Caso práctico: Sistema de archivos distribuido Hadoop (HDFS)
El modelo de programación de MapReduce permite estructurar los trabajos de cálculo de acuerdo a dos funciones: de asignación y de reducción. La entrada se alimenta como pares clave-valor en MapReduce, donde se procesa mediante una función de asignación y se alimenta en una función de reducción. Luego, la operación de reducción genera un resultado, que también está en forma de pares clave-valor. MapReduce está diseñado para ejecutar muchas instancias de operaciones de asignación y reducción en paralelo en un clúster de cálculo de gran tamaño. El modelo de programación de MapReduce se trata en detalle en un módulo posterior.
El modelo de programación de MapReduce presupone la disponibilidad de un sistema de almacenamiento distribuido que está disponible en todos los nodos del clúster, con un único espacio de nombres, que es donde entra un sistema de archivos distribuido (DFS). Un DFS se coloca con los nodos del clúster de MapReduce. El DFS está diseñado para trabajar conjuntamente con MapReduce y mantiene un espacio de nombres único para todo el clúster de MapReduce.
Una versión de código abierto de MapReduce, denominada Apache Hadoop2, es muy popular en círculos de macrodatos. HDFS es un DFS de código abierto. HDFS está diseñado como sistema de archivos distribuido, escalable y tolerante a errores que atiende principalmente a las necesidades del modelo de programación de MapReduce. En el vídeo 4.12 se presenta HDFS.
Es importante tener en cuenta que HDFS no es compatible con POSIX ni es un sistema de archivos que se pueda montar por sí mismo. Se suele acceder a HDFS a través de clientes HDFS o mediante llamadas de interfaz de programación de aplicaciones (API) desde las bibliotecas de Hadoop. Pero el desarrollo de un controlador de sistema de archivos en el espacio de usuario (FUSE) para (HDFS) permite montarlo como un dispositivo virtual en sistemas operativos similares a UNIX.
Arquitectura de HDFS
Como se ha explicado anteriormente, HDFS es un DFS diseñado para ejecutarse en un clúster de nodos y cuya arquitectura tiene los siguientes objetivos:
- Un solo espacio de nombres común para todo el clúster
- Capacidad para almacenar archivos de gran tamaño (por ejemplo, terabytes o petabytes)
- Compatibilidad con el modelo de programación de MapReduce
- Transmisión de acceso a datos para patrones de acceso a datos de una sola escritura y varias lecturas
- Alta disponibilidad con hardware estándar
En la siguiente figura se muestra un clúster de HDFS:
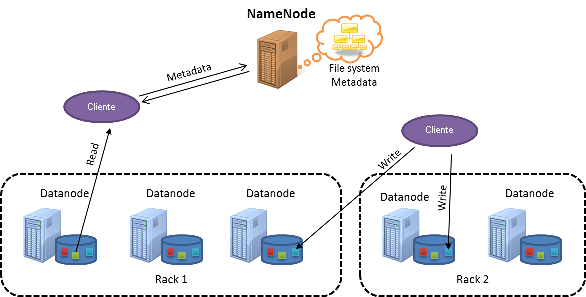
Figura 1: Arquitectura de HDFS
HDFS sigue un diseño maestro-subordinado. El nodo maestro se denomina NameNode. El NameNode controla la administración de metadatos de todo el clúster y mantiene un espacio de nombres único para todos los archivos almacenados en HDFS. Los nodos subordinados se conocen como DataNodes. Los DataNodes almacenan los bloques de datos reales en el sistema de archivos local dentro de cada nodo.
Los archivos de HDFS se dividen en bloques (también denominados fragmentos), con un tamaño predeterminado de 128 MB cada uno. En cambio, los sistemas de archivos locales suelen tener tamaños de bloque de unos 4 KB. HDFS usa tamaños de bloque grandes porque está diseñado para almacenar archivos de gran tamaño de una manera que resulte eficaz para procesar con trabajos de MapReduce.
De forma predeterminada, una única tarea de asignación de MapReduce está configurada para funcionar en un solo bloque de HDFS de forma independiente y, por tanto, varias tareas de asignación pueden procesar varios bloques de HDFS en paralelo. Si el tamaño del bloque es demasiado pequeño, es necesario distribuir un gran número de tareas de asignación entre los nodos del clúster y la sobrecarga de esto podría afectar negativamente al rendimiento. Por otro lado, si el bloque es demasiado grande, se reduce el número de tareas de asignación que pueden procesar el archivo en paralelo, lo que afecta al paralelismo. HDFS permite especificar tamaños de bloque por archivo, así que los usuarios pueden ajustar el tamaño del bloque para lograr el nivel de paralelismo que quieren. La interacción de MapReduce con HDFS se trata en detalle en un módulo posterior.
Además, dado que HDFS está diseñado para tolerar errores de nodos individuales, los bloques de datos se replican en los nodos para ofrecer redundancia de datos. Este proceso se detalla en las secciones siguientes.
Topología de clúster en HDFS
Los clústeres de Hadoop suelen implementarse en un centro de datos que consta de varios bastidores de servidores conectados mediante una topología de árbol grueso, como se ha explicado en un módulo anterior. Para ello, HDFS se ha diseñado con reconocimiento de topología de clúster, lo que ayuda a tomar decisiones de selección de ubicación de bloques para influir en el rendimiento y la tolerancia a errores. Los clústeres comunes de Hadoop tienen aproximadamente entre 30 y 40 servidores por bastidor, con un conmutador Gigabit dedicado al bastidor y un enlace ascendente a un conmutador o enrutador principal cuyo ancho de banda se comparte entre varios bastidores del centro de datos, como se muestra en la figura siguiente:
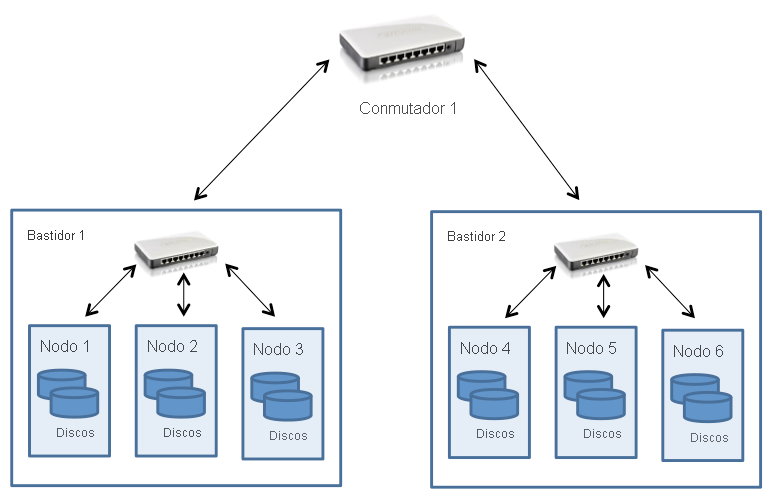
Figura 2: Topología de clúster de HDFS
El punto destacable que hay que tener en cuenta es que Hadoop presupone que el ancho de banda agregado dentro de los nodos de un bastidor es mayor que el ancho de banda agregado en los nodos de distintos bastidores. Esta premisa se ha integrado en el diseño de Hadoop en lo que se refiere al acceso a datos y a la selección de ubicación de réplicas (que se trata en las secciones siguientes).
Cuando se implementa HDFS en un clúster, los administradores del sistema pueden configurarlo con una descripción de topología que asigne cada nodo a un bastidor determinado del clúster. La distancia de red se mide en saltos, donde un salto corresponde a un vínculo en la topología. Hadoop presupone una topología de estilo de árbol, y la distancia entre dos nodos es la suma de sus distancias a su antecesor común más cercano.
En el ejemplo de la figura 2, la distancia entre el nodo 1 y él mismo es cero saltos (el caso cuando dos procesos se comunican en el mismo nodo). La distancia entre el nodo 1 y el nodo 2 es de dos saltos, mientras que la distancia entre el nodo 3 y el nodo 4 es de cuatro saltos.
El siguiente vídeo le guía a través de las operaciones de lectura y escritura de archivos en HDFS.
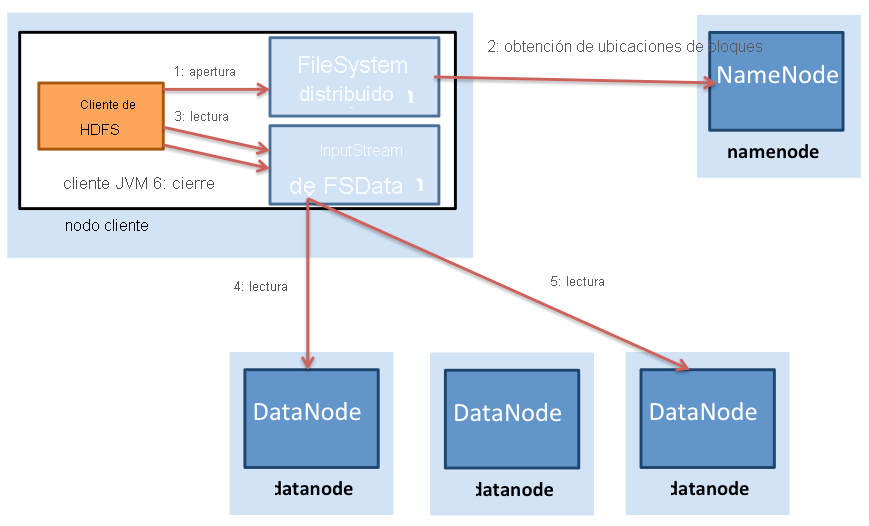
Figura 3: Lecturas de archivo en HDFS
En la figura 3 se muestra el proceso de una lectura de archivo en HDFS. Un cliente de HDFS (la entidad que necesita acceder a un archivo) primero se pone en contacto con el NameNode cuando se abre un archivo para lectura. Entonces, el NameNode proporciona al cliente una lista de ubicaciones de bloque del archivo. Hadoop también presupone que los bloques se replican en los nodos, por lo que el NameNode realmente encuentra el bloque más cercano al cliente a la hora de proporcionar la ubicación de un bloque determinado. La localidad se determina en el siguiente orden (de localidad decreciente): bloques dentro del mismo nodo que el cliente, bloques en el mismo bastidor que el cliente y bloques que están fuera del bastidor al cliente.
Una vez que se determinan las ubicaciones de bloque, el cliente abre una conexión directa a cada DataNode y transmite los datos del DataNode al proceso cliente, que se realiza cuando el cliente de HDFS invoca a la operación de lectura en el bloque de datos. Por lo tanto, no es necesario transferir el bloque en su totalidad para que el cliente pueda comenzar el cálculo, con lo que se intercalan el cálculo y la comunicación. Una vez que el cliente ha terminado de leer el primer bloque, repite este proceso con los bloques restantes hasta que ha terminado de leer todos los bloques, momento en que procede a cerrar el archivo.
Es importante tener en cuenta que los clientes se ponen en contacto directamente con el DataNode para recuperar los datos. Este contacto permite que HDFS escale a un gran número de clientes simultáneos para lecturas simultáneas y en paralelo de los datos.
Las escrituras de archivo son diferentes a las lecturas de archivo en HDFS (figura 4). Un cliente que necesita escribir datos en HDFS primero se pone en contacto con el NameNode y luego le notifica la creación de un archivo. El NameNode comprueba si el archivo ya existe y si el cliente tiene permiso para crear un archivo. Si se superan las comprobaciones, el NameNode crea un registro de un archivo nuevo.
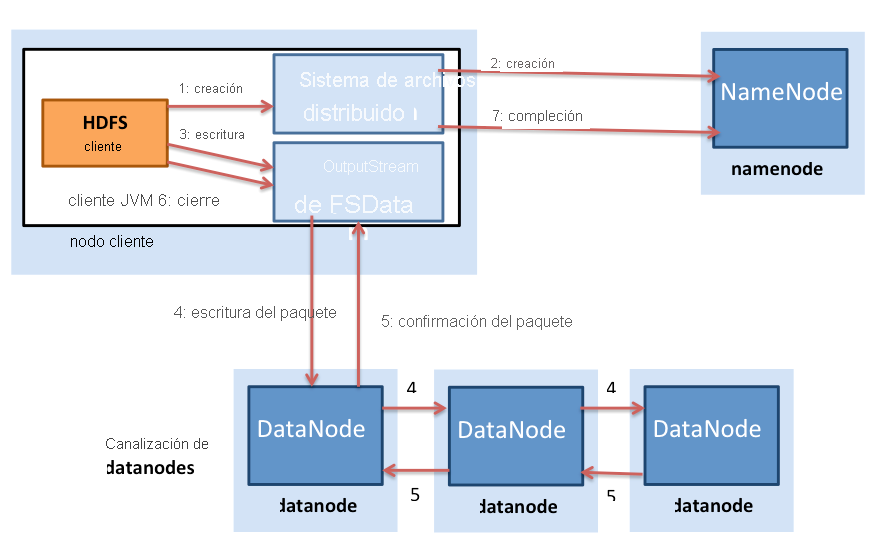
Figura 4: Escrituras de archivo en HDFS
Después, el cliente pasa a escribir el archivo en una cola de datos interna y solicita al NameNode las ubicaciones de bloques en los DataNodes del clúster. Los bloques de la cola interna se transfieren a los DataNodes individuales de una manera canalizada. El bloque se escribe en el primer DataNode, que luego canaliza el bloque a otros DataNodes para escribir réplicas del bloque. Así, los bloques se replican durante la propia escritura del archivo. Es importante tener en cuenta que HDFS no acepta una escritura en el cliente (paso 5 de la figura 4.28) hasta que los DataNodes han escrito todas las réplicas de ese archivo.
Hadoop también usa la noción de localidad del bastidor durante la selección de ubicación de la réplica. Los bloques de datos se replican por triplicado en HDFS de forma predeterminada. HDFS intenta colocar la primera réplica en el mismo nodo que el cliente que está escribiendo el bloque. Si un proceso de cliente no se esté ejecutando en el clúster de HDFS, se elige un nodo de forma aleatoria. La segunda réplica se escribe en un nodo que se encuentra en un bastidor diferente al primero (fuera de bastidor). Luego, la tercera réplica del bloque se escribe en otro nodo aleatorio en el mismo bastidor que el segundo. Las réplicas sucesivas se escriben en nodos aleatorios del clúster, pero el sistema intenta evitar colocar demasiadas réplicas en el mismo bastidor. En la figura 5 se muestra la selección de ubicación de las réplicas de un bloque replicado por triplicado en HDFS. La idea tras la selección de ubicación de las réplicas de HDFS es poder tolerar errores de nodo y de bastidor. Por ejemplo, si un bastidor completo se queda sin conexión debido a problemas de alimentación o de red, el bloque solicitado se sigue pudiendo encontrar en otro bastidor.
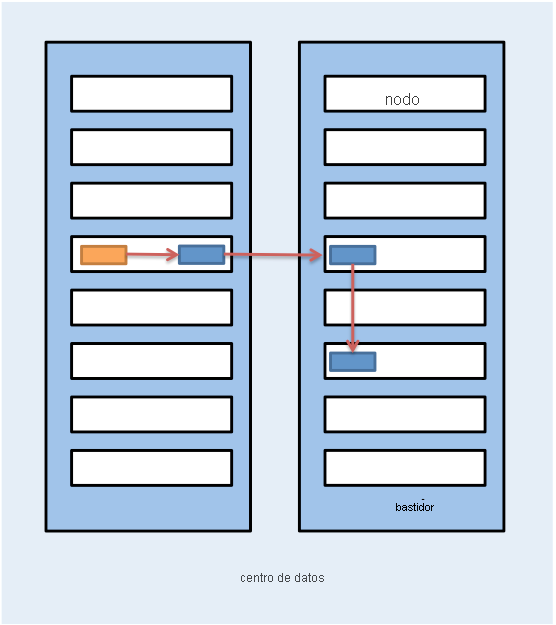
Figura 5: Selección de ubicación de las réplicas de un bloque replicado por triplicado en HDFS
Sincronización: semántica
La semántica de HDFS ha cambiado un poco. Las primeras versiones de HDFS seguían una semántica inmutable estricta. Una vez que un archivo se escribía en las versiones anteriores de HDFS, no se podía volver a abrir para escrituras, aunque los archivos se podían eliminar. Pero las versiones actuales de HDFS admiten anexiones de una manera limitada. La funcionalidad sigue siendo bastante limitada en el sentido de que los datos binarios existentes que una vez se escribieron en HDFS no se pueden modificar en el sitio.
Se optó por esta opción de diseño de HDFS porque algunas de las cargas de trabajo más comunes de MapReduce siguen el patrón de acceso a datos de una escritura y varias lecturas. MapReduce es un modelo de cálculo restringido con fases predefinidas y salidas de reductores de archivos independientes de escritura de MapReduce a HDFS como salida. HDFS se centra en los accesos de lectura rápidos y simultáneos para varios clientes a la vez.
Modelo de coherencia
HDFS es un sistema de archivos muy coherente. Cada bloque de datos se replica en varios nodos, pero una escritura se declara correcta solo después de que todas las réplicas se hayan escrito correctamente. Por lo tanto, todos los clientes deberían ver el archivo en cuanto se escribe, y la vista del archivo en todos los clientes debe ser la misma. La semántica inmutable de HDFS hace esto comparativamente sencillo, ya que se puede abrir un archivo para escritura una sola vez durante su vigencia.
Tolerancia a errores en HDFS
El mecanismo principal de tolerancia a errores de HDFS es la replicación. Como se ha señalado anteriormente, de forma predeterminada, cada bloque escrito en HDFS se replica tres veces, pero los usuarios pueden cambiar esto por archivo, si es necesario.
El NameNode realiza un seguimiento de los DataNodes mediante un mecanismo de latido. Cada DataNode envía mensajes de latido periódicos (cada pocos segundos) al NameNode. Si un DataNode queda inactivo, se detienen los latidos al NameNode. El NameNode detecta que un DataNode está inactivo si el número de mensajes de latido que faltan alcanza un umbral determinado. Entonces, el NameNode marca el DataNode como inactivo y deja de reenviar solicitudes de E/S a ese DataNode. Los bloques almacenados en ese DataNode deben tener réplicas adicionales en otros DataNodes. Además, el NameNode realiza una comprobación de estado en el sistema de archivos para detectar bloques subreplicados y realiza un proceso de reequilibrio del clúster para iniciar la replicación de los bloques que tienen menos del número deseado de réplicas.
El NameNode es un único punto de error (SPOF) en HDFS, ya que un error del NameNode desactiva todo el sistema de archivos. Internamente, el NameNode mantiene dos estructuras de datos en disco que almacenan el estado del sistema de archivos: un archivo de imagen y un registro de edición. El archivo de imagen es un punto de control de los metadatos del sistema de archivos en algún momento en el tiempo, mientras que el registro de edición es un registro de todas las transacciones de los metadatos del sistema de archivos desde la última vez que se creó el archivo de imagen. Todos los cambios entrantes en los metadatos del sistema de archivos se escriben en el registro de edición. A intervalos periódicos, los registros de edición y el archivo de imagen se combinan para crear una nueva instantánea de archivo de imagen y se borra el registro de edición. Pero si se produce un error de NameNode, los metadatos no estarían disponibles y un error de disco en el NameNode sería catastrófico, ya que los metadatos del archivo se perderían.
Para realizar una copia de seguridad de los metadatos del NameNode, HDFS permite la creación de un NameNode secundario que copia periódicamente los archivos de imagen del NameNode. Estas copias ayudan a recuperar el sistema de archivos en caso de pérdida de datos en el NameNode, pero los últimos cambios del registro de edición del NameNode se perderían. El trabajo en curso en las versiones más recientes de Hadoop tiene como finalidad crear un verdadero NameNode secundario superabundante que tome el revelo automáticamente cuando se produzca un error en el NameNode.
HDFS en la práctica
Aunque HDFS se diseñó principalmente para admitir trabajos de MapReduce de Hadoop al proporcionar un DFS para las operaciones de asignación y reducción, HDFS ha encontrado una gran cantidad de usos con las herramientas de macrodatos.
HDFS se usa en varios proyectos de Apache que se basan en el marco de Hadoop, incluidos Pig, Hive, HBase y Giraph. La compatibilidad de HDFS también se incluye en otros proyectos, como GraphLab.
Las principales ventajas de HDFS incluyen:
- Alto ancho de banda para cargas de trabajo de MapReduce: se sabe que los clústeres de gran tamaño de Hadoop (miles de equipos) escriben continuamente hasta 1 terabyte por segundo con HDFS.
- Alta confiabilidad: la tolerancia a errores es un objetivo de diseño principal de HDFS. La replicación de HDFS proporciona alta confiabilidad y disponibilidad, especialmente en clústeres de gran tamaño, en los que la probabilidad de errores de disco y servidor aumenta considerablemente.
- Bajo costo por byte: en comparación con una solución de disco compartido dedicada, como una SAN, HDFS cuesta menos por gigabyte porque el almacenamiento convive con servidores de proceso. Con SAN, tiene que pagar costos adicionales por la infraestructura administrada, como el contenedor de la matriz de discos y los discos empresariales de mayor nivel, para administrar los errores de hardware. HDFS está diseñado para ejecutarse con hardware estándar y la redundancia se administra en software para tolerar errores.
- Escalabilidad: HDFS permite que se agreguen DataNodes a un clúster en ejecución y ofrece herramientas para reequilibrar manualmente los bloques de datos cuando se agregan nodos de clúster, lo que se puede hacer sin apagar el sistema de archivos.
Las principales desventajas de HDFS incluyen:
- Ineficiencias con archivos pequeños: HDFS está diseñado para usarse con tamaños de bloque grandes (64 MB y más). Está pensado para tomar archivos grandes (cientos de megabytes, gigabytes o terabytes) y fragmentarlos en bloques, que se pueden alimentar a trabajos de MapReduce para su procesamiento en paralelo. HDFS resulta ineficaz cuando los tamaños de archivo reales son pequeños (en el rango de los kilobytes). El tener un gran número de archivos pequeños coloca una sobrecarga adicional en el NameNode, que tiene que mantener metadatos de todos los archivos del sistema de archivos. Normalmente, los usuarios de HDFS combinan muchos archivos pequeños en otros más grandes mediante técnicas como los archivos de secuencia.
- No compatibilidad con POSIX: HDFS no se diseñó como sistema de archivos que se puede montar compatible con POSIX; las aplicaciones tienen que escribirse desde cero o modificarse para usar un cliente de HDFS. Existen soluciones alternativas que permiten montar HDFS con un controlador FUSE, pero la semántica del sistema de archivos no permite operaciones de escritura en archivos una vez que se han cerrado.
- Modelo de una sola escritura: el modelo de una sola escritura es un posible inconveniente para las aplicaciones que requieren acceso simultáneo de escritura al mismo archivo. Pero la versión más reciente de HDFS ya admite anexiones de archivos.
En resumen, HDFS es una buena opción como back-end de almacenamiento para aplicaciones distribuidas que siguen el modelo de MapReduce o que se han escrito específicamente para usar HDFS. HDFS se puede usar de forma eficaz con un pequeño número de archivos grandes en lugar de un gran número de archivos pequeños.
Referencias
- Sanjay Ghemawat, Howard Gobioff y Shun-Tak Leung (2003). The Google File Systems 19º simposio de ACM sobre principios de sistemas operativos
- White, Tom (2012). Hadoop: The Definitive Guide O'Reilly Media, Yahoo Press