Introduction
In this module, we discuss a few popular NoSQL data stores: Apache HBase, MongoDB, and Apache Cassandra.
As you may recall from earlier in this unit, the NoSQL movement in databases was primarily motivated by the big-data challenges of scale and performance. As an example, Google's BigTable was created to handle the growing amounts of information that the company needed to proces. For example, Google's web index grew from 26 million pages in 1998 to over 1 trillion unique URLS in 2008. Processing such large amounts of data using a relational model becomes cumbersome if not impossible. In addition, big-data problems, such as web analytics, do not require the specific constraints and ACID guarantees that are provided by relational database management systems (RDBMSs) but instead can benefit from a flexible data model that relaxes some of the consistency guarantees for performance and scalability.
The adage "use the right tool for the job" is appropriate because NoSQL databases are not always the right fit for every kind of problem. NoSQL databases typically excel at managing large amounts of data that may not be fully structured (in a strict schema). Certain types of data can be represented better in one of the NoSQL database forms, such as a key-value, document, or graph database, rather than in the relational database model. Some NoSQL databases, such as Apache Cassandra, even support a fully nested data model, which allows for complex data structures to be present as a value in the database.
NoSQL databases are not a good fit in situations in which the data is fairly well structured and defined and may not exceed a few gigabytes or terabytes in size. Most NoSQL databases rely on a large number of machines organized as a cluster to process data in parallel. As an example, if HBase or Cassandra is run on a single node, the performance of either may not match that of MySQL or any other RDMBS product.
A good example of a nonrelational database that is a good fit for NoSQL databases is a webtable,as shown in the following figure. A we table is a data structure that holds results of a web crawl. A web crawl is the process of visiting a list of web pages and following the links in them in order to catalog and index the information that is contained in a web site.
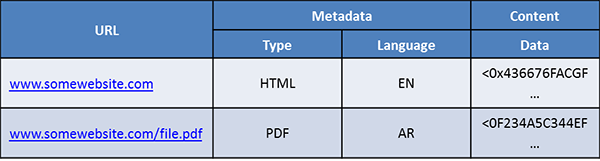
Figure 1: NoSQL webtable
Each unique URL in a web crawl can be stored as a row in a webtable, with the URL being the unique identifying characteristic of that row, which makes the URL the key. The columns of the webtable can store the binary content and metadata of the URL. As the webtable is parsed, new columns can be added with semantic information derived from the HTML content, such as the links of other pages in the URL object, and any other information. The webtable can also act as the database back end for a web archive service, such as an Internet archive, and hence clients can directly retrieve objects using the URL as the key.
Creating a webtable for a few URLs may be a simple task that can be handled by a traditional RDBMSs, but when billions of websites need to be crawled and their information has to be stored in a table that may be accessed by hundreds of thousands of clients simultaneously, then the data store is best maintained on a large cluster using a NoSQL solution.
Cloud object storage
Cloud object storage is an important facet in cloud storage, and is one of the earliest public cloud computing services to emerge.
Object storage is particularly important in web services. where static web content (images, videos and other files) can be stored in a place that is easily accessible to web clients. This allows the management and complexity of scaling, redundancy and accessibility of such storage systems to be abstracted away from a web application developer, choosing instead to work with a simple API to store and access such data. Another example of applications that benefit from object storage services are websites which feature a lot of user-generated content (such as social networks).
Learning objectives
In this module, you will:
- Explain the Apache HBase, Apache Cassandra and MongoDB NoSQL database data models.
- List the common operations in HBase, Cassandra, and MongoDB.
- Summarize the architectures of HBase, Cassandra, and MongoDB.
- List the use cases of HBase, Cassandra, and MongoDB.
- Explain the OpenStack Swift cloud object storage data models.
- Discuss the consistency guarantees provided by Swift.
Prerequisites
- Understand what cloud computing is, including cloud service models, and common cloud providers.
- Know the technologies that enable cloud computing.
- Understand how cloud service providers pay for and bill for the cloud.
- Know what datacenters are and why they exist.
- Know how datacenters are set up, powered, and provisioned.
- Understand how cloud resources are provisioned and metered.
- Be familiar with the concept of virtualization.
- Know what the different types of virtualization are.
- Understand CPU virtualization.
- Understand memory virtualization.
- Understand I/O virtualization.
- Know about the different types of data and how they are stored.
- Be familiar with distributed file systems and how they work.