Use the text to speech API
Similarly to its Speech to text APIs, the Azure AI Speech service offers other REST APIs for speech synthesis:
- The Text to speech API, which is the primary way to perform speech synthesis.
- The Batch synthesis API, which is designed to support batch operations that convert large volumes of text to audio - for example to generate an audio-book from the source text.
You can learn more about the REST APIs in the Text to speech REST API documentation. In practice, most interactive speech-enabled applications use the Azure AI Speech service through a (programming) language-specific SDK.
Using the Azure AI Speech SDK
As with speech recognition, in practice most interactive speech-enabled applications are built using the Azure AI Speech SDK.
The pattern for implementing speech synthesis is similar to that of speech recognition:
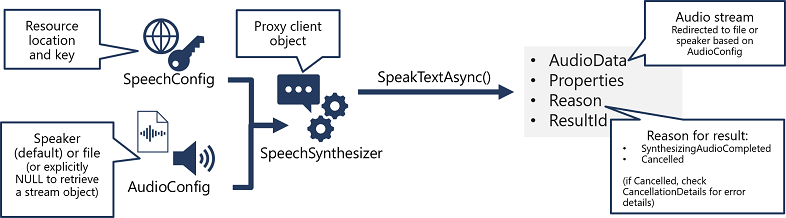
- Use a SpeechConfig object to encapsulate the information required to connect to your Azure AI Speech resource. Specifically, its location and key.
- Optionally, use an AudioConfig to define the output device for the speech to be synthesized. By default, this is the default system speaker, but you can also specify an audio file, or by explicitly setting this value to a null value, you can process the audio stream object that is returned directly.
- Use the SpeechConfig and AudioConfig to create a SpeechSynthesizer object. This object is a proxy client for the Text to speech API.
- Use the methods of the SpeechSynthesizer object to call the underlying API functions. For example, the SpeakTextAsync() method uses the Azure AI Speech service to convert text to spoken audio.
- Process the response from the Azure AI Speech service. In the case of the SpeakTextAsync method, the result is a SpeechSynthesisResult object that contains the following properties:
- AudioData
- Properties
- Reason
- ResultId
When speech has been successfully synthesized, the Reason property is set to the SynthesizingAudioCompleted enumeration and the AudioData property contains the audio stream (which, depending on the AudioConfig may have been automatically sent to a speaker or file).