Debugging scoring script with Azure Machine Learning inference HTTP server
The Azure Machine Learning inference HTTP server is a Python package that exposes your scoring function as an HTTP endpoint and wraps the Flask server code and dependencies into a singular package. It's included in the prebuilt Docker images for inference that are used when deploying a model with Azure Machine Learning. Using the package alone, you can deploy the model locally for production, and you can also easily validate your scoring (entry) script in a local development environment. If there's a problem with the scoring script, the server will return an error and the location where the error occurred.
The server can also be used to create validation gates in a continuous integration and deployment pipeline. For example, you can start the server with the candidate script and run the test suite against the local endpoint.
This article mainly targets users who want to use the inference server to debug locally, but it will also help you understand how to use the inference server with online endpoints.
Online endpoint local debugging
Debugging endpoints locally before deploying them to the cloud can help you catch errors in your code and configuration earlier. To debug endpoints locally, you could use:
- the Azure Machine Learning inference HTTP server
- a local endpoint
This article focuses on the Azure Machine Learning inference HTTP server.
The following table provides an overview of scenarios to help you choose what works best for you.
| Scenario | Inference HTTP server | Local endpoint |
|---|---|---|
| Update local Python environment without Docker image rebuild | Yes | No |
| Update scoring script | Yes | Yes |
| Update deployment configurations (deployment, environment, code, model) | No | Yes |
| Integrate VS Code Debugger | Yes | Yes |
By running the inference HTTP server locally, you can focus on debugging your scoring script without being affected by the deployment container configurations.
Prerequisites
- Requires: Python >=3.8
- Anaconda
Tip
The Azure Machine Learning inference HTTP server runs on Windows and Linux based operating systems.
Installation
Note
To avoid package conflicts, install the server in a virtual environment.
To install the azureml-inference-server-http package, run the following command in your cmd/terminal:
python -m pip install azureml-inference-server-http
Debug your scoring script locally
To debug your scoring script locally, you can test how the server behaves with a dummy scoring script, use VS Code to debug with the azureml-inference-server-http package, or test the server with an actual scoring script, model file, and environment file from our examples repo.
Test the server behavior with a dummy scoring script
Create a directory to hold your files:
mkdir server_quickstart cd server_quickstartTo avoid package conflicts, create a virtual environment and activate it:
python -m venv myenv source myenv/bin/activateTip
After testing, run
deactivateto deactivate the Python virtual environment.Install the
azureml-inference-server-httppackage from the pypi feed:python -m pip install azureml-inference-server-httpCreate your entry script (
score.py). The following example creates a basic entry script:echo ' import time def init(): time.sleep(1) def run(input_data): return {"message":"Hello, World!"} ' > score.pyStart the server (azmlinfsrv) and set
score.pyas the entry script:azmlinfsrv --entry_script score.pyNote
The server is hosted on 0.0.0.0, which means it will listen to all IP addresses of the hosting machine.
Send a scoring request to the server using
curl:curl -p 127.0.0.1:5001/scoreThe server should respond like this.
{"message": "Hello, World!"}
After testing, you can press Ctrl + C to terminate the server.
Now you can modify the scoring script (score.py) and test your changes by running the server again (azmlinfsrv --entry_script score.py).
How to integrate with Visual Studio Code
There are two ways to use Visual Studio Code (VS Code) and Python Extension to debug with azureml-inference-server-http package (Launch and Attach modes).
Launch mode: set up the
launch.jsonin VS Code and start the Azure Machine Learning inference HTTP server within VS Code.Start VS Code and open the folder containing the script (
score.py).Add the following configuration to
launch.jsonfor that workspace in VS Code:launch.json
{ "version": "0.2.0", "configurations": [ { "name": "Debug score.py", "type": "python", "request": "launch", "module": "azureml_inference_server_http.amlserver", "args": [ "--entry_script", "score.py" ] } ] }Start debugging session in VS Code. Select "Run" -> "Start Debugging" (or
F5).
Attach mode: start the Azure Machine Learning inference HTTP server in a command line and use VS Code + Python Extension to attach to the process.
Note
If you're using Linux environment, first install the
gdbpackage by runningsudo apt-get install -y gdb.Add the following configuration to
launch.jsonfor that workspace in VS Code:launch.json
{ "version": "0.2.0", "configurations": [ { "name": "Python: Attach using Process Id", "type": "python", "request": "attach", "processId": "${command:pickProcess}", "justMyCode": true }, ] }Start the inference server using CLI (
azmlinfsrv --entry_script score.py).Start debugging session in VS Code.
- In VS Code, select "Run" -> "Start Debugging" (or
F5). - Enter the process ID of the
azmlinfsrv(not thegunicorn) using the logs (from the inference server) displayed in the CLI.
Note
If the process picker does not display, manually enter the process ID in the
processIdfield of thelaunch.json.- In VS Code, select "Run" -> "Start Debugging" (or
In both ways, you can set breakpoint and debug step by step.
End-to-end example
In this section, we'll run the server locally with sample files (scoring script, model file, and environment) in our example repository. The sample files are also used in our article for Deploy and score a machine learning model by using an online endpoint
Clone the sample repository.
git clone --depth 1 https://github.com/Azure/azureml-examples cd azureml-examples/cli/endpoints/online/model-1/Create and activate a virtual environment with conda. In this example, the
azureml-inference-server-httppackage is automatically installed because it's included as a dependent library of theazureml-defaultspackage inconda.ymlas follows.# Create the environment from the YAML file conda env create --name model-env -f ./environment/conda.yml # Activate the new environment conda activate model-envReview your scoring script.
onlinescoring/score.py
import os import logging import json import numpy import joblib def init(): """ This function is called when the container is initialized/started, typically after create/update of the deployment. You can write the logic here to perform init operations like caching the model in memory """ global model # AZUREML_MODEL_DIR is an environment variable created during deployment. # It is the path to the model folder (./azureml-models/$MODEL_NAME/$VERSION) # Please provide your model's folder name if there is one model_path = os.path.join( os.getenv("AZUREML_MODEL_DIR"), "model/sklearn_regression_model.pkl" ) # deserialize the model file back into a sklearn model model = joblib.load(model_path) logging.info("Init complete") def run(raw_data): """ This function is called for every invocation of the endpoint to perform the actual scoring/prediction. In the example we extract the data from the json input and call the scikit-learn model's predict() method and return the result back """ logging.info("model 1: request received") data = json.loads(raw_data)["data"] data = numpy.array(data) result = model.predict(data) logging.info("Request processed") return result.tolist()Run the inference server with specifying scoring script and model file. The specified model directory (
model_dirparameter) will be defined asAZUREML_MODEL_DIRvariable and retrieved in the scoring script. In this case, we specify the current directory (./) since the subdirectory is specified in the scoring script asmodel/sklearn_regression_model.pkl.azmlinfsrv --entry_script ./onlinescoring/score.py --model_dir ./The example startup log will be shown if the server launched and the scoring script invoked successfully. Otherwise, there will be error messages in the log.
Test the scoring script with a sample data. Open another terminal and move to the same working directory to run the command. Use the
curlcommand to send an example request to the server and receive a scoring result.curl --request POST "127.0.0.1:5001/score" --header "Content-Type:application/json" --data @sample-request.jsonThe scoring result will be returned if there's no problem in your scoring script. If you find something wrong, you can try to update the scoring script, and launch the server again to test the updated script.
Server Routes
The server is listening on port 5001 (as default) at these routes.
| Name | Route |
|---|---|
| Liveness Probe | 127.0.0.1:5001/ |
| Score | 127.0.0.1:5001/score |
| OpenAPI (swagger) | 127.0.0.1:5001/swagger.json |
Server parameters
The following table contains the parameters accepted by the server:
| Parameter | Required | Default | Description |
|---|---|---|---|
| entry_script | True | N/A | The relative or absolute path to the scoring script. |
| model_dir | False | N/A | The relative or absolute path to the directory holding the model used for inferencing. |
| port | False | 5001 | The serving port of the server. |
| worker_count | False | 1 | The number of worker threads that will process concurrent requests. |
| appinsights_instrumentation_key | False | N/A | The instrumentation key to the application insights where the logs will be published. |
| access_control_allow_origins | False | N/A | Enable CORS for the specified origins. Separate multiple origins with ",". Example: "microsoft.com, bing.com" |
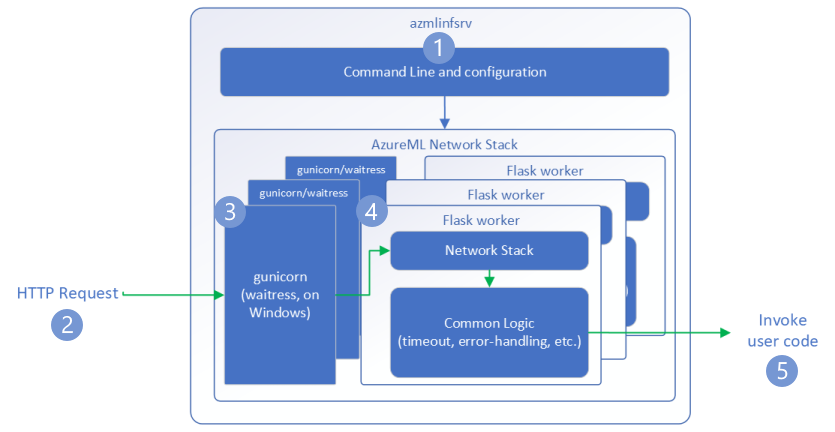
Request flow
The following steps explain how the Azure Machine Learning inference HTTP server (azmlinfsrv) handles incoming requests:
- A Python CLI wrapper sits around the server's network stack and is used to start the server.
- A client sends a request to the server.
- When a request is received, it goes through the WSGI server and is then dispatched to one of the workers.
- The requests are then handled by a Flask app, which loads the entry script & any dependencies.
- Finally, the request is sent to your entry script. The entry script then makes an inference call to the loaded model and returns a response.
Understanding logs
Here we describe logs of the Azure Machine Learning inference HTTP server. You can get the log when you run the azureml-inference-server-http locally, or get container logs if you're using online endpoints.
Note
The logging format has changed since version 0.8.0. If you find your log in different style, update the azureml-inference-server-http package to the latest version.
Tip
If you are using online endpoints, the log from the inference server starts with Azure Machine Learning Inferencing HTTP server <version>.
Startup logs
When the server is started, the server settings are first displayed by the logs as follows:
Azure Machine Learning Inferencing HTTP server <version>
Server Settings
---------------
Entry Script Name: <entry_script>
Model Directory: <model_dir>
Worker Count: <worker_count>
Worker Timeout (seconds): None
Server Port: <port>
Application Insights Enabled: false
Application Insights Key: <appinsights_instrumentation_key>
Inferencing HTTP server version: azmlinfsrv/<version>
CORS for the specified origins: <access_control_allow_origins>
Server Routes
---------------
Liveness Probe: GET 127.0.0.1:<port>/
Score: POST 127.0.0.1:<port>/score
<logs>
For example, when you launch the server followed the end-to-end example:
Azure Machine Learning Inferencing HTTP server v0.8.0
Server Settings
---------------
Entry Script Name: /home/user-name/azureml-examples/cli/endpoints/online/model-1/onlinescoring/score.py
Model Directory: ./
Worker Count: 1
Worker Timeout (seconds): None
Server Port: 5001
Application Insights Enabled: false
Application Insights Key: None
Inferencing HTTP server version: azmlinfsrv/0.8.0
CORS for the specified origins: None
Server Routes
---------------
Liveness Probe: GET 127.0.0.1:5001/
Score: POST 127.0.0.1:5001/score
2022-12-24 07:37:53,318 I [32726] gunicorn.error - Starting gunicorn 20.1.0
2022-12-24 07:37:53,319 I [32726] gunicorn.error - Listening at: http://0.0.0.0:5001 (32726)
2022-12-24 07:37:53,319 I [32726] gunicorn.error - Using worker: sync
2022-12-24 07:37:53,322 I [32756] gunicorn.error - Booting worker with pid: 32756
Initializing logger
2022-12-24 07:37:53,779 I [32756] azmlinfsrv - Starting up app insights client
2022-12-24 07:37:54,518 I [32756] azmlinfsrv.user_script - Found user script at /home/user-name/azureml-examples/cli/endpoints/online/model-1/onlinescoring/score.py
2022-12-24 07:37:54,518 I [32756] azmlinfsrv.user_script - run() is not decorated. Server will invoke it with the input in JSON string.
2022-12-24 07:37:54,518 I [32756] azmlinfsrv.user_script - Invoking user's init function
2022-12-24 07:37:55,974 I [32756] azmlinfsrv.user_script - Users's init has completed successfully
2022-12-24 07:37:55,976 I [32756] azmlinfsrv.swagger - Swaggers are prepared for the following versions: [2, 3, 3.1].
2022-12-24 07:37:55,977 I [32756] azmlinfsrv - AML_FLASK_ONE_COMPATIBILITY is set, but patching is not necessary.
Log format
The logs from the inference server are generated in the following format, except for the launcher scripts since they aren't part of the python package:
<UTC Time> | <level> [<pid>] <logger name> - <message>
Here <pid> is the process ID and <level> is the first character of the logging level – E for ERROR, I for INFO, etc.
There are six levels of logging in Python, with numbers associated with severity:
| Logging level | Numeric value |
|---|---|
| CRITICAL | 50 |
| ERROR | 40 |
| WARNING | 30 |
| INFO | 20 |
| DEBUG | 10 |
| NOTSET | 0 |
Troubleshooting guide
In this section, we'll provide basic troubleshooting tips for Azure Machine Learning inference HTTP server. If you want to troubleshoot online endpoints, see also Troubleshooting online endpoints deployment
Basic steps
The basic steps for troubleshooting are:
- Gather version information for your Python environment.
- Make sure the azureml-inference-server-http python package version that specified in the environment file matches the AzureML Inferencing HTTP server version that displayed in the startup log. Sometimes pip's dependency resolver leads to unexpected versions of packages installed.
- If you specify Flask (and or its dependencies) in your environment, remove them. The dependencies include
Flask,Jinja2,itsdangerous,Werkzeug,MarkupSafe, andclick. Flask is listed as a dependency in the server package and it's best to let our server install it. This way when the server supports new versions of Flask, you'll automatically get them.
Server version
The server package azureml-inference-server-http is published to PyPI. You can find our changelog and all previous versions on our PyPI page. Update to the latest version if you're using an earlier version.
- 0.4.x: The version that is bundled in training images ≤
20220601and inazureml-defaults>=1.34,<=1.43.0.4.13is the last stable version. If you use the server before version0.4.11, you may see Flask dependency issues like can't import nameMarkupfromjinja2. You're recommended to upgrade to0.4.13or0.8.x(the latest version), if possible. - 0.6.x: The version that is preinstalled in inferencing images ≤ 20220516. The latest stable version is
0.6.1. - 0.7.x: The first version that supports Flask 2. The latest stable version is
0.7.7. - 0.8.x: The log format has changed and Python 3.6 support has dropped.
Package dependencies
The most relevant packages for the server azureml-inference-server-http are following packages:
- flask
- opencensus-ext-azure
- inference-schema
If you specified azureml-defaults in your Python environment, the azureml-inference-server-http package is depended on, and will be installed automatically.
Tip
If you're using Python SDK v1 and don't explicitly specify azureml-defaults in your Python environment, the SDK may add the package for you. However, it will lock it to the version the SDK is on. For example, if the SDK version is 1.38.0, it will add azureml-defaults==1.38.0 to the environment's pip requirements.
Frequently asked questions
1. I encountered the following error during server startup:
TypeError: register() takes 3 positional arguments but 4 were given
File "/var/azureml-server/aml_blueprint.py", line 251, in register
super(AMLBlueprint, self).register(app, options, first_registration)
TypeError: register() takes 3 positional arguments but 4 were given
You have Flask 2 installed in your python environment but are running a version of azureml-inference-server-http that doesn't support Flask 2. Support for Flask 2 is added in azureml-inference-server-http>=0.7.0, which is also in azureml-defaults>=1.44.
If you're not using this package in an AzureML docker image, use the latest version of
azureml-inference-server-httporazureml-defaults.If you're using this package with an AzureML docker image, make sure you're using an image built in or after July, 2022. The image version is available in the container logs. You should be able to find a log similar to the following:
2022-08-22T17:05:02,147738763+00:00 | gunicorn/run | AzureML Container Runtime Information 2022-08-22T17:05:02,161963207+00:00 | gunicorn/run | ############################################### 2022-08-22T17:05:02,168970479+00:00 | gunicorn/run | 2022-08-22T17:05:02,174364834+00:00 | gunicorn/run | 2022-08-22T17:05:02,187280665+00:00 | gunicorn/run | AzureML image information: openmpi4.1.0-ubuntu20.04, Materializaton Build:20220708.v2 2022-08-22T17:05:02,188930082+00:00 | gunicorn/run | 2022-08-22T17:05:02,190557998+00:00 | gunicorn/run |The build date of the image appears after "Materialization Build", which in the above example is
20220708, or July 8, 2022. This image is compatible with Flask 2. If you don't see a banner like this in your container log, your image is out-of-date, and should be updated. If you're using a CUDA image, and are unable to find a newer image, check if your image is deprecated in AzureML-Containers. If it's, you should be able to find replacements.If you're using the server with an online endpoint, you can also find the logs under "Deployment logs" in the online endpoint page in Azure Machine Learning studio. If you deploy with SDK v1 and don't explicitly specify an image in your deployment configuration, it will default to using a version of
openmpi4.1.0-ubuntu20.04that matches your local SDK toolset, which may not be the latest version of the image. For example, SDK 1.43 will default to usingopenmpi4.1.0-ubuntu20.04:20220616, which is incompatible. Make sure you use the latest SDK for your deployment.If for some reason you're unable to update the image, you can temporarily avoid the issue by pinning
azureml-defaults==1.43orazureml-inference-server-http~=0.4.13, which will install the older version server withFlask 1.0.x.
2. I encountered an ImportError or ModuleNotFoundError on modules opencensus, jinja2, MarkupSafe, or click during startup like the following message:
ImportError: cannot import name 'Markup' from 'jinja2'
Older versions (<= 0.4.10) of the server didn't pin Flask's dependency to compatible versions. This problem is fixed in the latest version of the server.
Next steps
- For more information on creating an entry script and deploying models, see How to deploy a model using Azure Machine Learning.
- Learn about Prebuilt docker images for inference
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for