High availability and data protection for availability group configurations
Applies to: ![]() SQL Server - Linux
SQL Server - Linux
This article presents supported deployment configurations for SQL Server Always On availability groups on Linux servers. An availability group supports high availability and data protection. Automatic failure detection, automatic failover, and transparent reconnection after failover provide high availability. Synchronized replicas provide data protection.
On a Windows Server Failover Cluster (WSFC), a common configuration for high availability uses two synchronous replicas and a third server or file share to provide quorum. The file-share witness validates the availability group configuration - status of synchronization, and the role of the replica, for example. This configuration ensures that the secondary replica chosen as the failover target has the latest data and availability group configuration changes.
The WSFC synchronizes configuration metadata for failover arbitration between the availability group replicas and the file-share witness. When an availability group is not on a WSFC, the SQL Server instances store configuration metadata in the master database.
For example, an availability group on a Linux cluster has CLUSTER_TYPE = EXTERNAL. There is no WSFC to arbitrate failover. In this case the configuration metadata is managed and maintained by the SQL Server instances. Because there is no witness server in this cluster, a third SQL Server instance is required to store configuration state metadata. All three SQL Server instances together provide distributed metadata storage for the cluster.
The cluster manager can query the instances of SQL Server in the availability group, and orchestrate failover to maintain high availability. In a Linux cluster, Pacemaker is the cluster manager.
SQL Server 2017 CU 1 enables high availability for an availability group with CLUSTER_TYPE = EXTERNAL for two synchronous replicas plus a configuration only replica. The configuration only replica can be hosted on any edition of SQL Server 2017 CU1 or later - including SQL Server Express edition. The configuration only replica maintains configuration information about the availability group in the master database but does not contain the user databases in the availability group.
How the configuration affects default resource settings
SQL Server 2017 introduces the REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT cluster resource setting. This setting guarantees the specified number of secondary replicas write the transaction data to log before the primary replica commits each transaction. When you use an external cluster manager, this setting affects both high availability and data protection. The default value for the setting depends on the architecture at the time the cluster resource is created. When you install the SQL Server resource agent - mssql-server-ha - and create a cluster resource for the availability group, the cluster manager detects the availability group configuration and sets REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT accordingly.
If supported by the configuration, the resource agent parameter REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT is set to the value that provides high availability and data protection. For more information, see Understand SQL Server resource agent for pacemaker.
The following sections explain the default behavior for the cluster resource.
Choose an availability group design to meet specific business requirements for high availability, data protection, and read-scale.
The following configurations describe the availability group design patterns and the capabilities of each pattern. These design patterns apply to availability groups with CLUSTER_TYPE = EXTERNAL for high availability solutions.
- Three synchronous replicas
- Two synchronous replicas
- Two synchronous replicas and a configuration only replica
Three synchronous replicas
This configuration consists of three synchronous replicas. By default, it provides high availability and data protection. It can also provide read-scale.
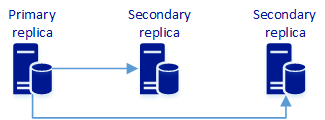
An availability group with three synchronous replicas can provide read-scale, high availability, and data protection. The following table describes availability behavior.
| Availability behavior | read-scale | High availability & data protection |
Data protection |
|---|---|---|---|
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT= |
0 | 1 1 | 2 |
| Primary outage | Automatic failover. Might have data loss. New primary is R/W. | Automatic failover. New primary is R/W. | Automatic failover. New primary is not available for user update transactions until former primary recovers and joins availability group as secondary. |
| One secondary replica outage | Primary is R/W. | Primary is R/W. | Primary is not available for user update transactions until failed secondary recovers and joins availability group. |
1 Default
Two synchronous replicas
This configuration enables data protection. Like the other availability group configurations, it can enable read-scale. The two synchronous replicas configuration does not provide automatic high availability. A two replica configuration is only applicable to SQL Server 2017 RTM and is no longer supported with higher (CU1 and beyond) versions of SQL Server 2017..
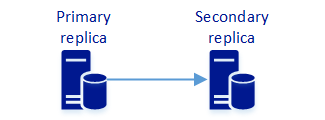
An availability group with two synchronous replicas provides read-scale and data protection. The following table describes availability behavior.
| Availability behavior | read-scale | Data protection |
|---|---|---|
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT= |
0 1 | 1 |
| Primary outage | Automatic failover. Might have data loss. New primary is R/W. | Automatic failover. New primary is not available for user update transactions until former primary recovers and joins availability group as secondary. |
| One secondary replica outage | Primary is R/W, running exposed to data loss. | Primary is not available for user update transactions until secondary recovers. |
1 Default
Two synchronous replicas and a configuration only replica
An availability group with two (or more) synchronous replicas and a configuration only replica provides data protection and might also provide high availability. The following diagram represents this architecture:
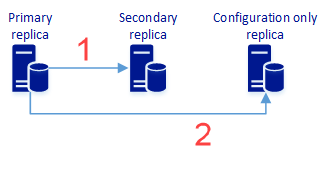
- Synchronous replication of user data to the secondary replica. It also includes availability group configuration metadata.
- Synchronous replication of availability group configuration metadata. It does not include user data.
In the availability group diagram, a primary replica pushes configuration data to both the secondary replica and the configuration only replica. The secondary replica also receives user data. The configuration only replica does not receive user data. The secondary replica is in synchronous availability mode. The configuration only replica does not contain the databases in the availability group - only metadata about the availability group. Configuration data on the configuration only replica is committed synchronously.
Note
An availability group with configuration only replica is new for SQL Server 2017 CU1. All instances of SQL Server in the availability group must be SQL Server 2017 CU1 or later.
The default value for REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT is 0. The following table describes availability behavior.
| Availability behavior | High availability & data protection |
Data protection |
|---|---|---|
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT= |
0 1 | 1 |
| Primary outage | Automatic failover. New primary is R/W. Might have data loss. | Automatic failover. New primary is not available for user update transactions. |
| Secondary replica outage | Primary is R/W, running exposed to data loss (if primary fails and cannot be recovered). No automatic failover if primary fails as well. | Primary is not available for user update transactions. No replica to fail over to if primary fails as well. |
| Configuration only replica outage | Primary is R/W. No automatic failover if primary fails as well. | Primary is R/W. No automatic failover if primary fails as well. |
| Synchronous secondary + configuration only replica outage | Primary is not available for user update transactions. No automatic failover. | Primary is not available for user update transactions. No replica to failover to if primary fails as well. |
1 Default
Note
The instance of SQL Server that hosts the configuration only replica can also host other databases. It can also participate as a configuration only database for more than one availability group.
Requirements
- All replicas in an availability group with a configuration only replica must be SQL Server 2017 CU 1 or later.
- Any edition of SQL Server can host a configuration only replica, including SQL Server Express.
- The availability group needs at least one secondary replica - in addition to the primary replica.
- Configuration only replicas do not count towards the maximum number of replicas per instance of SQL Server. SQL Server standard edition allows up to three replicas, SQL Server Enterprise Edition allows up to 9.
Considerations
- No more than one configuration only replica per availability group.
- A configuration only replica cannot be a primary replica.
- You cannot modify the availability mode of a configuration only replica. To change from a configuration only replica to a synchronous or asynchronous secondary replica, remove the configuration only replica, and add a secondary replica with the required availability mode.
- A configuration only replica is synchronous with the availability group metadata. There is no user data.
- An availability group with one primary replica and one configuration only replica, but no secondary replica is not valid.
- You cannot create an availability group on an instance of SQL Server Express edition.
Understand SQL Server resource agent for Pacemaker
SQL Server 2017 (14.x) introduced sequence_number to sys.availability_groups to show if a replica marked as SYNCHRONOUS_COMMIT was up to date. sequence_number is a monotonically increasing BIGINT that represents how up-to-date the local availability group replica is with respect to the rest of the replicas in the availability group. Performing failovers, adding or removing replicas, and other availability group operations update this number. The number is updated on the primary, then pushed to secondary replicas. Thus a secondary replica that is up-to-date has the same sequence_number as the primary.
When Pacemaker decides to promote a replica to primary, it first sends a notification to all replicas to extract the sequence number and store it (this notification is called the pre-promote notification). Next, when Pacemaker tries to promote a replica to primary, the replica only promotes itself if its sequence number is the highest of all the sequence numbers from all replicas, otherwise it rejects the promote operation. In this way only the replica with the highest sequence number can be promoted to primary, ensuring no data loss.
Promotion is only guaranteed to work as long as at least one replica available for promotion has the same sequence number as the previous primary. The default behavior is for the Pacemaker resource agent to automatically set REQUIRED_COPIES_TO_COMMIT such that at least one synchronous commit secondary replica is up to date and available, to be the target of an automatic failover. With each monitoring action, the value of REQUIRED_COPIES_TO_COMMIT is computed (and updated if necessary) as ('number of synchronous commit replicas' / 2). Then, at failover time, the resource agent requires (total number of replicas - required_copies_to_commit replicas) to respond to the pre-promote notification to be able to promote one of them to primary. The replica with the highest sequence_number is promoted to primary.
For example, let's consider the case of an availability group with three synchronous replicas - one primary replica and two synchronous commit secondary replicas.
REQUIRED_COPIES_TO_COMMITis 3 / 2 = 1The required number of replicas to respond to pre-promote action is 3 - 1 = 2. So two replicas have to be up for the failover to be triggered. When a primary outage occurs, if one of the secondary replicas is unresponsive and only one of the secondaries responds to the pre-promote action, the resource agent can't guarantee that the secondary that responded has the highest
sequence_number, and a failover isn't triggered.
A user can choose to override the default behavior, and configure the availability group resource to not set REQUIRED_COPIES_TO_COMMIT automatically as shown previously.
Important
When REQUIRED_COPIES_TO_COMMIT is 0 there's risk of data loss. In the case of an outage of the primary, the resource agent will not automatically trigger a failover. The user has to decide if they want to wait for primary to recover or manually fail over.
To set REQUIRED_COPIES_TO_COMMIT to 0, run:
sudo pcs resource update <ag_cluster> required_copies_to_commit=0
The equivalent command using crm (on SLES) is:
sudo crm resource param <ag_cluster> set required_synchronized_secondaries_to_commit 0
To revert to default computed value, run:
sudo pcs resource update <ag_cluster> required_copies_to_commit=
Note
Updating resource properties causes all replicas to stop and restart. This means primary will temporarily be demoted to secondary, then promoted again which will cause temporary write unavailability. The new value for REQUIRED_COPIES_TO_COMMIT will only be set once replicas are restarted, so it won't be instantaneous with running the pcs command.
Balance high availability and data protection
The above default behavior applies to the case of two synchronous replicas (primary + secondary) as well. Pacemaker defaults REQUIRED_COPIES_TO_COMMIT = 1 to ensure the secondary replica is always up to date for maximum data protection.
Warning
This comes with higher risk of unavailability of the primary replica due to planned or unplanned outages on the secondary. The user can choose to change the default behavior of the resource agent and override the REQUIRED_COPIES_TO_COMMIT to 0:
sudo pcs resource update <ag1> required_copies_to_commit=0
Once overridden, the resource agent uses the new setting for REQUIRED_COPIES_TO_COMMIT and stops computing it. Users have to manually update it accordingly (for example, if they increase the number of replicas).
The following tables describe the outcome of an outage for primary or secondary replicas in different availability group resource configurations:
Availability group - two sync replicas
| Configuration | Primary outage | One secondary replica outage |
|---|---|---|
REQUIRED_COPIES_TO_COMMIT = 0 |
User has to issue a manual FAILOVER.Might have data loss. New primary is R/W |
Primary is R/W, running exposed to data loss. |
REQUIRED_COPIES_TO_COMMIT = 1 1 |
Cluster automatically issues FAILOVERNo data loss. New primary rejects all connections until former primary recovers and joins availability group as secondary. |
Primary rejects all connections until secondary recovers. |
1 SQL Server resource agent for Pacemaker default behavior.
Availability group - three sync replicas
| Configuration | Primary outage | One secondary replica outage |
|---|---|---|
REQUIRED_COPIES_TO_COMMIT = 0 |
User has to issue a manual FAILOVER.Might have data loss. New primary is R/W |
Primary is R/W |
REQUIRED_COPIES_TO_COMMIT = 1 1 |
Cluster automatically issues FAILOVER.No data loss. New primary is RW |
Primary is R/W |
1 SQL Server resource agent for Pacemaker default behavior.
Related content
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for