Diagnóstico de anomalías para el análisis de la causa principal
Lenguaje de consulta Kusto (KQL) tiene funciones integradas de detección y previsión de anomalías para comprobar el comportamiento anómalo. Una vez detectado este patrón, se puede ejecutar un análisis de causa principal (RCA) para mitigar o resolver la anomalía.
El proceso de diagnóstico es largo y complejo, y lo realizan expertos en la materia. Este proceso incluye:
- Captura y combinación de más datos de orígenes diferentes para el mismo período de tiempo
- Buscar cambios en la distribución de valores en varias dimensiones.
- Gráficos de más variables
- Aplicar otras técnicas basadas en la intuición y el conocimiento del área.
Dado que estos escenarios de diagnóstico son comunes, los complementos de aprendizaje automático están disponibles para facilitar la fase de diagnóstico y acortar la duración del RCA.
Los tres complementos de Machine Learning siguientes implementan algoritmos de agrupación en clústeres: autocluster, baskety diffpatterns. Los complementos autocluster y basket agrupan en clústeres un conjunto único de registros, mientras que el complemento diffpatterns agrupa en clústeres las diferencias entre dos conjuntos de registros.
Agrupación en clústeres de un conjunto de registros único
Un escenario común incluye un conjunto de datos seleccionado por un criterio específico, como:
- Período de tiempo que señala un comportamiento anómalo.
- Lecturas de dispositivos que señalan una alta temperatura.
- Comandos de larga duración.
- Usuarios con gastos más elevados. Necesita una manera rápida y sencilla de identificar patrones comunes (segmentos) en los datos. Los patrones son un subconjunto del conjunto de datos cuyos registros comparten los mismos valores en varias dimensiones (columnas de categorías).
La consulta siguiente genera y muestra una serie temporal de excepciones de servicio generadas durante una semana, en rangos de diez minutos:
let min_t = toscalar(demo_clustering1 | summarize min(PreciseTimeStamp));
let max_t = toscalar(demo_clustering1 | summarize max(PreciseTimeStamp));
demo_clustering1
| make-series num=count() on PreciseTimeStamp from min_t to max_t step 10m
| render timechart with(title="Service exceptions over a week, 10 minutes resolution")
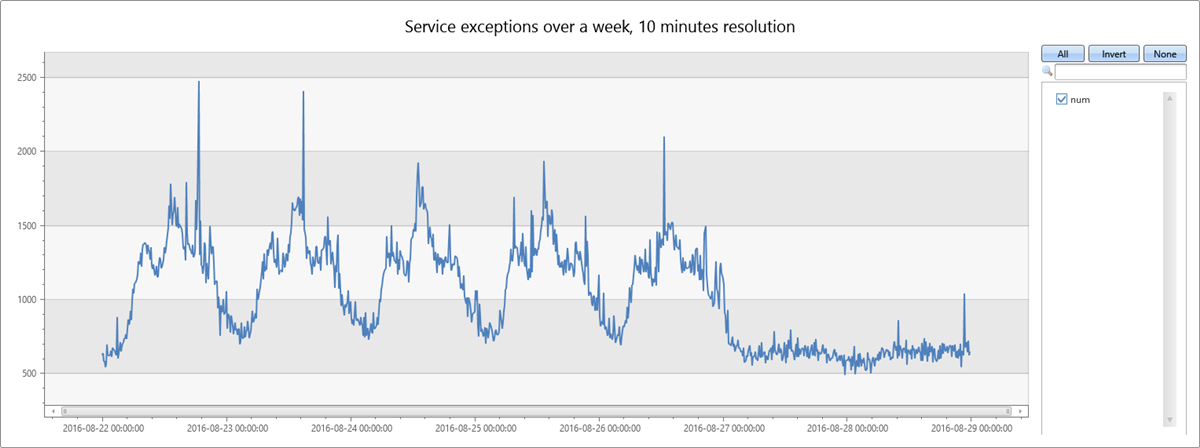
El recuento de excepciones de servicio se correlaciona con el tráfico del servicio total. Puede ver claramente el patrón diario en relación con los días laborables, de lunes a viernes. Hay un aumento en el número de excepciones de servicio en la franja del mediodía, y una caída en el número de excepciones por la noche. A lo largo del fin de semana, pueden verse recuentos bajos planos. Se pueden detectar picos de excepción mediante la detección de anomalías de series temporales.
El segundo pico en los datos se produce el martes por la tarde. La consulta siguiente se utiliza para diagnosticar mejor y comprobar si se trata de un pico pronunciado. La consulta vuelve a recrear el gráfico en torno al pico, con una resolución mayor, y durante un período de ocho horas en rangos de un minuto. Después, se pueden analizar los bordes.
let min_t=datetime(2016-08-23 11:00);
demo_clustering1
| make-series num=count() on PreciseTimeStamp from min_t to min_t+8h step 1m
| render timechart with(title="Zoom on the 2nd spike, 1 minute resolution")

Verá un pico estrecho de dos minutos de 15:00 a 15:02. En la consulta siguiente, cuente las excepciones en esta ventana de dos minutos:
let min_peak_t=datetime(2016-08-23 15:00);
let max_peak_t=datetime(2016-08-23 15:02);
demo_clustering1
| where PreciseTimeStamp between(min_peak_t..max_peak_t)
| count
| Count |
|---|
| 972 |
En la consulta siguiente, muestree 20 excepciones de un total de 972:
let min_peak_t=datetime(2016-08-23 15:00);
let max_peak_t=datetime(2016-08-23 15:02);
demo_clustering1
| where PreciseTimeStamp between(min_peak_t..max_peak_t)
| take 20
| PreciseTimeStamp | Region | ScaleUnit | DeploymentId | Tracepoint | ServiceHost |
|---|---|---|---|---|---|
| 2016-08-23 15:00:08.7302460 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 100005 | 00000000-0000-0000-0000-000000000000 |
| 2016-08-23 15:00:09.9496584 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 10007006 | 8d257da1-7a1c-44f5-9acd-f9e02ff507fd |
| 2016-08-23 15:00:10.5911748 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 100005 | 00000000-0000-0000-0000-000000000000 |
| 2016-08-23 15:00:12.2957912 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 10007007 | f855fcef-ebfe-405d-aaf8-9c5e2e43d862 |
| 2016-08-23 15:00:18.5955357 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 10007006 | 9d390e07-417d-42eb-bebd-793965189a28 |
| 2016-08-23 15:00:20.7444854 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 10007006 | 6e54c1c8-42d3-4e4e-8b79-9bb076ca71f1 |
| 2016-08-23 15:00:23.8694999 | eus2 | su2 | 89e2f62a73bb4efd8f545aeae40d7e51 | 36109 | 19422243-19b9-4d85-9ca6-bc961861d287 |
| 2016-08-23 15:00:26.4271786 | ncus | su1 | e24ef436e02b4823ac5d5b1465a9401e | 36109 | 3271bae4-1c5b-4f73-98ef-cc117e9be914 |
| 2016-08-23 15:00:27.8958124 | scus | su3 | 90d3d2fc7ecc430c9621ece335651a01 | 904498 | 8cf38575-fca9-48ca-bd7c-21196f6d6765 |
| 2016-08-23 15:00:32.9884969 | scus | su3 | 90d3d2fc7ecc430c9621ece335651a01 | 10007007 | d5c7c825-9d46-4ab7-a0c1-8e2ac1d83ddb |
| 2016-08-23 15:00:34.5061623 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 1002110 | 55a71811-5ec4-497a-a058-140fb0d611ad |
| 2016-08-23 15:00:37.4490273 | scus | su3 | 90d3d2fc7ecc430c9621ece335651a01 | 10007006 | f2ee8254-173c-477d-a1de-4902150ea50d |
| 2016-08-23 15:00:41.2431223 | scus | su3 | 90d3d2fc7ecc430c9621ece335651a01 | 103200 | 8cf38575-fca9-48ca-bd7c-21196f6d6765 |
| 2016-08-23 15:00:47.2983975 | ncus | su1 | e24ef436e02b4823ac5d5b1465a9401e | 423690590 | 00000000-0000-0000-0000-000000000000 |
| 2016-08-23 15:00:50.5932834 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 10007006 | 2a41b552-aa19-4987-8cdd-410a3af016ac |
| 2016-08-23 15:00:50.8259021 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 1002110 | 0d56b8e3-470d-4213-91da-97405f8d005e |
| 2016-08-23 15:00:53.2490731 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 36109 | 55a71811-5ec4-497a-a058-140fb0d611ad |
| 2016-08-23 15:00:57.0000946 | eus2 | su2 | 89e2f62a73bb4efd8f545aeae40d7e51 | 64038 | cb55739e-4afe-46a3-970f-1b49d8ee7564 |
| 2016-08-23 15:00:58.2222707 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 10007007 | 8215dcf6-2de0-42bd-9c90-181c70486c9c |
| 2016-08-23 15:00:59.9382620 | scus | su3 | 90d3d2fc7ecc430c9621ece335651a01 | 10007006 | 451e3c4c-0808-4566-a64d-84d85cf30978 |
Usar un autoclúster para la agrupación en clústeres de un conjunto de registros único
Aunque hay menos de mil excepciones, es difícil encontrar segmentos comunes, ya que cada columna tiene múltiples valores. Puede usar el complemento autocluster() para extraer inmediatamente una pequeña lista de segmentos comunes e identificar los clústeres relevantes en los dos minutos del pico, tal como se muestra en la consulta siguiente:
let min_peak_t=datetime(2016-08-23 15:00);
let max_peak_t=datetime(2016-08-23 15:02);
demo_clustering1
| where PreciseTimeStamp between(min_peak_t..max_peak_t)
| evaluate autocluster()
| SegmentId | Count | Percent | Region | ScaleUnit | DeploymentId | ServiceHost |
|---|---|---|---|---|---|---|
| 0 | 639 | 65.7407407407407 | eau | su7 | b5d1d4df547d4a04ac15885617edba57 | e7f60c5d-4944-42b3-922a-92e98a8e7dec |
| 1 | 94 | 9.67078189300411 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | |
| 2 | 82 | 8.43621399176955 | ncus | su1 | e24ef436e02b4823ac5d5b1465a9401e | |
| 3 | 68 | 6.99588477366255 | scus | su3 | 90d3d2fc7ecc430c9621ece335651a01 | |
| 4 | 55 | 5.65843621399177 | weu | su4 | be1d6d7ac9574cbc9a22cb8ee20f16fc |
En los resultados anteriores, se puede ver que el segmento predominante contiene el 65,74 % del total de registros de excepciones y comparte cuatro dimensiones. El siguiente segmento es mucho menos frecuente. Solo contiene el 9,67 % de los registros y comparte tres dimensiones. Los demás segmentos son incluso menos comunes.
Un autoclúster utiliza un algoritmo patentado para crear minería de datos de varias dimensiones y extraer segmentos interesantes. "Interesante" significa que cada segmento tiene una cobertura significativa de los conjuntos de registros y de características. Los segmentos también difieren, lo que significa que cada uno de ellos es diferente de los demás. Uno o varios de estos segmentos pueden ser relevantes para el proceso de RCA. Para minimizar la evaluación y revisión de los segmentos, el autoclúster extrae solo una lista de segmentos pequeños.
Uso de basket() para la agrupación en clústeres de un conjunto de registros único
También puede usar el complemento basket() tal como se muestra en la consulta siguiente:
let min_peak_t=datetime(2016-08-23 15:00);
let max_peak_t=datetime(2016-08-23 15:02);
demo_clustering1
| where PreciseTimeStamp between(min_peak_t..max_peak_t)
| evaluate basket()
| SegmentId | Count | Percent | Region | ScaleUnit | DeploymentId | Tracepoint | ServiceHost |
|---|---|---|---|---|---|---|---|
| 0 | 639 | 65.7407407407407 | eau | su7 | b5d1d4df547d4a04ac15885617edba57 | e7f60c5d-4944-42b3-922a-92e98a8e7dec | |
| 1 | 642 | 66.0493827160494 | eau | su7 | b5d1d4df547d4a04ac15885617edba57 | ||
| 2 | 324 | 33.3333333333333 | eau | su7 | b5d1d4df547d4a04ac15885617edba57 | 0 | e7f60c5d-4944-42b3-922a-92e98a8e7dec |
| 3 | 315 | 32.4074074074074 | eau | su7 | b5d1d4df547d4a04ac15885617edba57 | 16108 | e7f60c5d-4944-42b3-922a-92e98a8e7dec |
| 4 | 328 | 33.7448559670782 | 0 | ||||
| 5 | 94 | 9.67078189300411 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | ||
| 6 | 82 | 8.43621399176955 | ncus | su1 | e24ef436e02b4823ac5d5b1465a9401e | ||
| 7 | 68 | 6.99588477366255 | scus | su3 | 90d3d2fc7ecc430c9621ece335651a01 | ||
| 8 | 167 | 17.1810699588477 | scus | ||||
| 9 | 55 | 5.65843621399177 | weu | su4 | be1d6d7ac9574cbc9a22cb8ee20f16fc | ||
| 10 | 92 | 9.46502057613169 | 10007007 | ||||
| 11 | 90 | 9.25925925925926 | 10007006 | ||||
| 12 | 57 | 5.8641975308642 | 00000000-0000-0000-0000-000000000000 |
Basket implementa el algoritmo Apriori en relación con la minería del conjunto de elementos. Extrae todos los segmentos para los que la cobertura del conjunto de registros supera un umbral (el valor predeterminado es 5 %). Se puede ver que se han extraído más segmentos con valores similares (por ejemplo, los segmentos 0, 1 o 2, 3).
Ambos complementos son eficaces y fáciles de usar. La limitación que tienen es que agrupan en clústeres un conjunto único de registros, sin supervisión y sin etiquetas. Por tanto, no está claro si los patrones extraídos caracterizan al conjunto de registros seleccionado (registros anómalos) o al conjunto de registros global.
Agrupación en clústeres de la diferencia entre dos conjuntos de registros
Con el complemento diffpatterns() se supera la limitación de autocluster y basket. Diffpatterns toma dos conjuntos de registros y extrae los principales segmentos que difieren. Por lo general, un conjunto contiene los registros anómalos que se están investigando. autocluster y basket analizan uno de los conjuntos. El otro conjunto contiene los registros de referencia (base de referencia).
En la consulta siguiente, diffpatterns busca clústeres interesantes dentro de los dos minutos del pico, que son diferentes de los clústeres de la línea base. La ventana de la base de referencia son los ocho minutos anteriores a las 15:00, hora en la que se inició el pico. Amplíe una columna binaria (AB) y especifique si un registro específico pertenece a la base de referencia o al conjunto anómalo. Diffpatterns implementa un algoritmo de aprendizaje supervisado, en que la marca anómala, frente a la marca de la base de referencia (AB), ha generado las dos etiquetas de clase.
let min_peak_t=datetime(2016-08-23 15:00);
let max_peak_t=datetime(2016-08-23 15:02);
let min_baseline_t=datetime(2016-08-23 14:50);
let max_baseline_t=datetime(2016-08-23 14:58); // Leave a gap between the baseline and the spike to avoid the transition zone.
let splitime=(max_baseline_t+min_peak_t)/2.0;
demo_clustering1
| where (PreciseTimeStamp between(min_baseline_t..max_baseline_t)) or
(PreciseTimeStamp between(min_peak_t..max_peak_t))
| extend AB=iff(PreciseTimeStamp > splitime, 'Anomaly', 'Baseline')
| evaluate diffpatterns(AB, 'Anomaly', 'Baseline')
| SegmentId | CountA | CountB | PercentA | PercentB | PercentDiffAB | Region | ScaleUnit | DeploymentId | Tracepoint |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 639 | 21 | 65.74 | 1.7 | 64.04 | eau | su7 | b5d1d4df547d4a04ac15885617edba57 | |
| 1 | 167 | 544 | 17.18 | 44.16 | 26.97 | scus | |||
| 2 | 92 | 356 | 9.47 | 28,9 | 19.43 | 10007007 | |||
| 3 | 90 | 336 | 9,26 | 27.27 | 18.01 | 10007006 | |||
| 4 | 82 | 318 | 8.44 | 25.81 | 17.38 | ncus | su1 | e24ef436e02b4823ac5d5b1465a9401e | |
| 5 | 55 | 252 | 5.66 | 20.45 | 14.8 | weu | su4 | be1d6d7ac9574cbc9a22cb8ee20f16fc | |
| 6 | 57 | 204 | 5.86 | 16.56 | 10.69 |
El segmento dominante es el mismo que se extrajo mediante autocluster. La cobertura en la ventana anómala de dos minutos también es del 65,74 %. Sin embargo, la cobertura en la ventana de la base de referencia de ocho minutos solo es del 1,7 %. La diferencia es del 64,04 %. Esta diferencia parece estar relacionada con el pico anómalo. Para comprobar esta suposición, la consulta siguiente divide el gráfico original en los registros que pertenecen a este segmento problemático y los registros de los demás segmentos.
let min_t = toscalar(demo_clustering1 | summarize min(PreciseTimeStamp));
let max_t = toscalar(demo_clustering1 | summarize max(PreciseTimeStamp));
demo_clustering1
| extend seg = iff(Region == "eau" and ScaleUnit == "su7" and DeploymentId == "b5d1d4df547d4a04ac15885617edba57"
and ServiceHost == "e7f60c5d-4944-42b3-922a-92e98a8e7dec", "Problem", "Normal")
| make-series num=count() on PreciseTimeStamp from min_t to max_t step 10m by seg
| render timechart

Este gráfico nos permite ver que el pico del martes por la tarde se ha debido a las excepciones de este segmento específico, detectadas mediante el complemento diffpatterns.
Resumen
Los complementos de Machine Learning son útiles para muchos escenarios. autocluster y basket implementan un algoritmo de aprendizaje no supervisado y son fáciles de usar. Diffpatterns implementa un algoritmo de aprendizaje supervisado y, aunque es más complejo, también es más eficaz para extraer los segmentos de diferenciación de cara al análisis RCA.
Estos complementos se utilizan interactivamente en situaciones ad hoc y en servicios de supervisión casi en tiempo real automáticos. La detección de anomalías de series temporales va seguida de un proceso de diagnóstico. El proceso está muy optimizado con el fin de satisfacer los estándares de rendimiento necesarios.
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de