Análisis de opiniones mediante la CLI de ML.NET
Aprenda a usar la CLI de ML.NET para generar automáticamente un modelo de ML.NET y el código de C# subyacente. Usted proporciona el conjunto de datos y la tarea de aprendizaje automático que quiere implementar, y la CLI utiliza el motor de AutoML para crear el código fuente de implementación y generación de modelos, así como el modelo de clasificación.
En este tutorial, llevará a cabo los pasos siguientes:
- Preparar los datos para la tarea de aprendizaje automático seleccionada
- Ejecución del comando "mlnet classification" desde la CLI
- Revisar los resultados de métrica de calidad
- Comprender el código de C# generado para usar el modelo en la aplicación
- Explorar el código de C# generado que se usó para entrenar el modelo
Nota:
Este tema hace referencia a la herramienta de la CLI de ML.NET, que se encuentra actualmente en versión preliminar, por lo que el material está sujeto a cambios. Para obtener más información, visite la página de ML.NET.
La CLI de ML.NET forma parte de ML.NET y su objetivo principal es "democratizar" ML.NET para desarrolladores de .NET durante el aprendizaje de ML.NET, por lo que no es necesario codificar desde cero para empezar a trabajar.
Puede ejecutar la CLI de ML.NET en cualquier símbolo del sistema (Windows, Mac o Linux) para generar modelos de ML.NET de buena calidad y el código fuente basado en los conjuntos de datos de entrenamiento que proporcione.
Requisitos previos
- SDK de .NET Core 6 o versiones posteriores.
- (Opcional) Visual Studio
- CLI de ML.NET
Puede ejecutar los proyectos del código de C# generado desde Visual Studio o con dotnet run (CLI de .NET).
Preparar los datos
Vamos a usar un conjunto de datos existente utilizado para un escenario de "análisis de sentimiento", que es una tarea de aprendizaje automático de clasificación binaria. Puede usar su propio conjunto de datos de forma similar, y el modelo y el código se generarán automáticamente.
Descargue el archivo ZIP del conjunto de datos UCI Sentiment Labeled Sentences (vea la referencia en la nota siguiente) y descomprímalo en la carpeta de su elección.
Nota:
Los conjuntos de datos que se utilizan en este tutorial provienen de "From Group to Individual Labels using Deep Features", Kotzias et. al., KDD 2015, and hosted at the UCI Machine Learning Repository - Dua, D. and Karra Taniskidou, E. (2017). UCI Machine Learning Repository [http://archive.ics.uci.edu/ml ]. Irvine, CA: University of California, School of Information and Computer Science.
Copie el archivo
yelp_labelled.txten cualquier carpeta que haya creado anteriormente (como/cli-test).Abra su símbolo del sistema preferido y muévalo a la carpeta donde copió el archivo del conjunto de datos. Por ejemplo:
cd /cli-testCon cualquier editor de texto como Visual Studio Code, puede abrir y explorar el archivo del conjunto de datos
yelp_labelled.txt. Puede ver la estructura de la siguiente manera:El archivo no tiene encabezado. Usará el índice de la columna.
Solo hay dos columnas:
Texto (índice de la columna 0) Etiqueta (índice de la columna 1) ¡Anda! Me encantó el lugar. 1 La corteza no es buena. 0 No es sabrosa y la textura era simplemente desagradable. 0 ...MUCHAS MÁS FILAS DE TEXTO... ...(1 o 0)...
Asegúrese de cerrar el archivo del conjunto de datos desde el editor.
Ya está listo para empezar a usar la CLI en este escenario de "análisis de sentimiento".
Nota:
Al finalizar este tutorial, también puede probar con sus propios conjuntos de datos, siempre que estén listos para usarse en cualquiera de las tareas de ML compatibles actualmente con la versión preliminar de la CLI de ML.NET, que son "Clasificación binaria", "Clasificación", "Regresión" y "Recomendación" .
Ejecución del comando "mlnet classification"
Ejecute el siguiente comando de la CLI de ML.NET:
mlnet classification --dataset "yelp_labelled.txt" --label-col 1 --has-header false --train-time 10Este comando ejecuta el comando
mlnet classification:- para la Tarea de Machine Learning de clasificación
- usa el archivo del conjunto de datos
yelp_labelled.txtcomo conjunto de datos de entrenamiento y pruebas (internamente la CLI utilizará la validación cruzada o lo dividirá en dos conjuntos de datos: uno para el entrenamiento y otro para las pruebas) - donde la columna de objetivo/destino que desea predecir (comúnmente denominada "etiqueta" ) es la columna con el índice 1 (que es la segunda columna, ya que el índice es de base cero)
- no usa un encabezado de archivo con nombres de columna, puesto que este archivo de conjunto de datos concreto no tiene un encabezado
- el tiempo de exploración/entrenamiento de destino del experimento es de 10 segundos
Verá la salida de la CLI, similar a:
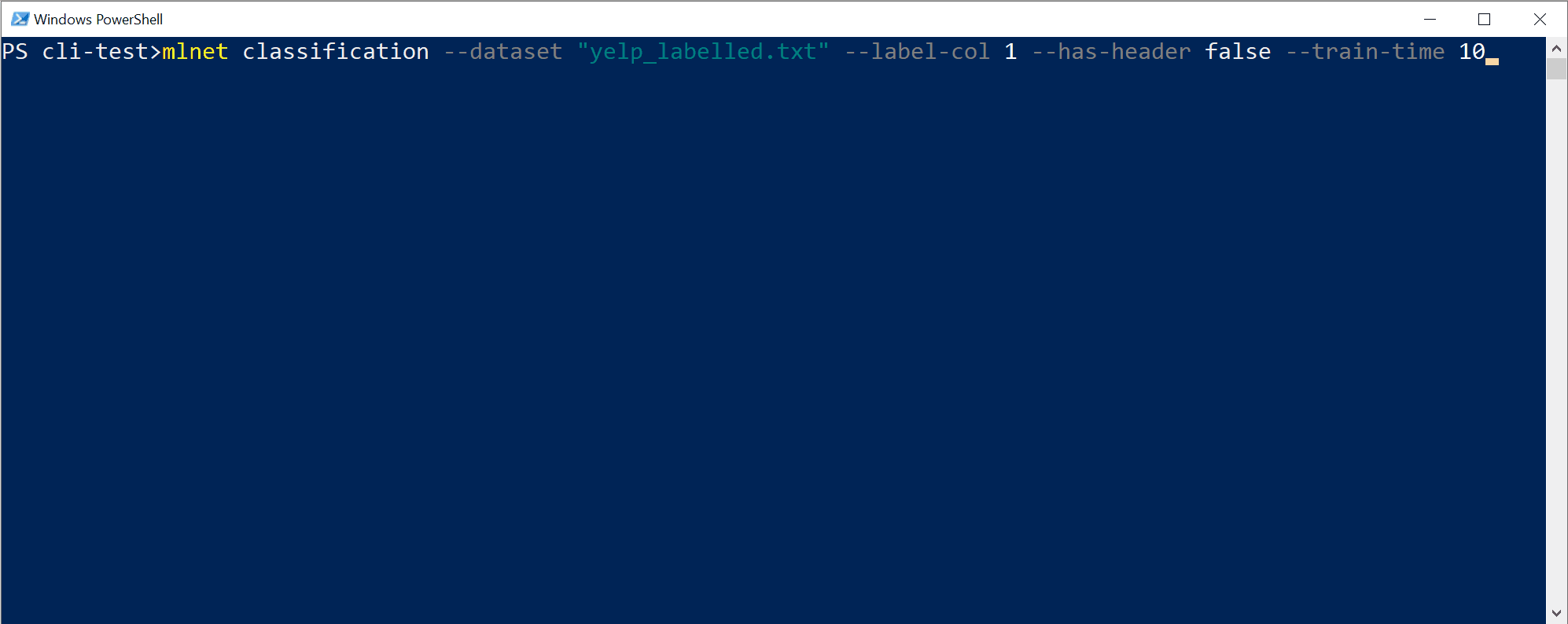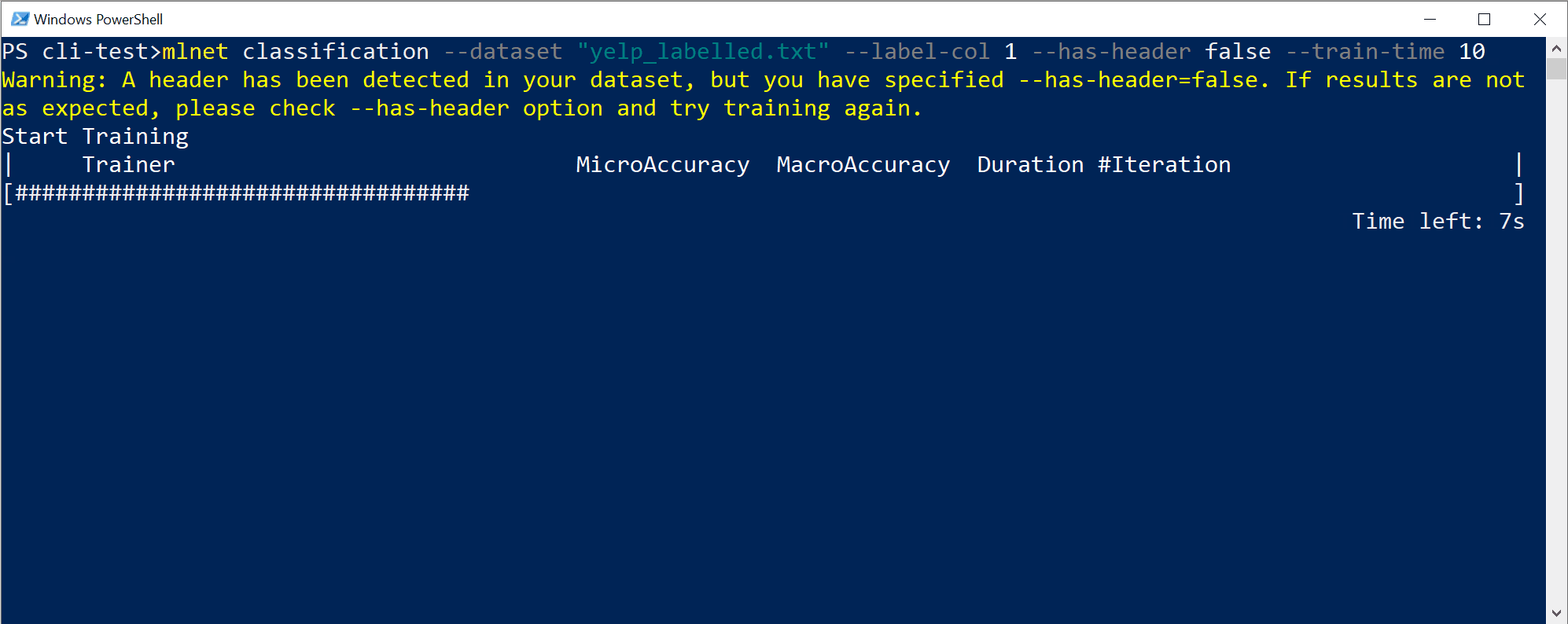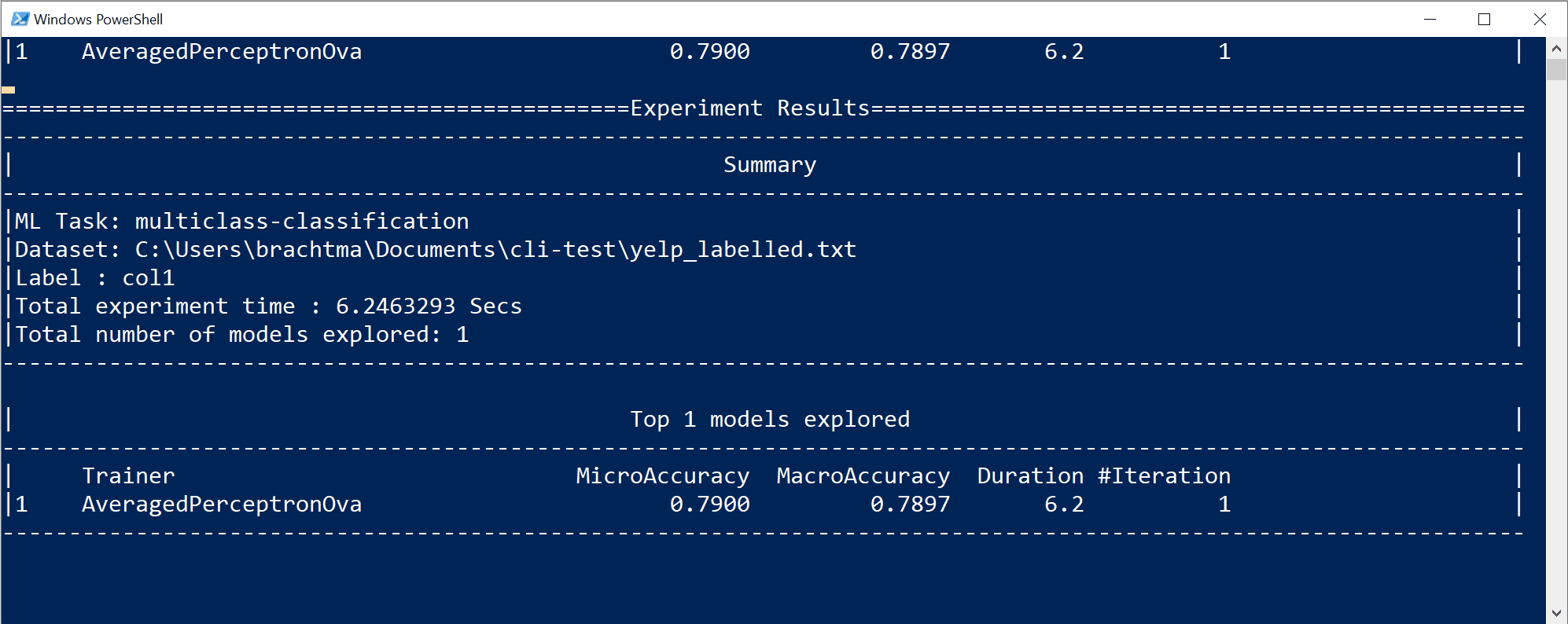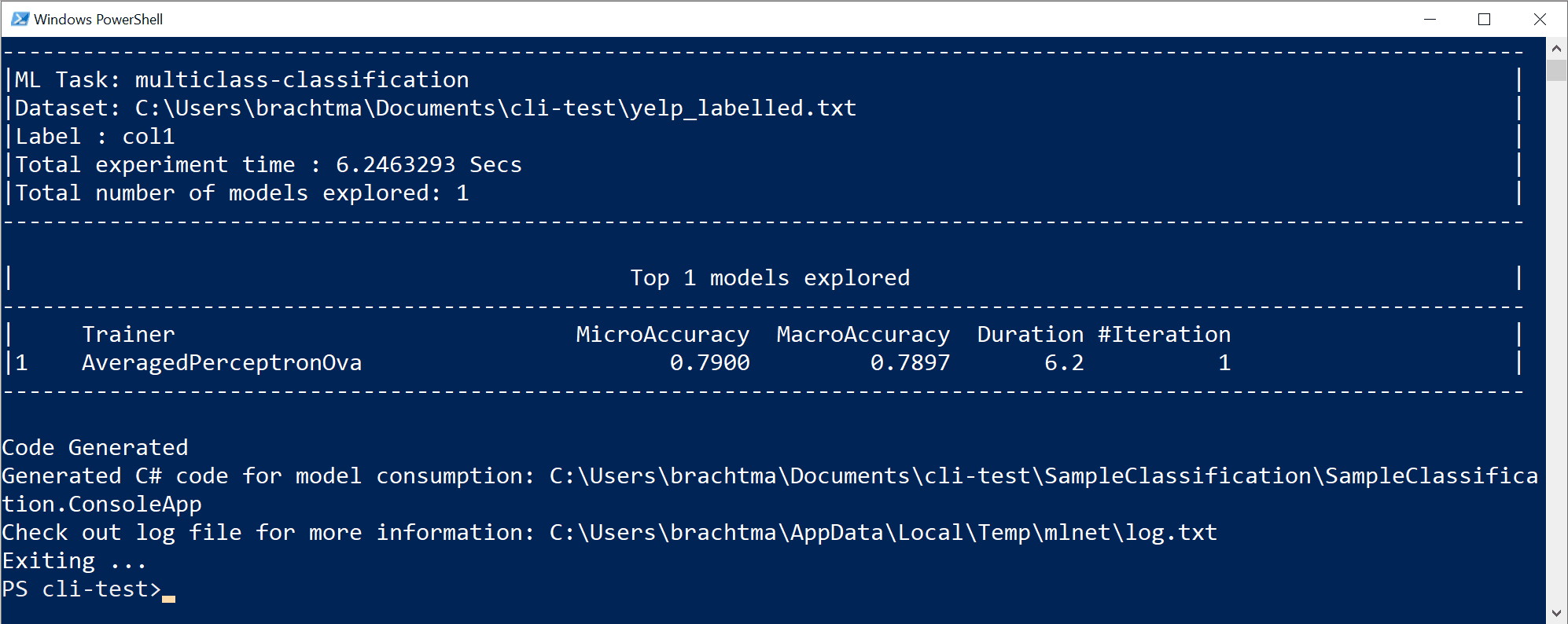
En este caso en concreto, en solo 10 segundos y con el pequeño conjunto de datos proporcionado, la herramienta de la CLI fue capaz de ejecutar varias iteraciones, lo que implica entrenar varias veces según diferentes combinaciones de algoritmos o la configuración con diferentes transformaciones de datos internos e hiperparámetros del algoritmo.
Por último, el modelo de "mejor calidad" que se encontró en 10 segundos es un modelo que usa un instructor o algoritmo concreto con cualquier configuración específica. Según el tiempo de exploración, el comando puede generar un resultado diferente. La selección se basa en las diversas métricas que se muestran, como
Accuracy.Descripción de las métricas de calidad del modelo
La primera métrica y la más sencilla para evaluar un modelo de clasificación binaria es la precisión, la cual es muy fácil de entender. "La precisión es la proporción de predicciones correctas con un conjunto de datos de prueba". Cuanto más cerca del 100 % (1,00), mejor.
Sin embargo, hay casos en los que solo medir con la métrica de precisión no es suficiente, especialmente cuando la etiqueta (0 y 1 en este caso) está desequilibrada en el conjunto de datos de prueba.
Para ver métricas adicionales e información más detallada acerca de las métricas, como la precisión, AUC, AUCPR y la puntuación F1 utilizada para evaluar los distintos modelos, lea Descripción de las métricas de ML.NET.
Nota:
Puede probar este mismo conjunto de datos y especificar unos minutos para
--max-exploration-time(por ejemplo, tres minutos, por lo que se especifican 180 segundos) que encontrará un "mejor modelo" con una configuración de canalización de entrenamiento distinta para este conjunto de datos (que es bastante pequeño: 1000 filas).Para encontrar un modelo de "mejor o buena calidad" que sea un "modelo listo para la producción" dirigido a conjuntos de datos grandes, debe realizar experimentos con la CLI normalmente especificando mucho más tiempo de exploración según el tamaño del conjunto de datos. De hecho, en muchos casos es posible que necesite varias horas de exploración, sobre todo si el conjunto de datos es de gran tamaño en filas y columnas.
La ejecución del comando anterior ha generado los siguientes recursos:
- Un .zip de modelo serializado ("mejor modelo") listo para usarse.
- El código de C# para ejecutar o calificar dicho modelo generado (para realizar predicciones en las aplicaciones del usuario final con ese modelo).
- El código de entrenamiento de C# utilizado para generar ese modelo (con fines de aprendizaje).
- Un archivo de registro con todas las iteraciones exploradas con información detallada específica acerca de cada algoritmo que se ha intentado con su combinación de hiperparámetros y transformaciones de datos.
Los dos primeros recursos (modelo de archivo ZIP y el código de C# para ejecutar ese modelo) se pueden usar directamente en las aplicaciones de usuario final (aplicación web ASP.NET Core, servicios, aplicación de escritorio, etc.) para realizar predicciones con dicho modelo de ML generado.
El tercer recurso, el código de aprendizaje, le muestra el código de la API de ML.NET que utilizó la CLI para entrenar el modelo generado, de modo que pueda investigar qué hiperparámetros y algoritmos o instructores específicos seleccionó la CLI.
Esos recursos enumerados se explican en los pasos siguientes del tutorial.
Explorar el código de C# generado que se usará para ejecutar el modelo a fin de realizar predicciones
En Visual Studio, abra la solución generada en la carpeta denominada
SampleClassificationdentro de la carpeta de destino original (denominada/cli-testen el tutorial). Debería ver una solución similar a esta:
Nota:
En el tutorial, se recomienda usar Visual Studio, pero también puede explorar el código de C# generado (dos proyectos) con cualquier editor de texto y ejecutar la aplicación de consola generada con la
dotnet CLIen macOS, máquina Linux o Windows.- La aplicación de consola generada contiene un código de ejecución que debe revisar. Después, normalmente reutiliza el "código de puntuación" (el código que ejecuta el modelo de ML para realizar predicciones) moviendo ese código sencillo (unas cuantas líneas) a la aplicación del usuario final en la que quiere realizar las predicciones.
- El archivo mbconfig generado es un archivo de configuración que se puede usar para volver a entrenar el modelo, ya sea a través de la CLI o de Model Builder. Esto también tendrá dos archivos de código asociados con él y un archivo ZIP.
- El archivo de entrenamiento contiene el código para compilar la canalización de modelo mediante la API de ML.NET.
- El archivo de consumo contiene el código para consumir el modelo.
- El archivo ZIP es el modelo generado a partir de la CLI.
Abra el archivo SampleClassification.consumption.cs en el archivo mbconfig. Verá que hay clases de entrada y salida. Estas son clases de datos, o clases POCO, que se usan para contener datos. Las clases contienen código reutilizable que resulta útil si el conjunto de datos tiene decenas o incluso cientos de columnas.
- La clase
ModelInputse usa al leer los datos del conjunto de datos. - La clase
ModelOutputse utiliza para obtener el resultado de la predicción (datos de predicción).
- La clase
Abra el archivo Program.cs y explore el código. En unas cuantas líneas, podrá ejecutar el modelo y realizar una predicción de ejemplo.
static void Main(string[] args) { // Create single instance of sample data from first line of dataset for model input ModelInput sampleData = new ModelInput() { Col0 = @"Wow... Loved this place.", }; // Make a single prediction on the sample data and print results var predictionResult = SampleClassification.Predict(sampleData); Console.WriteLine("Using model to make single prediction -- Comparing actual Col1 with predicted Col1 from sample data...\n\n"); Console.WriteLine($"Col0: {sampleData.Col0}"); Console.WriteLine($"\n\nPredicted Col1 value {predictionResult.PredictedLabel} \nPredicted Col1 scores: [{String.Join(",", predictionResult.Score)}]\n\n"); Console.WriteLine("=============== End of process, hit any key to finish ==============="); Console.ReadKey(); }Las primeras líneas de código crean datos de ejemplo únicos, en este caso basados en la primera fila del conjunto de datos que se va a usar para la predicción. También puede crear sus propios datos "codificados de forma rígida" si actualiza el código:
ModelInput sampleData = new ModelInput() { Col0 = "The ML.NET CLI is great for getting started. Very cool!" };La siguiente línea de código usa el método
SampleClassification.Predict()en los datos de entrada especificados para crear una predicción y devolver los resultados (según el esquema ModelOutput.cs).Las últimas líneas de código imprimen las propiedades de los datos de ejemplo (en este caso, el comentario), así como la predicción de opiniones y las puntuaciones correspondientes para la opinión positiva (1) y la opinión negativa (2).
Ejecute el proyecto, ya sea mediante los datos de ejemplo originales cargados desde la primera fila del conjunto de datos o proporcionando sus propios datos de ejemplo codificados de forma rígida y personalizados. Debería obtener una predicción comparable a esta:
 )
)
- Pruebe a cambiar los datos de ejemplo codificados de forma rígida a otras frases con diferentes opiniones y vea cómo el modelo predice opiniones positivas o negativas.
Incorporar las aplicaciones del usuario final con predicciones del modelo de ML
Puede usar un "código de puntuación del modelo de ML" similar para ejecutar el modelo en la aplicación del usuario final y realizar predicciones.
Por ejemplo, podría mover directamente ese código a cualquier aplicación de escritorio de Windows como WPF y WinForms y ejecutar el modelo de la misma manera que se realizó en la aplicación de consola.
Sin embargo, la forma de implementar esas líneas de código para ejecutar un modelo de ML debe optimizarse (es decir, copie en caché el archivo .zip del modelo y cárguelo una vez) y debe tener objetos singleton en lugar de crearlos en cada solicitud, especialmente si la aplicación debe ser escalable como una aplicación web o un servicio distribuido, tal como se explica en la sección siguiente.
Ejecución de modelos de ML.NET en aplicaciones web y servicios escalables de ASP.NET Core (aplicaciones multiproceso)
La creación del objeto de modelo (ITransformer cargado desde el archivo .zip de un modelo) y el objeto PredictionEngine debe optimizarse especialmente cuando se ejecuta en aplicaciones web escalables y servicios distribuidos. En el primer caso, el objeto de modelo (ITransformer), la optimización es sencilla. Puesto que el objeto ITransformer es seguro para subprocesos, puede copiar en caché el objeto como un singleton o un objeto estático para cargar el modelo una vez.
En el segundo objeto, el objeto PredictionEngine, no es tan fácil porque el objeto PredictionEngine no es seguro para subprocesos, por lo que no se puede crear una instancia de este objeto como singleton u objeto estático en una aplicación de ASP.NET Core. Este problema de escalabilidad y seguridad para subprocesos se describe detalladamente en esta entrada de blog.
Sin embargo, las cosas ahora son mucho más fáciles de lo que se explica en esa entrada de blog. Hemos trabajado en un enfoque más sencillo para usted y hemos creado un buen "paquete de integración de .NET Core" que puede usar fácilmente en sus servicios y aplicaciones de ASP.NET Core registrándolos en los servicios de DI de la aplicación (servicios de inserción de dependencias) y usándolos directamente desde el código. Consulte el siguiente tutorial y ejemplo para hacerlo:
- Tutorial: Ejecución de modelos de ML.NET en aplicaciones web escalables de ASP.NET Core y WebAPI
- Ejemplo: Modelo de ML.NET escalable en ASP.NET Core WebAPI
Explorar el código de C# generado que se usó para entrenar el modelo de "mejor calidad"
Para fines de aprendizaje más avanzados, también puede explorar el código de C# generado que utilizó la herramienta de la CLI para entrenar el modelo generado.
Dicho código de modelo de entrenamiento se genera en el archivo denominado SampleClassification.training.cs para que pueda investigar ese código de entrenamiento.
Más importante aún, para este escenario en particular (modelo de análisis de sentimiento) también puede comparar dicho código de entrenamiento generado con el código que se explica en el tutorial siguiente:
- Comparación: Tutorial: Uso de ML.NET en un escenario de clasificación binaria de análisis de sentimiento.
Resulta interesante comparar el algoritmo elegido y la configuración de canalización en el tutorial con el código generado por la herramienta de la CLI. Según cuánto tiempo dedique a iterar y buscar modelos mejores, el algoritmo elegido podría ser diferente, junto con su configuración de canalización e hiperparámetros determinados.
En este tutorial ha aprendido a:
- Preparar los datos para la tarea de ML seleccionada (problema para resolver)
- Ejecución del comando "mlnet classification" en la herramienta de la CLI
- Revisar los resultados de métrica de calidad
- Comprender el código de C# generado para ejecutar el modelo (código para usar en la aplicación del usuario final)
- Exploración del código de C# generado que se usó para entrenar el modelo de "mejor calidad" (con fines de aprendizaje)
Vea también
- Automatizar el entrenamiento del modelo con la CLI de ML.NET
- Tutorial: Ejecución de modelos de ML.NET en aplicaciones web escalables de ASP.NET Core y WebAPI
- Ejemplo: Modelo de ML.NET escalable en ASP.NET Core WebAPI
- Guía de referencia de comandos de entrenamiento automático de la CLI de ML.NET
- Telemetría en la CLI de ML.NET
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de