, transactions provided through the Phoenix transaction manager allow you to ensure an atomic unit of data is successfully upserted, rolling back the transaction if the upsert operation fails on any transaction-enabled table.
To enable Phoenix transactions, see the Apache Phoenix transaction documentation.
To create a new table with transactions enabled, set the TRANSACTIONAL property to true in a CREATE statement:
CREATE TABLE my_table (k BIGINT PRIMARY KEY, v VARCHAR) TRANSACTIONAL=true;
To alter an existing table to be transactional, use the same property in an ALTER statement:
ALTER TABLE my_other_table SET TRANSACTIONAL=true;
Note
You cannot switch a transactional table back to being non-transactional.
Salted Tables
Region server hotspotting can occur when writing records with sequential keys to HBase. Though you may have multiple region servers in your cluster, your writes are all occurring on just one. This concentration creates the hotspotting issue where, instead of your write workload being distributed across all of the available region servers, just one is handling the load. Since each region has a predefined maximum size, when a region reaches that size limit, it's split into two small regions. When that happens, one of these new regions takes all new records, becoming the new hotspot.
To mitigate this problem and achieve better performance, pre-split tables so that all of the region servers are equally used. Phoenix provides salted tables, transparently adding the salting byte to the row key for a particular table. The table is pre-split on the salt byte boundaries to ensure equal load distribution among region servers during the initial phase of the table. This approach distributes the write workload across all of the available region servers, improving the write and read performance. To salt a table, specify the SALT_BUCKETS table property when the table is created:
CREATE TABLE Saltedweblogs (
transactionid varchar(500) Primary Key,
transactiondate Date NULL,
customerid varchar(50) NULL,
bookid varchar(50) NULL,
purchasetype varchar(50) NULL,
orderid varchar(50) NULL,
bookname varchar(50) NULL,
categoryname varchar(50) NULL,
invoicenumber varchar(50) NULL,
invoicestatus varchar(50) NULL,
city varchar(50) NULL,
state varchar(50) NULL,
paymentamount DOUBLE NULL,
quantity INTEGER NULL,
shippingamount DOUBLE NULL) SALT_BUCKETS=4;
Enable and tune Phoenix with Apache Ambari
An HDInsight HBase cluster includes the Ambari UI for making configuration changes.
To enable or disable Phoenix, and to control Phoenix's query timeout settings, log in to the Ambari Web UI (
https://YOUR_CLUSTER_NAME.azurehdinsight.net) using your Hadoop user credentials.Select HBase from the list of services in the left-hand menu, then select the Configs tab.
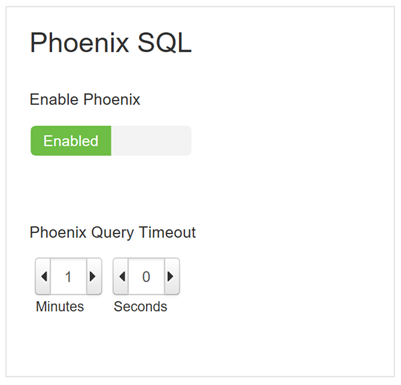
Find the Phoenix SQL configuration section to enable or disable phoenix, and set the query timeout.
See also
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for