Group Data into Bins component
This article describes how to use the Group Data into Bins component in Azure Machine Learning designer, to group numbers or change the distribution of continuous data.
The Group Data into Bins component supports multiple options for binning data. You can customize how the bin edges are set and how values are apportioned into the bins. For example, you can:
- Manually type a series of values to serve as the bin boundaries.
- Assign values to bins by using quantiles, or percentile ranks.
- Force an even distribution of values into the bins.
More about binning and grouping
Binning or grouping data (sometimes called quantization) is an important tool in preparing numerical data for machine learning. It's useful in scenarios like these:
A column of continuous numbers has too many unique values to model effectively. So you automatically or manually assign the values to groups, to create a smaller set of discrete ranges.
You want to replace a column of numbers with categorical values that represent specific ranges.
For example, you might want to group values in an age column by specifying custom ranges, such as 1-15, 16-22, 23-30, and so forth for user demographics.
A dataset has a few extreme values, all well outside the expected range, and these values have an outsized influence on the trained model. To mitigate the bias in the model, you might transform the data to a uniform distribution by using the quantiles method.
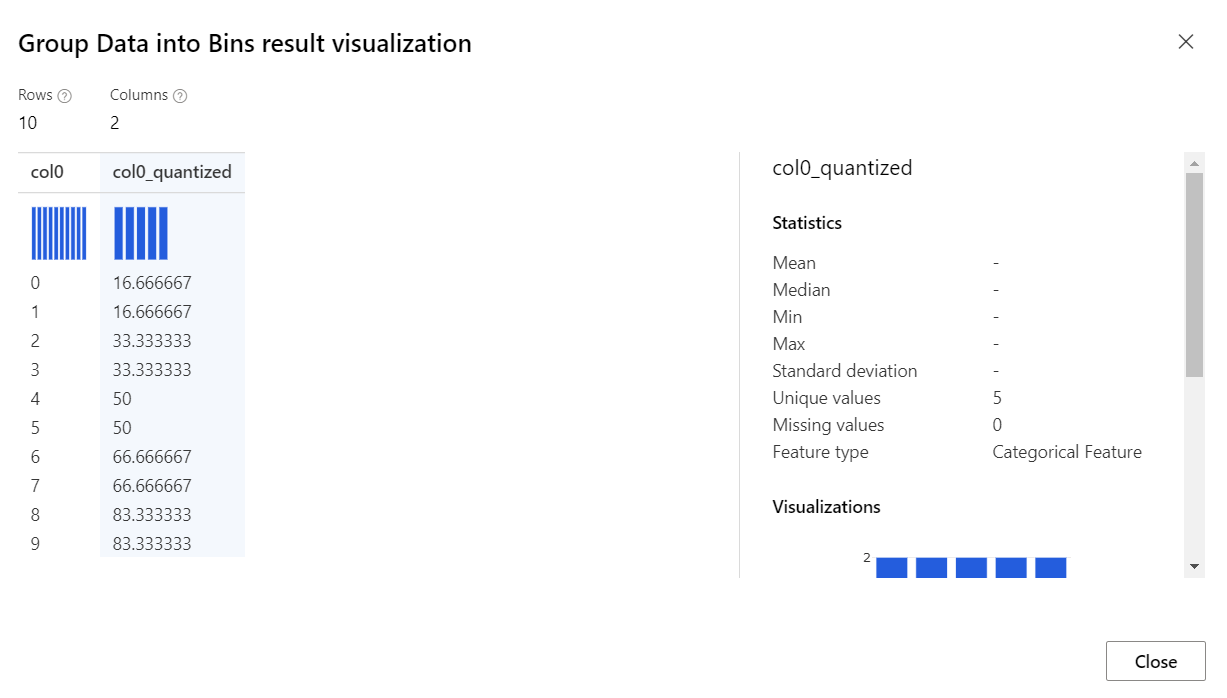
With this method, the Group Data into Bins component determines the ideal bin locations and bin widths to ensure that approximately the same number of samples fall into each bin. Then, depending on the normalization method you choose, the values in the bins are either transformed to percentiles or mapped to a bin number.
Examples of binning
The following diagram shows the distribution of numeric values before and after binning with the quantiles method. Notice that compared to the raw data at left, the data has been binned and transformed to a unit-normal scale.
Because there are so many ways to group data, all customizable, we recommend that you experiment with different methods and values.
How to configure Group Data into Bins
Add the Group Data Into Bins component to your pipeline in the designer. You can find this component in the category Data Transformation.
Connect the dataset that has numerical data to bin. Quantization can be applied only to columns that contain numeric data.
If the dataset contains non-numeric columns, use the Select Columns in Dataset component to select a subset of columns to work with.
Specify the binning mode. The binning mode determines other parameters, so be sure to select the Binning mode option first. The following types of binning are supported:
Quantiles: The quantile method assigns values to bins based on percentile ranks. This method is also known as equal height binning.
Equal Width: With this option, you must specify the total number of bins. The values from the data column are placed in the bins such that each bin has the same interval between starting and ending values. As a result, some bins might have more values if data is clumped around a certain point.
Custom Edges: You can specify the values that begin each bin. The edge value is always the lower boundary of the bin.
For example, assume you want to group values into two bins. One will have values greater than 0, and one will have values less than or equal to 0. In this case, for bin edges, you enter 0 in Comma-separated list of bin edges. The output of the component will be 1 and 2, indicating the bin index for each row value. Note that the comma-separated value list must be in an ascending order, such as 1, 3, 5, 7.
Note
Entropy MDL mode is defined in Studio (classic) and there's no corresponding open source package which can be leveraged to support in Designer yet.
If you're using the Quantiles and Equal Width binning modes, use the Number of bins option to specify how many bins, or quantiles, you want to create.
For Columns to bin, use the column selector to choose the columns that have the values you want to bin. Columns must be a numeric data type.
The same binning rule is applied to all applicable columns that you choose. If you need to bin some columns by using a different method, use a separate instance of the Group Data into Bins component for each set of columns.
Warning
If you choose a column that's not an allowed type, a runtime error is generated. The component returns an error as soon as it finds any column of a disallowed type. If you get an error, review all selected columns. The error does not list all invalid columns.
For Output mode, indicate how you want to output the quantized values:
Append: Creates a new column with the binned values, and appends that to the input table.
Inplace: Replaces the original values with the new values in the dataset.
ResultOnly: Returns just the result columns.
If you select the Quantiles binning mode, use the Quantile normalization option to determine how values are normalized before sorting into quantiles. Note that normalizing values transforms the values but doesn't affect the final number of bins.
The following normalization types are supported:
Percent: Values are normalized within the range [0,100].
PQuantile: Values are normalized within the range [0,1].
QuantileIndex: Values are normalized within the range [1,number of bins].
If you choose the Custom Edges option, enter a comma-separated list of numbers to use as bin edges in the Comma-separated list of bin edges text box.
The values mark the point that divides bins. For example, if you enter one bin edge value, two bins will be generated. If you enter two bin edge values, three bins will be generated.
The values must be sorted in the order that the bins are created, from lowest to highest.
Select the Tag columns as categorical option to indicate that the quantized columns should be handled as categorical variables.
Submit the pipeline.
Results
The Group Data into Bins component returns a dataset in which each element has been binned according to the specified mode.
It also returns a binning transformation. That function can be passed to the Apply Transformation component to bin new samples of data by using the same binning mode and parameters.
Tip
If you use binning on your training data, you must use the same binning method on data that you use for testing and prediction. You must also use the same bin locations and bin widths.
To ensure that data is always transformed by using the same binning method, we recommend that you save useful data transformations. Then apply them to other datasets by using the Apply Transformation component.
Next steps
See the set of components available to Azure Machine Learning.
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for