Create health probes
A health probe allows your load balancer to monitor the status of your application. The probe dynamically adds or removes virtual machines from your load balancer rotation based on the machine response to health checks. When a probe fails to respond, the load balancer stops sending new connections to the unhealthy instance.
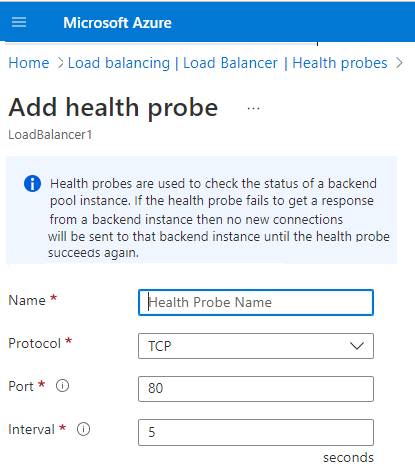
The following image shows how to create a health probe in the Azure portal. A custom HTTP health probe is configured to run on TCP port 80. The probe is defined to check the health of the virtual machine instances at 5-second intervals.
Things to know about health probes
There are two main ways to configure a custom health probe: HTTP and TCP.
In an HTTP probe, the load balancer probes your back-end pool endpoints every 15 seconds. A virtual machine instance is considered healthy if it responds with an HTTP 200 message within the specified timeout period (default is 31 seconds). If any status other than HTTP 200 is returned, the instance is considered unhealthy, and the probe fails.
A TCP probe relies on establishing a successful TCP session to a defined probe port. If the specified listener on the virtual machine exists, the probe succeeds. If the connection is refused, the probe fails.
To configure a probe, you specify values for the following settings:
- Port: Back-end port
- URI: URI for requesting the health status from the backend
- Interval: Amount of time between probe attempts (default is 15 seconds)
- Unhealthy threshold: Number of failures that must occur for the instance to be considered unhealthy
A Guest agent probe is a third option that uses the guest agent inside the virtual machine. This option isn't recommended when an HTTP or TCP custom probe configuration is possible.