Consulta de datos en Azure Data Lake con Azure Data Explorer
Azure Data Lake Storage es una solución de lago de datos rentable y muy escalable para el análisis de macrodatos. Combina el potencial de un sistema de archivos de alto rendimiento con una escala masiva y rentabilidad para ayudarle a obtener conclusiones con rapidez. Data Lake Storage Gen2 amplía la funcionalidad de Azure Blob Storage y está optimizado para cargas de trabajo analíticas.
Azure Data Explorer se integra con Azure Blob Storage y Azure Data Lake Storage (Gen1 y Gen2) para ofrecer un acceso rápido, indexado y en caché a los datos almacenados en una solución de almacenamiento externo. Los datos se pueden analizar y consultar sin una ingesta previa en Azure Data Explorer. También es posible consultar simultáneamente datos externos ingeridos y sin ingerir. Para más información, consulte cómo crear una tabla externa mediante el asistente para la interfaz de usuario web de Azure Data Explorer. Para obtener información general breve, consulte tablas externas.
Sugerencia
Para obtener el mejor rendimiento de consultas, se necesita la ingesta de datos en Azure Data Explorer. Una consulta de datos externos sin ingesta previa solo se debe realizar para datos históricos o datos que se consultan con poca frecuencia. Optimice el rendimiento de las consultas para obtener los mejores resultados.
Crear una tabla externa
Supongamos que tiene muchos archivos CSV con información histórica sobre los productos almacenados en un almacén y desea realizar un análisis rápido para encontrar los cinco productos más populares del año anterior. En este ejemplo, los archivos CSV tienen el siguiente aspecto:
| Timestamp | ProductId | ProductDescription |
|---|---|---|
| 2019-01-01 11:21:00 | TO6050 | Disquete DS/HD de 3,5 pulgadas |
| 2019-01-01 11:30:55 | YDX1 | Sintetizador Yamaha DX1 |
| ... | ... | ... |
Los archivos están almacenados en Azure Blob Storage, en mycompanystorage, dentro de un contenedor llamado archivedproducts, con particiones por fecha:
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/01/part-00000-7e967c99-cf2b-4dbb-8c53-ce388389470d.csv.gz
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/01/part-00001-ba356fa4-f85f-430a-8b5a-afd64f128ca4.csv.gz
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/01/part-00002-acb644dc-2fc6-467c-ab80-d1590b23fc31.csv.gz
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/01/part-00003-cd5fad16-a45e-4f8c-a2d0-5ea5de2f4e02.csv.gz
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/02/part-00000-ffc72d50-ff98-423c-913b-75482ba9ec86.csv.gz
...
Para ejecutar una consulta KQL en estos archivos CSV directamente, utilice el comando .create external table para definir una tabla externa en Azure Data Explorer. Para más información sobre la creación de una tabla externa con opciones de comando, consulte el artículo sobre la creación y modificación de tablas externas.
.create external table ArchivedProducts(Timestamp:datetime, ProductId:string, ProductDescription:string)
kind=blob
partition by (Date:datetime = bin(Timestamp, 1d))
dataformat=csv
(
h@'https://mycompanystorage.blob.core.windows.net/archivedproducts;StorageSecretKey'
)
La tabla externa está visible en el panel izquierdo de la interfaz de usuario web de Azure Data Explorer:
Permisos de tabla externa
- El usuario de la base de datos puede crear una tabla externa. El creador de la tabla se convierte automáticamente en el administrador de la tabla.
- El administrador del clúster, la base de datos o la tabla puede editar una tabla existente.
- Cualquier usuario o lector de la base de datos puede consultar una tabla externa.
Consulta de una tabla externa
Una vez definida una tabla externa, se puede usar la función external_table() para hacer referencia a ella. El resto de la consulta está en lenguaje de consulta Kusto estándar.
external_table("ArchivedProducts")
| where Timestamp > ago(365d)
| summarize Count=count() by ProductId,
| top 5 by Count
Consulta conjunta de datos externos e ingeridos
Puede usar la misma consulta para consultar tablas externas y tablas de datos ingeridos. Puede utilizar los operadores join o union en la tabla externa con otros datos procedentes de Azure Data Explorer, servidores de SQL Server u otros orígenes. Use una instrucción de tipo let( ) statement para asignar un nombre abreviado a una referencia de tabla externa.
En el ejemplo siguiente, Products es una tabla de datos ingeridos y ArchivedProducts es una tabla externa que hemos definido previamente:
let T1 = external_table("ArchivedProducts") | where TimeStamp > ago(100d);
let T = Products; //T is an internal table
T1 | join T on ProductId | take 10
Consulta de formatos de datos jerárquicos
Azure Data Explorer permite consultar formatos de datos jerárquicos, como JSON, Parquet, Avro y ORC. Para asignar un esquema de datos jerárquico a un esquema de tabla externa (en el caso de que sea diferente), utilice comandos de asignación de tablas externas. Por ejemplo, si desea hacer consultas en archivos de registro JSON con el siguiente formato:
{
"timestamp": "2019-01-01 10:00:00.238521",
"data": {
"tenant": "e1ef54a6-c6f2-4389-836e-d289b37bcfe0",
"method": "RefreshTableMetadata"
}
}
{
"timestamp": "2019-01-01 10:00:01.845423",
"data": {
"tenant": "9b49d0d7-b3e6-4467-bb35-fa420a25d324",
"method": "GetFileList"
}
}
...
La definición de tabla externa tiene el siguiente aspecto:
.create external table ApiCalls(Timestamp: datetime, TenantId: guid, MethodName: string)
kind=blob
dataformat=multijson
(
h@'https://storageaccount.blob.core.windows.net/container1;StorageSecretKey'
)
Defina una asignación JSON que asigne campos de datos a campos de definición de tabla externa:
.create external table ApiCalls json mapping 'MyMapping' '[{"Column":"Timestamp","Properties":{"Path":"$.timestamp"}},{"Column":"TenantId","Properties":{"Path":"$.data.tenant"}},{"Column":"MethodName","Properties":{"Path":"$.data.method"}}]'
Al consultar la tabla externa, se invocará la asignación y se asignarán los datos pertinentes a las columnas de la tabla externa:
external_table('ApiCalls') | take 10
Para más información sobre la sintaxis de asignación, consulte asignaciones de datos.
Consulta de la tabla externa TaxiRides en el clúster de ayuda
Utilice el clúster de prueba llamado help para probar diferentes funciones de Azure Data Explorer. El clúster help contiene una definición de tabla externa para un conjunto de datos vinculado a los taxis de la ciudad de Nueva York, que contiene miles de millones de carreras de taxi.
Creación de la tabla externa TaxiRides
Esta sección muestra la consulta utilizada para crear la tabla externa TaxiRides en el clúster help. Puesto que la tabla ya se ha creado, puede omitir esta sección y realizar la consulta en los datos de la tabla externaTaxiRides.
.create external table TaxiRides
(
trip_id: long,
vendor_id: string,
pickup_datetime: datetime,
dropoff_datetime: datetime,
store_and_fwd_flag: string,
rate_code_id: int,
pickup_longitude: real,
pickup_latitude: real,
dropoff_longitude: real,
dropoff_latitude: real,
passenger_count: int,
trip_distance: real,
fare_amount: real,
extra: real,
mta_tax: real,
tip_amount: real,
tolls_amount: real,
ehail_fee: real,
improvement_surcharge: real,
total_amount: real,
payment_type: string,
trip_type: int,
pickup: string,
dropoff: string,
cab_type: string,
precipitation: int,
snow_depth: int,
snowfall: int,
max_temperature: int,
min_temperature: int,
average_wind_speed: int,
pickup_nyct2010_gid: int,
pickup_ctlabel: string,
pickup_borocode: int,
pickup_boroname: string,
pickup_ct2010: string,
pickup_boroct2010: string,
pickup_cdeligibil: string,
pickup_ntacode: string,
pickup_ntaname: string,
pickup_puma: string,
dropoff_nyct2010_gid: int,
dropoff_ctlabel: string,
dropoff_borocode: int,
dropoff_boroname: string,
dropoff_ct2010: string,
dropoff_boroct2010: string,
dropoff_cdeligibil: string,
dropoff_ntacode: string,
dropoff_ntaname: string,
dropoff_puma: string
)
kind=blob
partition by (Date:datetime = bin(pickup_datetime, 1d))
dataformat=csv
(
h@'https://storageaccount.blob.core.windows.net/container1;secretKey'
)
La tabla TaxiRides que se ha creado está disponible en el panel izquierdo de la interfaz de usuario web de Azure Data Explorer:
Consulta de los datos de la tabla externa TaxiRides
Inicie sesión en https://dataexplorer.azure.com/clusters/help/databases/Samples.
Consulta de la tabla externa TaxiRides sin particiones
Ejecute esta consulta en la tabla externa TaxiRides para mostrar carreras para cada día de la semana, en todo el conjunto de datos.
external_table("TaxiRides")
| summarize count() by dayofweek(pickup_datetime)
| render columnchart
Esta consulta muestra el día más ajetreado de la semana. Dado que no se han creado particiones de los datos, la consulta puede tardar varios minutos en devolver resultados.
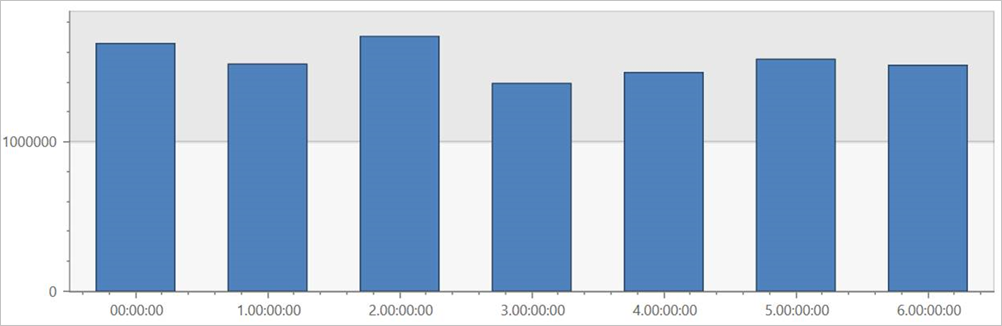
Consulta de la tabla externa TaxiRides con particiones
Ejecute esta consulta en la tabla externa TaxiRides para mostrar los tipos de taxis (amarillos o verdes) que se usaron en enero de 2017.
external_table("TaxiRides")
| where pickup_datetime between (datetime(2017-01-01) .. datetime(2017-02-01))
| summarize count() by cab_type
| render piechart
Esta consulta usa particiones, lo que optimiza el rendimiento y el tiempo de consulta. La consulta filtra en función de una columna con particiones (pickup_datetime) y devuelve los resultados en pocos segundos.
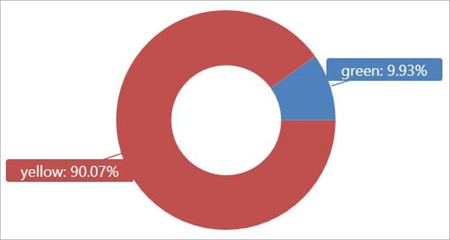
Puede escribir otras consultas para ejecutarlas en la tabla externa TaxiRides y obtener más información sobre los datos.
Optimización del rendimiento de las consultas
Optimice el rendimiento de las consultas en el lago mediante los siguientes procedimientos recomendados para consultar datos externos.
Formato de datos
- Utilice el formato de columnas para consultas analíticas por los motivos siguientes:
- Solo se pueden leer las columnas pertinentes para una consulta.
- Las técnicas de codificación de columnas pueden reducir considerablemente el tamaño de los datos.
- Azure Data Explorer admite los formatos de columna Parquet y ORC. Se sugiere utilizar el formato Parquet debido a la implementación optimizada.
Región de Azure
Compruebe que los datos externos se encuentran en la misma región de Azure que el clúster de Azure Data Explorer. Esta configuración reduce el costo y el tiempo de captura de datos.
Tamaño de archivo
El tamaño óptimo de archivo es de cientos de MB (hasta 1 GB) por archivo. Evite muchos archivos pequeños que requieran una sobrecarga innecesaria, como un proceso de enumeración de archivos más lento y el uso limitado del formato de las columnas. El número de archivos debe ser mayor que el número de núcleos de CPU del clúster de Azure Data Explorer.
Compresión
Use la compresión para reducir la cantidad de datos que se capturan desde el almacenamiento remoto. Para el formato Parquet, utilice el mecanismo interno de compresión de Parquet, que comprime grupos de columnas por separado y también permite leerlos por separado. Para validar el uso del mecanismo de compresión, compruebe que los archivos tienen la nomenclatura <filename>.gz.parquet o <filename>.snappy.parquet, y no <filename>.parquet.gz.
Creación de particiones
Organice los datos con particiones de "carpeta" para que la consulta omita las rutas de acceso irrelevantes. Al planear la creación de particiones, tenga en cuenta el tamaño de archivo y los filtros comunes en las consultas, como la marca de tiempo o el identificador de inquilino.
Tamaño de VM
Seleccione las SKU de máquinas virtuales con más núcleos y mayor rendimiento de la red (la memoria es menos importante). Para más información, consulte Selección de la SKU de máquina virtual correcta para el clúster de Azure Data Explorer.
Contenido relacionado
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de