Análisis de la respuesta de la API de documentos
Este contenido se aplica a:![]() v4.0 (versión preliminar)
v4.0 (versión preliminar)![]() v3.1 (GA)
v3.1 (GA)![]() v3.0 (GA)
v3.0 (GA)
En este artículo, examinaremos los distintos objetos devueltos como parte de la respuesta AnalyzeDocument y cómo usar la respuesta de la API de análisis de documentos en las aplicaciones.
Análisis de la solicitud de documento
Las API de Documento de inteligencia analizan imágenes, archivos PDF y otros archivos de documentos a fin de extraer y detectar varios elementos de contenido, diseño, estilo y semántica. La operación de análisis es una API asincrónica. El envío de un documento devuelve un encabezado Operación-Ubicación que contiene la dirección URL que se debe sondear para comprobar si se ha completado. Cuando una solicitud de análisis se completa correctamente, la respuesta contiene los elementos que se describen en la extracción de datos del modelo.
Elementos de respuesta
Los elementos de contenido son los elementos de texto básicos que se extraen del documento.
Los elementos de diseño agrupan elementos de contenido en unidades estructurales.
Los elementos de estilo describen la fuente y el idioma de los elementos de contenido.
Los elementos semánticos asignan significado a los elementos de contenido especificados.
Todos los elementos de contenido se agrupan por páginas, especificadas por número de página (con índice 1). También se clasifican por orden de lectura, que organiza juntos los elementos semánticamente contiguos, incluso si cruzan los límites de líneas o columnas. Cuando el orden de lectura entre los párrafos y otros elementos de diseño es ambiguo, el servicio suele devolver el contenido en un orden de izquierda a derecha y de arriba abajo.
Nota:
Actualmente, Documento de inteligencia no admite el orden de lectura a través de los límites de la página. Las marcas de selección no se colocan dentro de las palabras que las rodean.
La propiedad de contenido de nivel superior contiene una concatenación de todos los elementos de contenido en orden de lectura. Todos los elementos especifican su posición en el orden de lectura mediante intervalos dentro de esta cadena de contenido. El contenido de algunos elementos no siempre es contiguo.
Análisis de la respuesta
La respuesta de análisis de cada API devuelve objetos diferentes. Las respuestas de la API contienen elementos de los modelos de componentes cuando corresponde.
| Contenido de la respuesta | Descripción | API |
|---|---|---|
| páginas | Palabras, líneas e intervalos reconocidos desde cada página del documento de entrada. | Modelos de lectura, diseño, documento general, precompilados y personalizados |
| párrafos | Contenido reconocido como párrafos. | Modelos de lectura, diseño, documento general, precompilados y personalizados |
| estilos | Propiedades de los elementos de texto identificadas. | Modelos de lectura, diseño, documento general, precompilados y personalizados |
| idiomas | Idioma identificado asociado a cada intervalo del texto extraído | Lectura |
| tablas | Contenido tabular identificado y extraído del documento. Las tablas se relacionan con las tablas que identifica el modelo de diseño entrenado previamente. El contenido etiquetado como tablas se extrae como campos estructurados en el objeto "documentos". | Diseño, documento general, factura y modelos personalizados |
| figuras | Ilustraciones (gráficos, imágenes) identificadas y extraídas del documento, proporcionando representaciones visuales que ayudan a comprender información compleja. | Modelo de diseño |
| sections | Estructura jerárquica de documentos identificada y extraída del documento. Sección o subsección con los elementos correspondientes (párrafo, tabla, figura) adjuntos. | Modelo de diseño |
| keyValuePairs | Pares clave-valor que reconoce un modelo entrenado previamente. La clave es un intervalo de texto del documento con el valor asociado. | Modelos generales de documentos y facturas |
| documentos | Los campos reconocidos se devuelven en el diccionario fields dentro de la lista de documentos |
Modelos precompilados, Modelos personalizados. |
Para obtener más información sobre los objetos que devuelve cada API, consulte Extracción de datos del modelo.
Propiedades del elemento
Intervalos
Los intervalos especifican la posición lógica de cada elemento en el orden de lectura global, y cada intervalo especifica un desplazamiento de caracteres y una longitud en la propiedad de cadena de contenido de nivel superior. Los desplazamientos y longitudes de caracteres se devuelven en unidades de caracteres percibidos por el usuario (también conocidos como elementos grapheme clusters o de texto), de manera predeterminada. A fin de adaptarse a diferentes entornos de desarrollo que usan unidades de caracteres distintas, el usuario puede especificar el parámetro de consulta stringIndexIndex para que devuelva también los desplazamientos y longitudes de intervalo en puntos de código Unicode (Python 3) o unidades de código UTF16 (Java, JavaScript, .NET). Para obtener más información, consultecompatibilidad con varios idiomas o emojis.
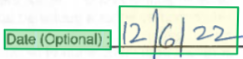
Región de límite
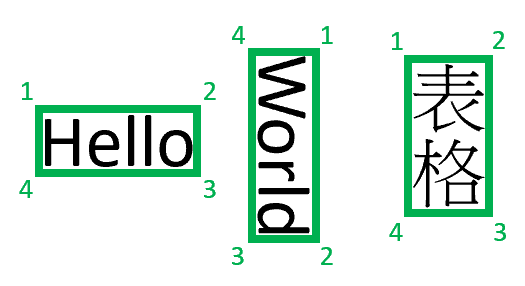
Las regiones delimitadoras describen la posición visual de cada elemento del archivo. Cuando los elementos no son visualmente contiguos o pueden pasar de página (tablas), las posiciones de la mayoría de los elementos se describen a través de una matriz de regiones delimitadoras. Cada región especifica el número de página (1i-indexado) y el polígono delimitador. El polígono delimitador se describe como una secuencia de puntos, en el sentido de las agujas del reloj desde la izquierda con respecto a la orientación natural del elemento. En el caso de los cuadriláteros, los puntos de trazado son las esquinas superior izquierda, superior derecha, inferior derecha e inferior izquierda. Cada punto representa su coordenada x, y en la unidad de página especificada por la propiedad unidad. En general, la unidad de medida de las imágenes es píxeles, mientras que los archivos PDF usan pulgadas.
Nota:
Actualmente, Documento de inteligencia solo devuelve cuatro vértices cuadriláteros como polígonos delimitadores. Es posible que futuras versiones devuelvan un número diferente de puntos para describir formas más complejas, como líneas curvas o imágenes que no sean rectangulares. Las regiones delimitadoras solo se aplican a los archivos representados; si el archivo no se representa, no se devuelven las regiones delimitadoras. Actualmente no se representan los archivos en formato docx/xlsx/pptx/html.
Elementos de contenido
Word
Una palabra es un elemento de contenido que se compone de una secuencia de caracteres. Con Documento de inteligencia, una palabra se define como una secuencia de caracteres adyacentes con espacios en blanco que separan las palabras entre sí. En el caso de los idiomas que no usan separadores de espacio entre palabras, cada carácter se devuelve como una palabra independiente, aunque no represente una unidad semántica de palabra.

Marcas de selección
Una marca de selección es un elemento de contenido que representa un glifo visual que indica el estado de una selección. La casilla es una forma común de marcas de selección. Sin embargo, también se representan mediante botones de radio o una celda en recuadro de manera visual. El estado de una marca de selección puede ser seleccionado o no seleccionado, con diferentes representaciones visuales para indicar el estado.

Elementos de diseño
Línea
Una línea es una secuencia ordenada de elementos de contenido consecutivos separados por un espacio visual, o inmediatamente adyacentes en el caso de los idiomas sin delimitadores de espacio entre palabras. Los elementos de contenido situados en el mismo plano horizontal (fila), pero separados por más de un espacio visual, suelen dividirse en varias líneas. Aunque esta característica a veces divide el contenido semánticamente contiguo en líneas independientes, permite representar contenido textual dividido en varias columnas o celdas. Las líneas en escritura vertical se detectan en dirección vertical.

Paragraph
Un párrafo es una secuencia ordenada de líneas que forman una unidad lógica. Normalmente, las líneas comparten alineación y espaciado entre líneas. Los párrafos suelen delimitarse mediante sangría, espaciado agregado, o bien viñetas o numeración. El contenido solo se puede asignar a un único párrafo. Los párrafos seleccionados también se pueden asociar a un rol funcional en el documento. Actualmente, los roles admitidos incluyen encabezado de página, pie de página, número de página, título, encabezado de sección y nota a pie de página.

Página
Una página es una agrupación de contenidos que suele corresponder a una cara de una hoja de papel. Una página representada se caracteriza por ancho y alto en la unidad especificada. En general, las imágenes usan píxeles, mientras que los PDF usan pulgadas. La propiedad angle describe el ángulo de texto general en grados para las páginas que se pueden girar.
Nota:
En el caso de las hojas de cálculo, como Excel, cada una de ellas se asigna a una página. En el caso de las presentaciones, como PowerPoint, cada diapositiva se asigna a una página. En el caso de los formatos de archivo que no tienen un concepto nativo de páginas sin renderizar, como los documentos HTML o Word, el contenido principal del archivo se considera una sola página.
Tabla
Una tabla organiza el contenido en un grupo de celdas en un diseño de cuadrícula. Las filas y columnas pueden estar separadas visualmente mediante líneas de cuadrícula, bandas de color o un mayor espaciado. La posición de una celda de tabla se especifica mediante sus índices de fila y columna. Una celda puede abarcar varias filas y columnas.
En función de su posición y estilo, una celda se puede clasificar como contenido general, encabezado de fila, encabezado de columna, encabezado de código auxiliar o descripción:
Una celda de encabezado de fila suele ser la primera celda de una fila que describe las demás celdas de dicha fila.
Una celda de encabezado de columna suele ser la primera celda de una columna que describe las demás celdas de dicha columna.
Una fila o columna puede contener varias celdas de encabezado para describir contenido jerárquico.
Una celda de encabezamiento es normalmente la celda de la primera fila y la primera columna. Puede estar vacío o describir los valores de las celdas de encabezado de la misma fila o columna.
Una celda de descripción suele aparecer en la zona superior o inferior de una tabla, de manera que describe el contenido general de la misma. Sin embargo, a veces puede aparecer en medio de una tabla para dividirla en secciones. Por lo general, las celdas de descripción abarcan varias celdas de una sola fila.
El título de la tabla especifica el contenido que esta explica. Una tabla puede tener además un título asociado y un conjunto de notas a pie de página. A diferencia de una celda de descripción, un título suele estar fuera del diseño de cuadrícula. Una nota al pie de tabla anota el contenido dentro de la tabla, a menudo marcado con un símbolo de nota al pie a menudo encontrado debajo de la cuadrícula de la tabla.
Las tablas de diseño difieren de los campos de documento que se extraen de los datos tabulares. Las tablas de diseño se extraen del contenido visual tabular del documento sin tener en cuenta la semántica del contenido. De hecho, algunas tablas de diseño están diseñadas exclusivamente para la presentación visual y no siempre contienen datos estructurados. El método para extraer datos estructurados de documentos con un diseño visual diverso, como los detalles de un recibo, normalmente requiere un procesamiento posterior significativo. Resulta esencial asignar los encabezados de fila o columna a campos estructurados con nombres de campo normalizados. En función del tipo de documento, use modelos precompilados o bien entrene un modelo personalizado para extraer dicho contenido estructurado. La información resultante se expone como campos de documento. Estos modelos entrenados también pueden controlar datos tabulares sin encabezados y datos estructurados en formas no tabulares; por ejemplo, la sección de experiencia laboral de un currículum.

Figuras
Las figuras (gráficos, imágenes) de los documentos desempeñan un papel fundamental en complementar y mejorar el contenido textual, proporcionando representaciones visuales que ayudan a comprender la información compleja. El objeto de ilustraciones detectado por el modelo de diseño tiene propiedades clave como boundingRegions (las ubicaciones espaciales de la figura en las páginas del documento, incluido el número de página y las coordenadas de polígono que describen el límite de la figura), spans (detalla los intervalos de texto relacionados con la figura, especificando sus desplazamientos y longitudes dentro del texto del documento. Esta conexión ayuda a asociar la figura con su contexto textual pertinente),elements (los identificadores de los elementos de texto o párrafos del documento que están relacionados o describen la figura) y caption si hay alguno.
{
"figures": [
{
"boundingRegions": [],
"spans": [],
"elements": [
"/paragraphs/15",
...
],
"caption": {
"content": "Here is a figure with some text",
"boundingRegions": [],
"spans": [],
"elements": [
"/paragraphs/15"
]
}
}
]
}
Secciones
El análisis jerárquico de la estructura de documentos es fundamental para organizar, comprender y procesar documentos extensos. Este enfoque es fundamental para segmentar semánticamente documentos largos para aumentar la comprensión, facilitar la navegación y mejorar la recuperación de información. La llegada de recuperación de generación aumentada (RAG) en la inteligencia artificial generativa de documentos subraya la importancia del análisis jerárquico de la estructura de documentos. El modelo de diseño admite secciones y subsecciones en la salida, que identifica la relación de secciones y objetos dentro de cada sección. La estructura jerárquica se mantiene en elements de cada sección.
{
"sections": [
{
"spans": [],
"elements": [
"/paragraphs/0",
"/sections/1",
"/sections/2",
"/sections/5"
]
},
...
}
Campo de formulario (par clave-valor)
Un campo de formulario consta de una etiqueta de campo (clave) y un valor. La etiqueta del campo suele ser una cadena de texto que describe el significado del campo. Suele aparecer a la izquierda del valor, aunque también puede aparecer encima o debajo de este. El valor del campo contiene el valor de contenido de una instancia de campo específica. El valor puede constar de palabras, marcas de selección y otros elementos de contenido. También puede estar vacío para los campos de formulario sin rellenar. Un tipo especial de campo de formulario tiene un valor de marca de selección con la etiqueta del campo a su derecha. El campo de documento es un concepto similar pero distinto de los campos de formulario generales. La etiqueta de campo (clave) de un campo de formulario general debe aparecer en el documento. Por tanto, por lo general no puede capturar información como el nombre del comerciante en un recibo. Los campos de documento se etiquetan y no extraen una clave. Los campos de documento solo asignan un valor extraído a una clave etiquetada. Para obtener más información, consultecampos de documentos.

Elementos de estilo
Estilo
Un elemento de estilo describe el estilo de fuente que se va a aplicar al contenido del texto. El contenido se especifica a través de intervalos en la propiedad de contenido global. Actualmente, el único estilo de fuente detectado es si el texto está escrito a mano. A medida que se agreguen otros estilos, el texto puede describirse mediante varios objetos de estilo no contradictorios. En el caso de la compactación, todos los textos que comparten el mismo estilo de fuente determinado (con la misma confianza) se describen mediante un único objeto de estilo.
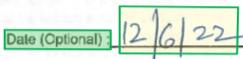
{
"confidence": 1,
"spans": [
{
"offset": 2402,
"length": 7
}
],
"isHandwritten": true
}
Idioma
Un elemento de idioma describe el idioma detectado para el contenido que se especifica mediante intervalos en la propiedad de contenido global. El idioma detectado se especifica mediante una etiqueta de idioma BCP-47 para indicar el idioma principal y la información opcional de script y región. Por ejemplo, el inglés y el chino tradicional se reconocen como "en" y zh-Hant, respectivamente. Las diferencias ortográficas regionales para el inglés del Reino Unido pueden provocar que el texto se detecte como en-GB. Los elementos de idioma no abarcan el texto sin un idioma dominante (por ejemplo, números).
Elementos semánticos
Nota:
Los elementos semánticos que se describen aquí se aplican a los modelos precompilados de Inteligencia de documentos. Los modelos personalizados pueden devolver diferentes representaciones de datos. Por ejemplo, la fecha y la hora devueltas por un modelo personalizado se pueden representar en un patrón que difiere del formato ISO 8601 estándar.
Documento
Un documento es una unidad semánticamente completa. Un archivo puede contener diversos documentos, como varios formularios fiscales dentro de un archivo PDF, o bien recibos diferentes dentro de una misma página. Sin embargo, el orden de los documentos dentro del archivo no afecta fundamentalmente a la información que transmite.
Nota:
Actualmente, Documento de inteligencia no admite varios documentos en una única página.
El tipo de documento describe los documentos que comparten un conjunto común de campos semánticos, que están representados en un esquema estructurado, independientemente de su plantilla visual o diseño. Por ejemplo, todos los documentos de tipo "recibo" pueden contener el nombre del comerciante, la fecha de la transacción y el total de transacciones, aunque los recibos de restaurantes y hoteles suelen diferir en su aspecto.
Un elemento de documento incluye la lista de campos reconocidos de entre los campos que especifica el esquema semántico del tipo de documento detectado:
Es posible extraer o inferir un campo de documento. Los campos extraídos se representan mediante el contenido extraído y, de manera opcional, su valor normalizado, en caso de que se pueda interpretar.
Un campo inferido no tiene propiedad de contenido y solo se representa a través de su valor.
Un campo de matriz no incluye ninguna propiedad de contenido. El contenido se puede concatenar desde el contenido de los elementos de matriz.
Los campos de objeto contienen una propiedad de contenido que especifica el contenido completo que representa el objeto y que puede ser un superconjunto de los subcampos extraídos.
El esquema semántico de un tipo de documento se describe mediante los campos que puede contener. Cada esquema de campo se especifica mediante su nombre canónico y tipo de valor. Los tipos de valor de campo incluyen tipos básicos (por ejemplo, cadena), compuestos (por ejemplo, dirección) y estructurados (por ejemplo, matriz, objeto). El tipo de valor de campo también especifica la normalización semántica que se realizar a fin de convertir el contenido detectado en una representación de normalización. La normalización puede ser dependiente de la configuración regional.
Tipos básicos
| Tipo de valor de campo | Descripción | Representación normalizada | Ejemplo (contenido de campo : valor >) |
|---|---|---|---|
| string | Texto sin formato | Igual que el contenido | MerchantName: "Contoso" → "Contoso" |
| fecha | Fecha | ISO 8601 - YYYY-MM-DD | InvoiceDate: "7/5/2022" → "2022-05-07" |
| time | Time | ISO 8601 - hh:mm:ss | TransactionTime: "9:45 PM" → "21:45:00" |
| phoneNumber | Número de teléfono | E.164 - +{CountryCode}{SubscriberNumber} | WorkPhone: "(800) 555-7676" → "+18005557676" |
| countryRegion | País o región | ISO 3166-1 alpha-3 | CountryRegion: "Estados Unidos" → "EE. UU." |
| selectionMark | Está activado | "firmado" o "sin firmar" | AcceptEula: ☑ → "seleccionado" |
| firma | Está firmado | Igual que el contenido | LendeeSignature: {signature} → "firmada" |
| number | Número de punto flotante | Número de punto flotante | Cantidad: "1.20" → 1.2 |
| integer | Número entero | Número con signo de 64 bits | Recuento: "123" → 123 |
| boolean | Valor booleano | true/false | IsStatutoryEmployee: ☑ → true |
Tipos compuestos
Moneda: importe de moneda con unidad monetaria opcional. Un valor, por ejemplo:
InvoiceTotal: $123.45{ "amount": 123.45, "currencySymbol": "$" }Dirección: dirección analizada. Por ejemplo:
ShipToAddress: 123 Main St., Redmond, WA 98052{ "poBox": "PO Box 12", "houseNumber": "123", "streetName": "Main St.", "city": "Redmond", "state": "WA", "postalCode": "98052", "countryRegion": "USA", "streetAddress": "123 Main St." }
Tipos estructurados
Matriz: lista de campos del mismo tipo
"Items": { "type": "array", "valueArray": [ ] }Objeto: lista con nombre de subcampos de tipos potencialmente diferentes
"InvoiceTotal": { "type": "currency", "valueCurrency": { "currencySymbol": "$", "amount": 110 }, "content": "$110.00", "boundingRegions": [ { "pageNumber": 1, "polygon": [ 7.3842, 7.465, 7.9181, 7.465, 7.9181, 7.6089, 7.3842, 7.6089 ] } ], "confidence": 0.945, "spans": [ { "offset": 806, "length": 7 } ] }
Pasos siguientes
Pruebe a procesar sus propios formularios y documentos con Estudio del documento de inteligencia.
Complete el inicio rápido de Documento de inteligencia y empiece a crear una aplicación de procesamiento de documentos en el lenguaje de desarrollo que prefiera.