¿Qué es ML.NET y cómo funciona?
ML.NET ofrece la posibilidad de agregar aprendizaje automático en aplicaciones de .NET, ya sea en escenarios en línea o sin conexión. Con esta funcionalidad, puede realizar predicciones automáticas con los datos disponibles para su aplicación. Las aplicaciones de aprendizaje automático usan los patrones en los datos para realizar predicciones en lugar de tener que programarse de manera explícita.
La base de ML.NET es un modelo de aprendizaje automático. El modelo especifica los pasos necesarios para transformar los datos de entrada en una predicción. Con ML.NET, puede entrenar un modelo personalizado mediante la especificación de un algoritmo, o bien puede importar modelos TensorFlow y ONNX previamente entrenados.
Una vez que tiene un modelo, puede agregarlo a la aplicación para realizar las predicciones.
ML.NET se ejecuta en Windows, Linux y macOS con .NET o en Windows mediante .NET Framework. La versión de 64 bits es compatible con todas las plataformas. La versión de 32 bits es compatible con Windows, salvo para la funcionalidad relacionada con TensorFlow, LightGBM y ONNX.
En la tabla siguiente se muestran algunos ejemplos del tipo de predicciones que puede hacer con ML.NET.
| Tipo de predicción | Ejemplo |
|---|---|
| Clasificación o categorización | Clasifique automáticamente los comentarios del cliente en positivos y negativos. |
| Regresión o predicción de valores continuos | Prediga el precio de la vivienda según el tamaño y la ubicación. |
| Detección de anomalías | Detecte transacciones bancarias fraudulentas. |
| Recomendaciones | Sugiera productos que los compradores en línea pueden comprar, en función de sus compras anteriores. |
| Series temporales y datos secuenciales | Haga una previsión del tiempo o de las ventas de productos. |
| Clasificación de imágenes | Clasifique las patologías en imágenes médicas. |
| Clasificación de textos | Clasifique los documentos en función de su contenido. |
| Similitud de oraciones | Mide la similitud de dos oraciones. |
Hello ML.NET World
El código en el siguiente fragmento muestra la aplicación de ML.NET más sencilla. En este ejemplo se crea un modelo de regresión lineal para predecir los precios de la vivienda con información sobre el tamaño y el precio de la vivienda.
using System;
using Microsoft.ML;
using Microsoft.ML.Data;
class Program
{
public class HouseData
{
public float Size { get; set; }
public float Price { get; set; }
}
public class Prediction
{
[ColumnName("Score")]
public float Price { get; set; }
}
static void Main(string[] args)
{
MLContext mlContext = new MLContext();
// 1. Import or create training data
HouseData[] houseData = {
new HouseData() { Size = 1.1F, Price = 1.2F },
new HouseData() { Size = 1.9F, Price = 2.3F },
new HouseData() { Size = 2.8F, Price = 3.0F },
new HouseData() { Size = 3.4F, Price = 3.7F } };
IDataView trainingData = mlContext.Data.LoadFromEnumerable(houseData);
// 2. Specify data preparation and model training pipeline
var pipeline = mlContext.Transforms.Concatenate("Features", new[] { "Size" })
.Append(mlContext.Regression.Trainers.Sdca(labelColumnName: "Price", maximumNumberOfIterations: 100));
// 3. Train model
var model = pipeline.Fit(trainingData);
// 4. Make a prediction
var size = new HouseData() { Size = 2.5F };
var price = mlContext.Model.CreatePredictionEngine<HouseData, Prediction>(model).Predict(size);
Console.WriteLine($"Predicted price for size: {size.Size*1000} sq ft= {price.Price*100:C}k");
// Predicted price for size: 2500 sq ft= $261.98k
}
}
Flujo de trabajo del código
El siguiente diagrama representa la estructura del código de aplicación, así como el proceso iterativo de desarrollo de modelos:
- Recopilar y cargar datos de entrenamiento en un objeto IDataView
- Especificar una canalización de operaciones para extraer características y aplicar un algoritmo de aprendizaje automático
- Entrenar un modelo mediante una llamada a Fit() en la canalización
- Evaluar el modelo e iterar para mejorar
- Guardar el modelo en formato binario, para su uso en una aplicación
- Cargar el modelo en un objeto ITransformer
- Realizar predicciones mediante una llamada a CreatePredictionEngine.Predict()
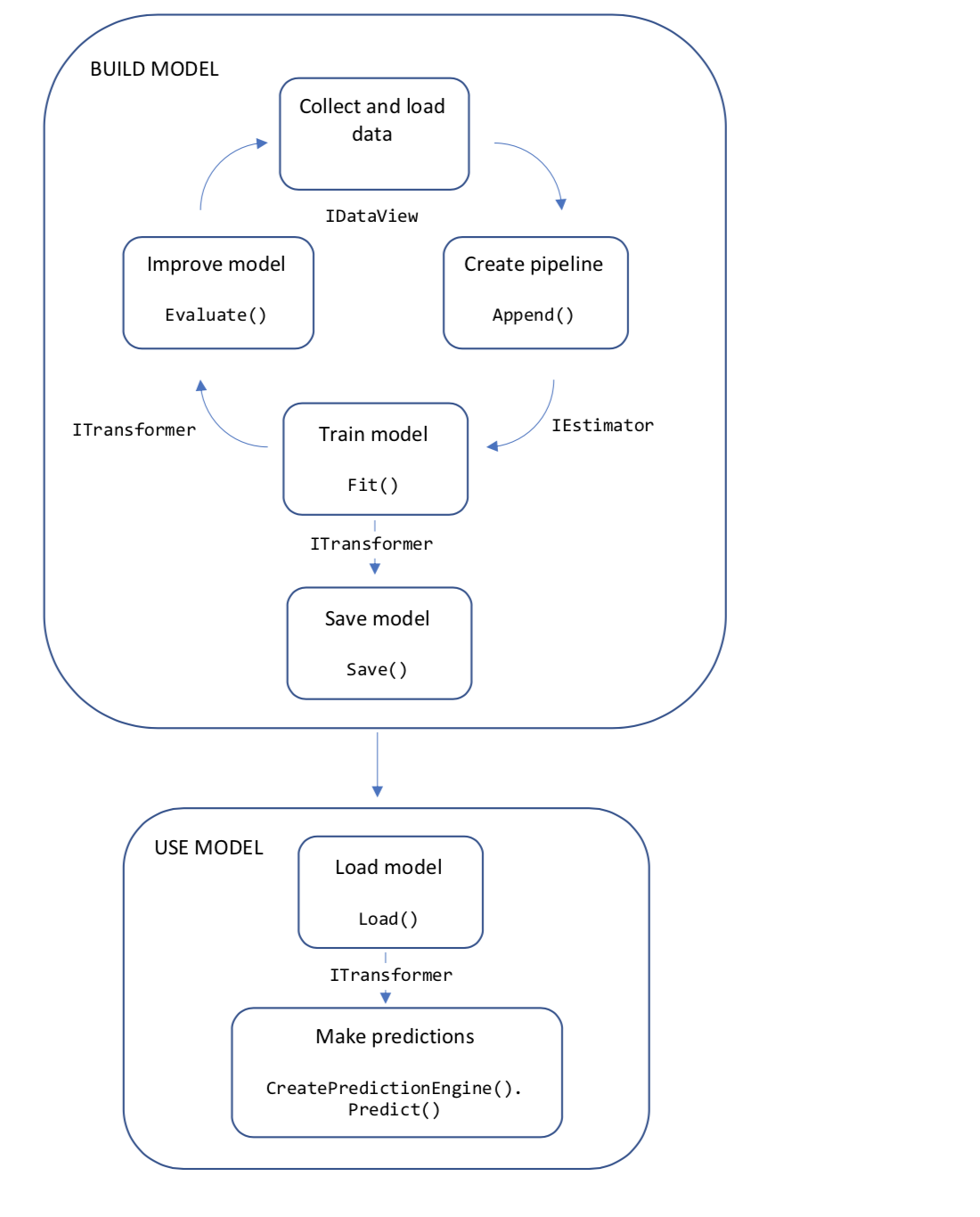
Vamos a profundizar un poco más en estos conceptos.
Modelo de Machine Learning
Un modelo de ML.NET es un objeto que contiene las transformaciones que se realizarán en los datos de entrada para llegar a los resultados previstos.
Básico
El modelo más básico es una regresión lineal bidimensional, donde una cantidad continua es proporcional a otra, como se muestra en el ejemplo anterior del precio de la vivienda.

El modelo es simplemente: $Precio = b + Tamaño * w$. Los parámetros $b$ y $w$ se calculan ajustando una línea en un conjunto de pares (tamaño, precio). Los datos que se usan para buscar los parámetros del modelo se denominan datos de aprendizaje. Las entradas de un modelo de Machine Learning se denominan características. En este ejemplo, $Tamaño$ es la única característica. Los valores de datos reales en el terreno que se usan para entrenar un modelo de Machine Learning se denominan etiquetas. En este caso, los valores de $Precio$ en el conjunto de datos de entrenamiento son las etiquetas.
Más complejo
Un modelo más complejo clasifica las transacciones financieras en categorías utilizando la descripción de texto de la transacción.
La descripción de cada transacción se divide en un conjunto de características quitando palabras y caracteres redundantes, y contando combinaciones de palabras y caracteres. El conjunto de características se utiliza para entrenar un modelo lineal según el conjunto de categorías en los datos de aprendizaje. Cuanto más similar es una nueva descripción a las del conjunto de entrenamiento, más probabilidades tiene de que se le asigne la misma categoría.

Tanto el modelo de precios de vivienda como el modelo de clasificación de textos son modelos lineales. Según la naturaleza de los datos y el problema que se va a resolver, también puede usar modelos de árbol de decisión y modelos aditivos generalizados, entre otros. Para obtener más información sobre los modelos, vea Tareas.
Preparación de datos
En la mayoría de los casos, los datos que tiene a su disposición no son aptos para usarse directamente en el entrenamiento de un modelo de Machine Learning. Los datos sin procesar deben prepararse o procesarse previamente antes de que se puedan usar para buscar los parámetros del modelo. Es posible que los datos deban convertirse de valores de cadena a una representación numérica. Puede que tenga información redundante en los datos de entrada. Tal vez necesite reducir o expandir las dimensiones de los datos de entrada. Puede que los datos deban normalizarse o escalarse.
Los tutoriales de ML.NET le proporcionan información sobre las diferentes canalizaciones de procesamiento de datos para texto, imágenes, datos numéricos y de series temporales que se usan en tareas específicas de aprendizaje automático.
Cómo preparar los datos le explica cómo aplicar la preparación de datos de manera más general.
Encontrará un apéndice de todas las transformaciones disponibles en la sección de recursos.
Evaluación de modelo
Una vez que ha entrenado el modelo, ¿cómo sabe hasta qué punto realizará predicciones futuras? Con ML.NET, puede evaluar su modelo con algunos datos de prueba nuevos.
Cada tipo de tarea de aprendizaje automático tiene métricas que se usan para evaluar la precisión y exactitud del modelo en el conjunto de datos de prueba.
En nuestro ejemplo de precios de vivienda, hemos usado la tarea Regresión. Para evaluar el modelo, agregue el código siguiente en el ejemplo original.
HouseData[] testHouseData =
{
new HouseData() { Size = 1.1F, Price = 0.98F },
new HouseData() { Size = 1.9F, Price = 2.1F },
new HouseData() { Size = 2.8F, Price = 2.9F },
new HouseData() { Size = 3.4F, Price = 3.6F }
};
var testHouseDataView = mlContext.Data.LoadFromEnumerable(testHouseData);
var testPriceDataView = model.Transform(testHouseDataView);
var metrics = mlContext.Regression.Evaluate(testPriceDataView, labelColumnName: "Price");
Console.WriteLine($"R^2: {metrics.RSquared:0.##}");
Console.WriteLine($"RMS error: {metrics.RootMeanSquaredError:0.##}");
// R^2: 0.96
// RMS error: 0.19
Las métricas de evaluación indican que el error es bastante bajo y que la correlación entre la salida de predicción y la salida de prueba es alta. ¡Qué sencillo! En los ejemplos reales, se necesitan más ajustes para lograr las métricas del modelo adecuado.
Arquitectura de ML.NET
En esta sección se describen los patrones arquitectónicos de ML.NET. Si es un desarrollador experimentado de .NET, algunos de estos patrones le resultarán familiares y otros serán menos conocidos.
Una aplicación de ML.NET se inicia con un objeto MLContext. Este objeto singleton contiene catálogos. Un catálogo es una fábrica para cargar y guardar datos, transformaciones, instructores y componentes de la operación de modelos. Cada objeto de catálogo tiene métodos para crear los diferentes tipos de componentes.
| Tarea | Catálogo |
|---|---|
| Carga y guardado de datos | DataOperationsCatalog |
| Preparación de datos | TransformsCatalog |
| Clasificación binaria | BinaryClassificationCatalog |
| Clasificación multiclase | MulticlassClassificationCatalog |
| Detección de anomalías | AnomalyDetectionCatalog |
| Agrupación en clústeres | ClusteringCatalog |
| Previsión | ForecastingCatalog |
| Clasificación | RankingCatalog |
| Regresión | RegressionCatalog |
| Recomendación | RecommendationCatalog |
| Serie temporal | TimeSeriesCatalog |
| Uso del modelo | ModelOperationsCatalog |
Puede navegar a los métodos de creación en cada una de las categorías anteriores. Con Visual Studio, los catálogos se muestran a través de IntelliSense.

Crear la canalización
Dentro de cada catálogo hay un conjunto de métodos de extensión que puede usar para crear una canalización de entrenamiento.
var pipeline = mlContext.Transforms.Concatenate("Features", new[] { "Size" })
.Append(mlContext.Regression.Trainers.Sdca(labelColumnName: "Price", maximumNumberOfIterations: 100));
En el fragmento de código, Concatenate y Sdca son métodos en el catálogo. Cada uno crea un objeto IEstimator que se anexa a la canalización.
En este momento, se han creado los objetos, pero no se ha producido ninguna ejecución.
Entrenamiento del modelo
Una vez que se han creado los objetos en la canalización, se pueden usar datos para entrenar el modelo.
var model = pipeline.Fit(trainingData);
Una llamada a Fit() usa los datos de entrenamiento de entrada para calcular los parámetros del modelo. Esto se conoce como entrenar el modelo. Recuerde que el modelo de regresión lineal mostrado anteriormente tenía dos parámetros de modelo: sesgo y peso. Después de la llamada de Fit(), se conocen los valores de los parámetros. (La mayoría de los modelos tendrán muchos más parámetros que estos).
Puede obtener más información acerca del entrenamiento del modelo en Cómo entrenar el modelo.
El objeto del modelo resultante implementa la interfaz ITransformer. Es decir, el modelo transforma datos de entrada en predicciones.
IDataView predictions = model.Transform(inputData);
Uso del modelo
Puede transformar datos de entrada en predicciones de forma masiva o una entrada a la vez. En el ejemplo de precios de vivienda, lo hizo de ambas maneras: de forma masiva con el fin de evaluar el modelo y de uno en uno para realizar una predicción nueva. Echemos un vistazo a la realización de predicciones únicas.
var size = new HouseData() { Size = 2.5F };
var predEngine = mlContext.CreatePredictionEngine<HouseData, Prediction>(model);
var price = predEngine.Predict(size);
El método CreatePredictionEngine() toma una clase de entrada y una clase de salida. Los atributos de código o los nombres de campo determinan los nombres de las columnas de datos utilizadas durante el entrenamiento del modelo y la predicción. Para obtener más información, vea Realización de predicciones con un modelo entrenado.
Esquema y modelos de datos
En el núcleo de una canalización de aprendizaje automático de ML.NET están los objetos DataView.
Cada transformación en la canalización tiene un esquema de entrada (nombres, tipos y tamaños de datos que la transformación espera ver en su entrada), así como un esquema de salida (nombres, tipos y tamaños de datos que la transformación produce después de la misma).
Si el esquema de salida de una transformación en la canalización no coincide con el esquema de entrada de la siguiente transformación, ML.NET producirá una excepción.
Un objeto de vista de datos tiene columnas y filas. Cada columna tiene un nombre, un tipo y una longitud. Por ejemplo, las columnas de entrada en el ejemplo de precios de vivienda son Tamaño y Precio. Ambas son tipos y cantidades escalares, en lugar de vectores.
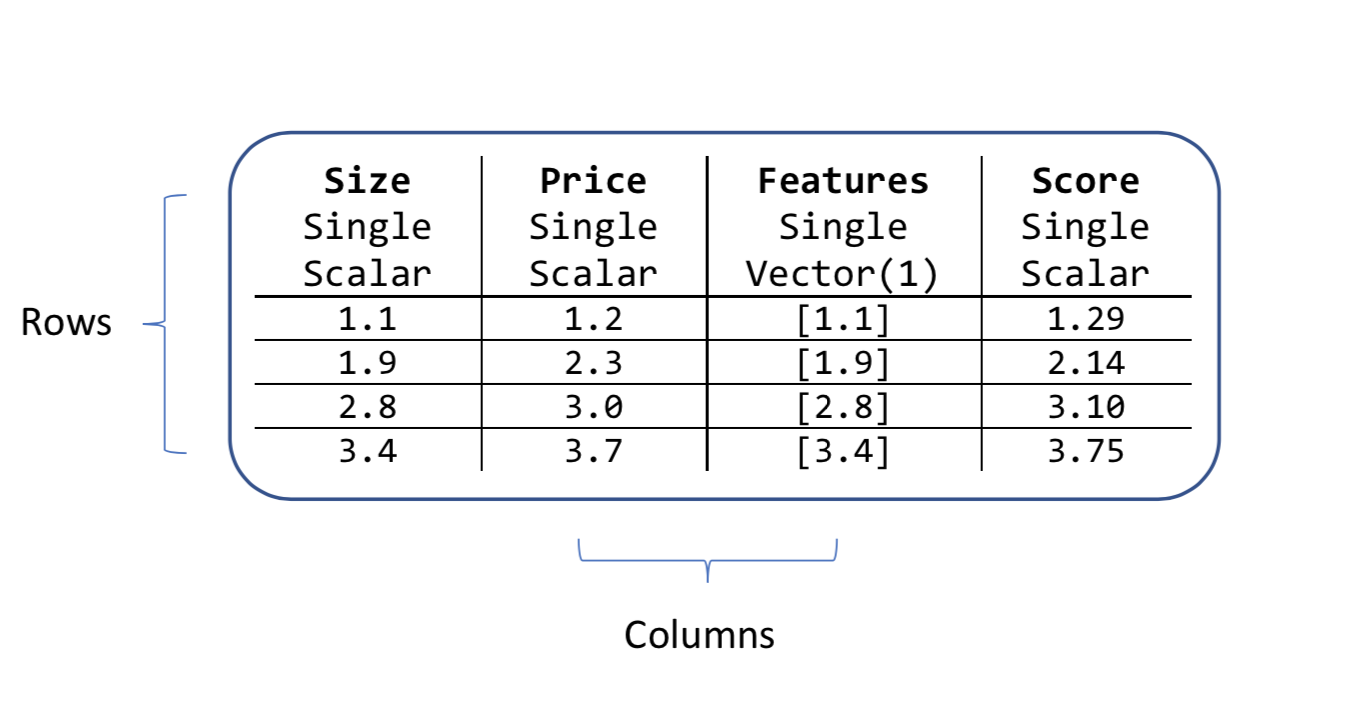
Todos los algoritmos ML.NET buscan una columna de entrada que sea un vector. De forma predeterminada, esta columna de vector se denomina Características. Este es el motivo por el que, en el ejemplo de precios de vivienda, concatenó la columna Tamaño en una nueva columna denominada Características.
var pipeline = mlContext.Transforms.Concatenate("Features", new[] { "Size" })
Todos los algoritmos también crean nuevas columnas una vez que han realizado una predicción. Los nombres fijos de estas nuevas columnas dependen del tipo de algoritmo de aprendizaje automático. Para la tarea de regresión, una de las nuevas columnas se denomina Puntuación, como se muestra en el atributo de datos de precios.
public class Prediction
{
[ColumnName("Score")]
public float Price { get; set; }
}
Si desea obtener más información acerca de las columnas de salida de diferentes tareas de aprendizaje automático, vea la guía Tareas de Machine Learning.
Una propiedad importante de los objetos DataView es que se evalúan de forma diferida. Las vistas de datos solo se cargan y utilizan en las operaciones durante el entrenamiento del modelo, la evaluación y la predicción de datos. Mientras escribe y prueba la aplicación de ML.NET, puede utilizar el depurador de Visual Studio para echar un vistazo a cualquier objeto de vista de datos llamando al método Preview.
var debug = testPriceDataView.Preview();
Puede ver la variable debug en el depurador y examinar su contenido. No utilice el método Preview en el código de producción, ya que reduce significativamente el rendimiento.
Implementación de modelo
En las aplicaciones de la vida real, el código de entrenamiento y evaluación del modelo será independiente de la predicción. De hecho, estas dos actividades las realizan a menudo equipos diferentes. El equipo de desarrollo del modelo puede guardar el modelo para su uso en la aplicación de predicción.
mlContext.Model.Save(model, trainingData.Schema,"model.zip");
Pasos siguientes
Aprenda a crear aplicaciones mediante diferentes tareas de aprendizaje automático con conjuntos de datos más realistas en los tutoriales.
Obtenga información más detallada sobre temas específicos en las guías de instrucciones.
Si está muy interesado, puede sumergirse directamente en la documentación de referencia de la API.
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de