SQL Server
Optimizing SQL Server Query Performance
Maciej Pilecki
At a Glance:
- Analyzing execution plans
- Optimizing queries
- Identifying queries to tune
When optimizing your database server, you need to tune the performance of individual queries. This is as important as—perhaps even more important than—tuning other aspects of your server installation, that affect performance, such as hardware and software configurations.
Even if your database server runs on the most powerful hardware available, its performance can be negatively affected by a handful of misbehaving queries. In fact, even one bad query, sometimes called a "runaway query," can cause serious performance issues for your database.
Conversely, the overall performance of your database can be greatly improved by tuning a set of most expensive or most often executed queries. In this article, I will look at some of the techniques you can employ to identify and tune the most expensive and worst performing queries on your server.
Analyzing Execution Plans
When tuning an individual query, you usually start by looking at the execution plan of that query. The execution plan describes the sequence of operations, physical and logical, that SQL ServerTM will perform in order to fulfill the query and produce the desired resultset. The execution plan is produced by a database engine component called Query Optimizer during the optimization phase of query processing—this takes into account many different factors, such as the search predicates used in the query, the tables involved and their join conditions, the list of columns returned, and the presence of useful indexes that can serve as efficient access paths to the data.
For complex queries, the number of all possible permutations can be huge, so the query optimizer does not evaluate all possibilities but instead tries to find a plan that is "good enough" for a given query. This is because finding a perfect plan may not always be possible; and even when it is possible, the cost of evaluating all the possibilities to find the perfect plan could easily outweigh any performance gains. From a DBA point of view, it is important to understand the process and its limitations.
There are a number of ways to retrieve an execution plan for a query:
- Management Studio provides Display Actual Execution Plan and Display Estimated Execution Plan features, which present the plan in a graphical way. These features offer the most suitable solution for direct examination and are by far the most often-used approach to display and analyze execution plans. (In this article, I will use graphical plans generated in this way to illustrate my examples.)
- Various SET options, such as SHOWPLAN_XML and SHOWPLAN_ALL, return the execution plan as either an XML document describing the plan using a special schema or a rowset with textual description of each of the operations in the execution plan.
- SQL Server Profiler event classes, such as Showplan XML, allow you to gather execution plans of statements collected by a trace.
While an XML representation of the execution plan may not be the easiest format for a human to read, this option does allow you to write procedures and utilities that can analyze your execution plans, looking for signs of performance problems and suboptimal plans. An XML-based representation can also be saved to a file with the .sqlplan extension and then opened in the Management Studio to produce a graphical representation. These files can also be saved for later analysis, eliminating, of course, the need to reproduce the execution plan each time you want to analyze it. This is especially useful when you want to compare your plans to see how they change over time.
Estimated Cost of Execution
The first thing you have to understand about execution plans is how they are generated. SQL Server uses a cost-based query optimizer—that is, it tries to generate an execution plan with the lowest estimated cost. The estimate is based on the data distribution statistics that are available to the optimizer when it evaluates each table involved in the query. If those statistics are missing or outdated, the query optimizer will lack vital information that it needs for the query optimization process and therefore its estimates will likely be off the mark. In such cases, the optimizer will choose a less than optimal plan by either overestimating or underestimating the execution costs of different plans.
There are some common false assumptions about the estimated execution cost. In particular, people often assume that the estimated execution cost is a good indicator of how much time the query will take to execute and that this estimate allows you to distinguish good plans from bad plans. This is not true. First, it is sufficiently documented what the units for expressing the estimated cost are and if they have any direct relation to the time of execution. Second, since this is an estimate and can be wrong, plans with higher estimated costs can sometimes be much more efficient in terms of CPU, I/O, and time of execution, despite their higher estimates. This is often the case with queries that involve table variables—since no statistics are available for table variables, query optimizer always assumes that a table variable contains just one row, even if it contains many times that. Thus, query optimizer will choose a plan based on an inaccurate estimate. Therefore, when comparing the execution plans of your queries, you should not rely on estimated query cost alone. Instead, include the output of the STATISTICS I/O and STATISTICS TIME options in the analysis to understand of what the real cost execution is in terms of I/O and CPU time.
One special type of execution plan, called a parallel plan, is worth mentioning here. If you are running your query on a server with more than one CPU and your query is eligible for parallelization, a parallel plan may be chosen. (Generally, the query optimizer will only consider a parallel plan for a query that has a cost exceeding a certain configurable threshold.) Due to the overhead of managing multiple parallel threads of execution (meaning distributing work across threads, performing synchronization, and gathering results), parallel plans cost more to execute and that is reflected in their estimated cost. So why are they preferred over cheaper, non-parallel plans? Thanks to using the processing power of multiple CPUs, parallel plans tend to yield results faster than standard plans. Depending on your specific scenario, including such variables as available resources and concurrent load from other queries, this situation may be desirable for your setup. If so, you should control which of your queries can produce parallel plans and how many CPUs each can utilize. You do this by setting the max degree of parallelism option on the server level and overriding it on individual query level with OPTION (MAXDOP n) as needed.
Analyzing an Execution Plan
Now I'll look at a simple query, its execution plan, and some ways to improve its performance. Say I execute this query using Management Studio with the Include Actual Execution Plan option turned on in the Adventure Works sample database on SQL Server 2005:
SELECT c.CustomerID, SUM(LineTotal)
FROM Sales.SalesOrderDetail od
JOIN Sales.SalesOrderHeader oh
ON od.SalesOrderID=oh.SalesOrderID
JOIN Sales.Customer c ON oh.CustomerID=c.CustomerID
GROUP BY c.CustomerID
As a result, I see the execution plan depicted in Figure 1. This simple query calculates the total amount of orders placed by each customer of Adventure Works. Looking at the execution plan, you can see how the database engine processes the query and produces the result. Graphical execution plans should be read from top to bottom and from right to left. Each icon represents a logical and physical operation performed, and arrows show data flow between operations. The thickness of the arrows represents the number of rows being passed between operations—the thicker the arrow, the more rows involved. If you place your pointer over one of the operator icons, a yellow ToolTip (like the one shown in Figure 2) will display details of that particular operation.
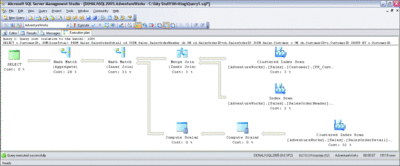
Figure 1 Sample execution plan (Click the image for a larger view)
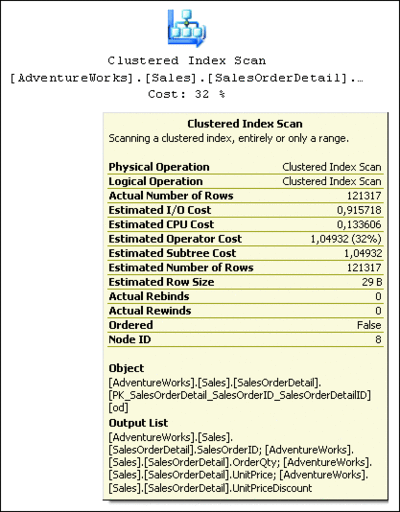
Figure 2 Details about an operation (Click the image for a larger view)
Looking at each of the operators, you can analyze the sequence of steps performed:
- The database engine performs a Clustered Index Scan operation on the Sales.Customer table and returns the CustomerID column for all the rows in that table.
- It then performs an Index Scan (meaning a non-clustered index scan) on one of the indexes in the Sales.SalesOrderHeader table. This is an index on the CustomerID column, but it also implicitly includes the SalesOrderID column (the table clustering key). The values from both of those columns are returned by the scan.
- Output from both scans is joined on the CustomerID column using the Merge Join physical operator. (This is one of three possible physical ways of performing a logical join operation. It's fast but requires both inputs to be sorted on a joined column. In this case, both scan operations have already returned the rows sorted on CustomerID so there is no need to perform the additional sort operation).
- Next, the database engine performs a scan of the clustered index on the table Sales.SalesOrderDetail, retrieving the values of four columns (SalesOrderID, OrderQty, UnitPrice, and UnitPriceDiscount) from all rows in this table. (There were 123,317 rows estimated to be returned by this operation and that number was actually returned, as you can see from the Estimated Number of Rows and Actual Number of Rows properties in Figure 2—so the estimate was very accurate.)
- Rows produced by the clustered index scan are passed to the first Compute Scalar operator so that the value of the computed column LineTotal can be calculated for each row, based on the OrderQty, UnitPrice, and UnitPriceDiscount columns involved in the formula.
- The second Compute Scalar operator applies the ISNULL function to the result of the previous calculation, as required by the computed column formula. This completes the calculation of the LineTotal column and returns it, along with column SalesOrderID, to the next operator.
- The output of the Merge Join operator in Step 3 is joined with the output of the Compute Scalar operator from Step 6, using the Hash Match physical operator.
- Another Hash Match operator is then applied to group rows returned from Merge Join by the CustomerID column value and calculated SUM aggregate of the LineTotal column.
- The last node, SELECT, is not a physical or logical operator but rather a place holder that represents the overall query results and cost.
On my laptop, this execution plan had an estimated cost of 3,31365 (as shown in Figure 3). When executed with STATISTICS I/O ON, the query reported performing a total of 1,388 logical read operations across the three tables involved. The percentages displayed under each of the operators represent the cost of each individual operator relative to the overall estimated cost of the whole execution plan. Looking at the plan in Figure 1, you can see that most of the total cost of the entire execution plan is associated with the following three operators: the Clustered Index Scan of the Sales.SalesOrderDetail table and the two Hash Match operators. But before I move to optimize those, I would like to point out a very simple change in my query that will allow me to eliminate two of the operators altogether.
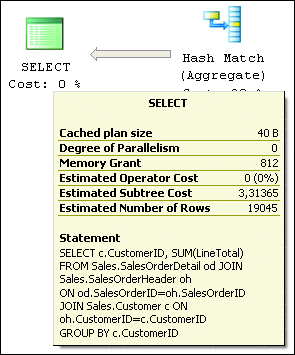
Figure 3 Total estimated execution cost of the query
Since the only column I am returning from the Sales.Customer table is CustomerID, and this column is also included as a foreign key in the Sales.SalesOrderHeaderTable, I can completely eliminate the Customer table from the query without changing the logical meaning or the result produced by our query by using this code:
SELECT oh.CustomerID, SUM(LineTotal)
FROM Sales.SalesOrderDetail od JOIN Sales.SalesOrderHeader oh
ON od.SalesOrderID=oh.SalesOrderID
GROUP BY oh.CustomerID
This results in a different execution plan, which is shown in Figure 4.

Figure 4 The execution plan after eliminating Customer table from the query (Click the image for a larger view)
Two operations were eliminated entirely—the Clustered Index Scan on Customer table and the Merge Join between Customer and SalesOrderHeader—and the Hash Match join was replaced by the much more efficient Merge Join. However, in order to use Merge Join between the SalesOrderHeader and SalesOrderDetail tables, the rows from both tables had to be returned sorted by the join column SalesOrderID. To achieve this, the query optimizer decided to perform a Clustered Index Scan on the SalesOrderHeader table, instead of using the Non-Clustered Index Scan, which would have been cheaper in terms of the I/O involved. This is a good example of how the query optimizer works in practice—since the cost savings from changing the physical way of performing the join operation were more than the additional I/O cost generated by the Clustered Index Scan, the query optimizer chose the resulting combination of operators because it gave the lowest total estimated execution cost possible. On my laptop, even though the number of logical reads went up (to 1,941), the CPU time being consumed was actually smaller and the estimated execution cost of this query was down about 13 percent (2,89548).
Say I want to further improve the performance of this query. Now I look at the Clustered Index Scan of the SalesOrderHeader table, which has become the most expensive operator in this execution plan. Since I only need two columns from this table to fulfill the query, I can create a non-clustered index that contains just those two columns—replacing the scan of the whole table with a scan of the much smaller non-clustered index. The index definition might look something like this:
CREATE INDEX IDX_OrderDetail_OrderID_TotalLine
ON Sales.SalesOrderDetail (SalesOrderID) INCLUDE (LineTotal)
Notice that the index I've created includes a computed column. This is not always possible, depending of the definition of the computed column.
After creating this index and executing the same query, I get the new execution plan shown in Figure 5.

Figure 5 Optimized execution plan (Click the image for a larger view)
The clustered index scan on the SalesOrderDetail table has been replaced by a non-clustered index scan with a significantly lower I/O cost. I have also eliminated one of the Compute Scalar operators, as my index includes an already calculated value of the LineTotal column. The estimated execution plan cost is now 2,28112 and the query performs 1,125 logical reads when executed.
The Covering Index
Customer Order Query Exercise
Q Here's your customer order query exercise: try figuring out the index definition—which columns it should contain to become covering index for this query and if the order of columns in the index definition would make a difference in performance.
A I challenged you to figure out the most optimal covering index to create on Sales.SalesOrderHeader table for the example query in my article. In order to achieve this, the first thing you should note is that the query uses only two columns from the table: CustomerID and SalesOrderID. If you have read my article carefully, you will have noticed that in the case of the SalesOrderHeader table, there is already an existing index that covers this query—it's the index on CustomerID and it implicitly contains the SalesOrderID column, which is the clustering key of the table.
Of course, I also explained why the query optimizer decided not to use this index. Yes, you could force the query optimizer to use this index, but the solution would be less efficient than the existing plan that uses Clustered Index Scan and Merge Join operators. This is because you would be forcing the query optimizer to make a choice between either performing an additional Sort operation in order to be able to still use Merge Join or falling back to using a less efficient Hash Join. Both options have a higher estimated execution cost than the existing plan (the version with Sort operation would perform particularly poorly), so the query optimizer will not use them unless it is forced to do so. So, in this situation, the only index that will perform better than the Clustered Index Scan is a non-clustered index on SalesOrderID, CustomerID. But it is important to note that the columns must be in that exact order:
CREATE INDEX IDX_OrderHeader_SalesOrderID_CustomerID
ON Sales.SalesOrderHeader (SalesOrderID, CustomerID)
If you create this index, the execution plan will contain the Index Scan rather than the Clustered Index Scan operator. This is a significant difference. In this case, the non-clustered index containing just two columns is much smaller than the whole table in the form of clustered index. Therefore, it will require less I/O to read the necessary data.
This example also shows how the order of columns in your index can have a significant impact on how useful it is for the query optimizer. Be sure to keep this in mind when you design multi-column indexes
The index I have created on SalesOrderDetail is an example of the so-called "covering index". It is a non-clustered index that contains all the columns needed to fulfill the query, eliminating the need to scan the whole table using either the Table Scan or Clustered Index Scan operators. The index is in essence a smaller copy of the table, containing a subset of columns from the table. Only those columns needed to answer the query (or queries) are included in the index—in other words, the index contains just what it needs to "cover" the query.
Creating covering indexes for the most frequently executed queries is one of the easiest and most common techniques used in query tuning. It works particularly well in situations where the table contains a number of columns but only a few of them are frequently referenced by queries. By creating one or more covering indexes, you can greatly improve the performance of the affected queries, as they will be accessing a much smaller amount of data and, in turn, incurring less I/O. There is, however, a hidden cost of maintaining additional indexes during data modification operations (INSERT, UPDATE, and DELETE). Depending on your environment and the ratio between SELECT queries and data modifications, you should carefully judge whether this additional index maintenance overhead is justified by query performance improvements.
Don't be afraid of creating multicolumn indexes, as opposed to single-column indexes. These tend to be much more useful than single-column indexes and the query optimizer is more likely to use them to cover the query. Most covering indexes are multicolumn indexes.
In the case of my sample query, there is still some room for improvement, and this query could be further optimized by placing a covering index on the SalesOrderHeader table. This eliminates the Clustered Index Scan in favor of a non-clustered Index Scan. I will leave this as an exercise for you. Try figuring out the index definition—which columns it should contain to become a covering index for this query and if the order of columns in the index definition would make a difference in performance. See the "Customer Order Query Exercise" sidebar for the solution.
Indexed Views
If the performance of my example query is very important, I can go one step further and create an indexed view that physically stores the materialized results of the query. There are certain prerequisites and limitations of indexed views, but if one can be used, it can improve performance dramatically. Keep in mind that indexed views carry a higher maintenance cost than standard indexes. As a result, you should be careful about when you use them. In this case, the index definition looks like this:
CREATE VIEW vTotalCustomerOrders
WITH SCHEMABINDING
AS
SELECT oh.CustomerID, SUM(LineTotal) AS OrdersTotalAmt, COUNT_BIG(*) AS TotalOrderLines
FROM Sales.SalesOrderDetail od
JOIN Sales.SalesOrderHeader oh
ON od.SalesOrderID=oh.SalesOrderID
GROUP BY oh.CustomerID
Note the WITH SCHEMABINDING option, which is a prerequisite for creating an index on such a view, and the COUNT_BIG(*) function, which is necessary if our index definition contains an aggregate function (in this example, SUM). After I create this view, I can create an index on it, like so:
CREATE UNIQUE CLUSTERED INDEX CIX_vTotalCustomerOrders_CustomerID
ON vTotalCustomerOrders(CustomerID)
When I create this index, the result of the query included in the view definition is materialized and physically stored on disk in the index. Note that all data modification operations on the base tables then automatically update the values in the view according to its definition.
If I now rerun the query, what will happen depends on which edition of SQL Server I am running. On the Enterprise or Developer editions, the query optimizer will automatically match this query with the indexed view definition and use the indexed view instead of querying the base tables involved. Figure 6 shows the execution plan produced in this case. It consists of only one operation—a Clustered Index Scan of the index that I created on the view. The estimated execution cost is only 0,09023 and it performs only 92 logical reads.
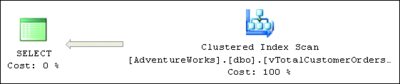
Figure 6 Execution plan when using indexed view (Click the image for a larger view)
You can still create and use this indexed view on other editions of SQL Server, but to achieve the same effect you have to change the query to reference the view directly using the NOEXPAND hint, like this:
SELECT CustomerID, OrdersTotalAmt
FROM vTotalCustomerOrders WITH (NOEXPAND)
As you can see, indexed views can be a very powerful feature if used properly. They are most useful for optimizing queries that perform aggregations over large amounts of data. If used on Enterprise edition, they can benefit many queries without requiring changes to your code.
Identifying Which Queries to Tune
How do I identify the queries that are worth tuning? I look for the queries that are executed frequently—they may not have a very high cost of single execution, but the aggregated cost of execution can be much higher than that of a large query that is rarely executed. I am not saying you shouldn't tune the big ones, I just believe that you should first concentrate on the most frequently executed queries. So how do you identify them?
Unfortunately, the most reliable method is somewhat complicated and involves performing a trace of all queries executed against your server and then grouping them by their signatures. (That is, query text with the actual parameter values replaced by placeholders in order to identify the same query type, even if it was executed with different parameter values.) This is a complicated process, as query signatures are difficult to generate. Itzik Ben-Gan describes a solution using CLR user-defined functions and regular expressions in his book Inside Microsoft SQL Server 2005: T-SQL Querying.
There is another much simpler, though somewhat less reliable, method. You can rely on statistics that are kept for all queries in the execution plan cache and query them using dynamic management views. Figure 7 contains a sample query that shows you both the text and the execution plan of the 20 queries in your cache with the highest accumulated number of logical reads. This query is very handy for quickly identifying the queries that are generating the highest number of logical reads—but it has limitations. That is, it will only show the queries that have their plans cached at the time you run the query. If something is not cached, you will miss it.
Figure 7 Identifying top 20 most expensive queries in terms of read I/O
SELECT TOP 20 SUBSTRING(qt.text, (qs.statement_start_offset/2)+1,
((CASE qs.statement_end_offset
WHEN -1 THEN DATALENGTH(qt.text)
ELSE qs.statement_end_offset
END - qs.statement_start_offset)/2)+1),
qs.execution_count,
qs.total_logical_reads, qs.last_logical_reads,
qs.min_logical_reads, qs.max_logical_reads,
qs.total_elapsed_time, qs.last_elapsed_time,
qs.min_elapsed_time, qs.max_elapsed_time,
qs.last_execution_time,
qp.query_plan
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) qt
CROSS APPLY sys.dm_exec_query_plan(qs.plan_handle) qp
WHERE qt.encrypted=0
ORDER BY qs.total_logical_reads DESC
Once you have identified these poor performers, take a look at their query plans and search for ways to improve their performance by using some of the indexing techniques I've described in this article. If you succeed, it will be time well invested.
Happy tuning!
Maciej Pilecki is an Associate Mentor with Solid Quality Mentors, a global organization that specializes in training, mentoring, and consulting. He is a Microsoft Certified Trainer (MCT) and SQL Server Most Valuable Professional (MVP), frequently delivering courses and conference speeches on many aspects of SQL Server and application development.
© 2008 Microsoft Corporation and CMP Media, LLC. All rights reserved; reproduction in part or in whole without permission is prohibited.