Azure Storage overview in HDInsight
Azure Storage is a robust general-purpose storage solution that integrates seamlessly with HDInsight. HDInsight can use a blob container in Azure Storage as the default file system for the cluster. Through an HDFS interface, the full set of components in HDInsight can operate directly on structured or unstructured data stored as blobs.
We recommend using separate storage containers for your default cluster storage and your business data. The separation is to isolate the HDInsight logs and temporary files from your own business data. We also recommend deleting the default blob container, which contains application and system logs, after each use to reduce storage cost. Make sure to retrieve the logs before deleting the container.
If you choose to secure your storage account with the Firewalls and virtual networks restrictions on Selected networks, be sure to enable the exception Allow trusted Microsoft services.... The exception is so that HDInsight can access your storage account.
HDInsight storage architecture
The following diagram provides an abstract view of the HDInsight architecture of Azure Storage:
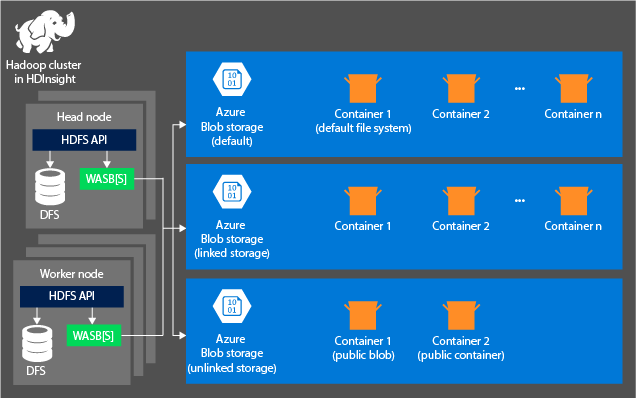
HDInsight provides access to the distributed file system that is locally attached to the compute nodes. This file system can be accessed by using the fully qualified URI, for example:
hdfs://<namenodehost>/<path>
Through HDInsight, you can also access data in Azure Storage. The syntax is as follows:
wasb://<containername>@<accountname>.blob.core.windows.net/<path>
For accounts that have a hierarchical namespace (Azure Data Lake Storage Gen2), the syntax is as follows:
abfs://<containername>@<accountname>.dfs.core.windows.net/<file.path>/
Consider the following principles when using an Azure Storage account with HDInsight clusters:
Containers in the storage accounts that are connected to a cluster: Because the account name and key are associated with the cluster during creation, you have full access to the blobs in those containers.
Public containers or public blobs in storage accounts that aren't connected to a cluster: You have read-only permission to the blobs in the containers.
Note
Public containers allow you to get a list of all blobs that are available in that container and to get container metadata. Public blobs allow you to access the blobs only if you know the exact URL. For more information, see Manage anonymous read access to containers and blobs.
Private containers in storage accounts that aren't connected to a cluster: You can't access the blobs in the containers unless you define the storage account when you submit the WebHCat jobs.
The storage accounts that are defined in the creation process and their keys are stored in %HADOOP_HOME%/conf/core-site.xml on the cluster nodes. By default, HDInsight uses the storage accounts defined in the core-site.xml file. You can modify this setting by using Apache Ambari. For more information about the storage account settings that can be modified or placed in the core-site.xml file, see these articles:
Multiple WebHCat jobs, including Apache Hive. And MapReduce, Apache Hadoop streaming, and Apache Pig, carry a description of storage accounts and metadata. (This aspect is currently true for Pig with storage accounts but not for metadata.) For more information, see Using an HDInsight cluster with alternate storage accounts and metastores.
Blobs can be used for structured and unstructured data. Blob containers store data as key/value pairs and have no directory hierarchy. However the key name can include a slash character ( / ) to make it appear as if a file is stored within a directory structure. For example, a blob's key can be input/log1.txt. No actual input directory exists, but because of the slash character in the key name, the key looks like a file path.
Benefits of Azure Storage
Compute clusters and storage resources that aren't colocated have implied performance costs. These costs are mitigated by the way the compute clusters are created close to the storage account resources inside the Azure region. In this region, the compute nodes can efficiently access the data over the high-speed network inside Azure Storage.
When you store the data in Azure Storage instead of HDFS, you get several benefits:
Data reuse and sharing: The data in HDFS is located inside the compute cluster. Only the applications that have access to the compute cluster can use the data by using HDFS APIs. The data in Azure Storage, by contrast, can be accessed through either the HDFS APIs or the Blob storage REST APIs. Because of this arrangement, a larger set of applications (including other HDInsight clusters) and tools can be used to produce and consume the data.
Data archiving: When data is stored in Azure Storage, the HDInsight clusters used for computation can be safely deleted without losing user data.
Data storage cost: Storing data in DFS for the long term is more costly than storing the data in Azure Storage. Because the cost of a compute cluster is higher than the cost of Azure Storage. Also, because the data doesn't have to be reloaded for every compute cluster generation, you're saving data-loading costs as well.
Elastic scale-out: Although HDFS provides you with a scaled-out file system, the scale is determined by the number of nodes that you create for your cluster. Changing the scale can be more complicated than the elastic scaling capabilities that you get automatically in Azure Storage.
Geo-replication: Your Azure Storage can be geo-replicated. Although geo-replication gives you geographic recovery and data redundancy, a failover to the geo-replicated location severely affects your performance, and it might incur additional costs. So choose geo-replication cautiously and only if the value of the data justifies the additional cost.
Certain MapReduce jobs and packages might create intermediate results that you wouldn't want to store in Azure Storage. In that case, you can choose to store the data in the local HDFS. HDInsight uses DFS for several of these intermediate results in Hive jobs and other processes.
Note
Most HDFS commands (for example, ls, copyFromLocal, and mkdir) work as expected in Azure Storage. Only the commands that are specific to the native HDFS implementation (which is referred to as DFS), such as fschk and dfsadmin, show different behavior in Azure Storage.
Next steps
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for