Use HDInsight Spark cluster to analyze data in Data Lake Storage Gen1
In this article, you use Jupyter Notebook available with HDInsight Spark clusters to run a job that reads data from a Data Lake Storage account.
Prerequisites
Azure Data Lake Storage Gen1 account. Follow the instructions at Get started with Azure Data Lake Storage Gen1 using the Azure portal.
Azure HDInsight Spark cluster with Data Lake Storage Gen1 as storage. Follow the instructions at Quickstart: Set up clusters in HDInsight.
Prepare the data
Note
You do not need to perform this step if you have created the HDInsight cluster with Data Lake Storage as default storage. The cluster creation process adds some sample data in the Data Lake Storage account that you specify while creating the cluster. Skip to the section Use HDInsight Spark cluster with Data Lake Storage.
If you created an HDInsight cluster with Data Lake Storage as additional storage and Azure Storage Blob as default storage, you should first copy over some sample data to the Data Lake Storage account. You can use the sample data from the Azure Storage Blob associated with the HDInsight cluster.
Open a command prompt and navigate to the directory where AdlCopy is installed, typically
%HOMEPATH%\Documents\adlcopy.Run the following command to copy a specific blob from the source container to Data Lake Storage:
AdlCopy /source https://<source_account>.blob.core.windows.net/<source_container>/<blob name> /dest swebhdfs://<dest_adls_account>.azuredatalakestore.net/<dest_folder>/ /sourcekey <storage_account_key_for_storage_container>Copy the HVAC.csv sample data file at /HdiSamples/HdiSamples/SensorSampleData/hvac/ to the Azure Data Lake Storage account. The code snippet should look like:
AdlCopy /Source https://mydatastore.blob.core.windows.net/mysparkcluster/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv /dest swebhdfs://mydatalakestore.azuredatalakestore.net/hvac/ /sourcekey uJUfvD6cEvhfLoBae2yyQf8t9/BpbWZ4XoYj4kAS5Jf40pZaMNf0q6a8yqTxktwVgRED4vPHeh/50iS9atS5LQ==Warning
Make sure that the file and path names use the proper capitalization.
You are prompted to enter the credentials for the Azure subscription under which you have your Data Lake Storage account. You see an output similar to the following snippet:
Initializing Copy. Copy Started. 100% data copied. Copy Completed. 1 file copied.The data file (HVAC.csv) will be copied under a folder /hvac in the Data Lake Storage account.
Use an HDInsight Spark cluster with Data Lake Storage Gen1
From the Azure portal, from the startboard, click the tile for your Apache Spark cluster (if you pinned it to the startboard). You can also navigate to your cluster under Browse All > HDInsight Clusters.
From the Spark cluster blade, click Quick Links, and then from the Cluster Dashboard blade, click Jupyter Notebook. If prompted, enter the admin credentials for the cluster.
Note
You may also reach the Jupyter Notebook for your cluster by opening the following URL in your browser. Replace CLUSTERNAME with the name of your cluster:
https://CLUSTERNAME.azurehdinsight.net/jupyterCreate a new notebook. Click New, and then click PySpark.
Because you created a notebook using the PySpark kernel, you do not need to create any contexts explicitly. The Spark and Hive contexts will be automatically created for you when you run the first code cell. You can start by importing the types required for this scenario. To do so, paste the following code snippet in a cell and press SHIFT + ENTER.
from pyspark.sql.types import *Every time you run a job in Jupyter, your web browser window title will show a (Busy) status along with the notebook title. You will also see a solid circle next to the PySpark text in the top-right corner. After the job is completed, this will change to a hollow circle.

Load sample data into a temporary table using the HVAC.csv file you copied to the Data Lake Storage Gen1 account. You can access the data in the Data Lake Storage account using the following URL pattern.
If you have Data Lake Storage Gen1 as default storage, HVAC.csv will be at the path similar to the following URL:
adl://<data_lake_store_name>.azuredatalakestore.net/<cluster_root>/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csvOr, you could also use a shortened format such as the following:
adl:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csvIf you have Data Lake Storage as additional storage, HVAC.csv will be at the location where you copied it, such as:
adl://<data_lake_store_name>.azuredatalakestore.net/<path_to_file>In an empty cell, paste the following code example, replace MYDATALAKESTORE with your Data Lake Storage account name, and press SHIFT + ENTER. This code example registers the data into a temporary table called hvac.
# Load the data. The path below assumes Data Lake Storage is default storage for the Spark cluster hvacText = sc.textFile("adl://MYDATALAKESTORazuredatalakestore. net/cluster/mysparkclusteHdiSamples/HdiSamples/ SensorSampleData/hvac/HVAC.csv") # Create the schema hvacSchema = StructType([StructField("date", StringTy(), False) ,StructField("time", StringType(), FalseStructField ("targettemp", IntegerType(), FalseStructField("actualtemp", IntegerType(), FalseStructField("buildingID", StringType(), False)]) # Parse the data in hvacText hvac = hvacText.map(lambda s: s.split(",")).filt(lambda s: s [0] != "Date").map(lambda s:(str(s[0]), s(s[1]), int(s[2]), int (s[3]), str(s[6]) )) # Create a data frame hvacdf = sqlContext.createDataFrame(hvac,hvacSchema) # Register the data fram as a table to run queries against hvacdf.registerTempTable("hvac")
Because you are using a PySpark kernel, you can now directly run a SQL query on the temporary table hvac that you just created by using the
%%sqlmagic. For more information about the%%sqlmagic, as well as other magics available with the PySpark kernel, see Kernels available on Jupyter Notebooks with Apache Spark HDInsight clusters.%%sql SELECT buildingID, (targettemp - actualtemp) AS temp_diff, date FROM hvac WHERE date = \"6/1/13\"Once the job is completed successfully, the following tabular output is displayed by default.

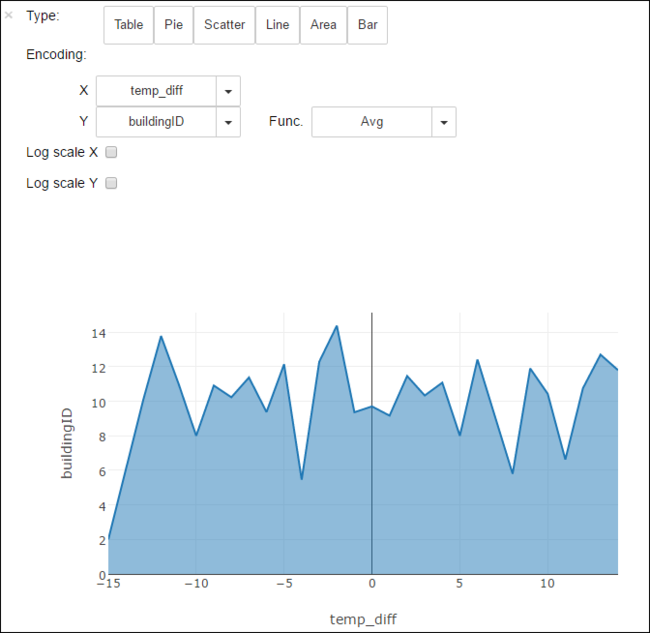
You can also see the results in other visualizations as well. For example, an area graph for the same output would look like the following.
After you have finished running the application, you should shutdown the notebook to release the resources. To do so, from the File menu on the notebook, click Close and Halt. This will shutdown and close the notebook.
Next steps
- Create a standalone Scala application to run on Apache Spark cluster
- Use HDInsight Tools in Azure Toolkit for IntelliJ to create Apache Spark applications for HDInsight Spark Linux cluster
- Use HDInsight Tools in Azure Toolkit for Eclipse to create Apache Spark applications for HDInsight Spark Linux cluster
- Use Azure Data Lake Storage Gen2 with Azure HDInsight clusters
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for