Crear una estrategia y arquitectura de alta disponibilidad para SharePoint Server
SE APLICA A: 2013 2016 2019 Subscription Edition
2013 2016 2019 Subscription Edition  SharePoint en Microsoft 365
SharePoint en Microsoft 365
Una estrategia de alta disponibilidad es un requisito importante para un entorno SharePoint Server de producción. Una estrategia de un extremo a otro incluye los procesos operativos, la gobernanza de la plataforma, la arquitectura y las soluciones técnicas. Este artículo se centra en los aspectos arquitectónicos y técnicos de alta disponibilidad. En la guía se explican los elementos de diseño específicos de SharePoint y las opciones técnicas que determinarán la estrategia de alta disponibilidad.
Nota:
La alta disponibilidad y la recuperación ante desastres no son lo mismo. Aunque existe un solapamiento en la planeación y las soluciones, son subconjuntos de continuidad empresarial. El objetivo de la alta disponibilidad es proporcionar resistencia dentro del centro de datos principal y tiempos de inactividad planeados. El objetivo de la recuperación ante desastres es permitir a una organización reanudar sus operaciones informáticas en un centro de datos secundario cuando se produce un desastre en el centro de datos principal a causa del cual la infraestructura queda inutilizable. Para más información sobre la recuperación ante desastres para SharePoint Server, vea Seleccionar una estrategia de recuperación ante desastres para SharePoint Server.
La alta disponibilidad se usa normalmente para describir la capacidad de un sistema de seguir funcionando y proporcionando recursos a sus usuarios cuando se produce un error en una o varias de las siguientes categorías en un dominio de errores: hardware, software o aplicación. El nivel de disponibilidad se expresa como medida del porcentaje de tiempo que un sistema está operativo de manera continuada para admitir funciones empresariales. El nivel requerido de disponibilidad varía entre las organizaciones. Aunque este requisito también puede variar entre unidades de negocio, un contrato de nivel de servicio es para toda la organización como una sola unidad. Desde la perspectiva de los usuarios, una granja de SharePoint está disponible cuando los usuarios pueden acceder a la granja y usar las características y servicios que deben tener para realizar su trabajo.
Una granja de servidores SharePoint de alta disponibilidad tiene los siguientes objetivos y características:
El diseño de la granja de servidores reduce los puntos de error potenciales. Puesto que es improbable que se puedan eliminar todos los puntos de error, la estrategia general debe abarcar cómo se debe responder en el evento de un error.
Los eventos de conmutación por error son ininterrumpidos y tienen un efecto mínimo en las actividades del usuario.
La granja de servidores continúa funcionando a una capacidad reducida en lugar de fallar completamente.
La granja de servidores es resistente. Los incidentes que afectan al servicio ocurren con poca frecuencia y, en caso de hacerlo, se llevan a cabo las acciones necesarias de forma puntual y eficaz.
Introducción
Antes de crear una arquitectura y estrategia realística y económica de alta disponibilidad para el entorno SharePoint, se deben definir y cuantificar los objetivos de disponibilidad. Estos objetivos reflejan en qué medida la organización depende de SharePoint Server y cómo una pérdida del servicio afectaría a las operaciones de la organización. El efecto de la pérdida del servicio depende de la naturaleza de la pérdida (total o parcial), así como de la duración de la misma.
Una estrategia de alta disponibilidad adecuada debe reflejar las necesidades específicas de la organización. Además, debe proporcionar un equilibrio óptimo entre los requisitos del negocio, los contratos de nivel de servicio de TI y la disponibilidad de soluciones técnicas, capacidades de soporte de TI y costes de infraestructura.
Una vez identificados los requisitos de disponibilidad de la organización, se puede empezar a crear un diseño y una estrategia de alta disponibilidad para reducir el riesgo de tiempos de inactividad y reducción de las operaciones. Los profesionales de TI que diseñan e implementan sistemas altamente disponibles usan los siguientes principios como guía para cumplir sus objetivos:
Eliminar los puntos de error individuales para cada dominio de error y para todo el sistema en cada nivel posible (sistema operativo, software y aplicación SharePoint).
Implementar sistemas muy rápidos de detección, aislamiento y resolución.
Las soluciones de alta disponibilidad son de ámbito amplio y proporcionan un conjunto de recursos compartidos en todo el sistema que se integran para proporcionar los servicios necesarios predefinidos. La solución usa diferentes combinaciones de hardware y software para minimizar el tiempo de inactividad y restaurar los servicios cuando el sistema o parte del sistema falla.
Una solución de tolerancia a errores se centra en el hardware y usa hardware especializado para detectar errores y conmutar de forma instantánea a un componente de hardware redundante. Este componente puede ser un procesador, una tarjeta de memoria, un sistema de alimentación, un subsistema E/S o un subsistema de almacenamiento. El conmutador a un componente redundante proporciona un alto nivel de servicio.
Un análisis de costos y beneficios de las soluciones de tolerancia a errores y de las soluciones de alta disponibilidad permite a las organizaciones crear una estrategia efectiva para cumplir los objetivos de disponibilidad de su granja de servidores SharePoint. Normalmente existen desventajas de costes entre ambas soluciones.
Un proceso que implemente la alta disponibilidad es una de las inversiones más caras para una granja de servidores SharePoint. A medida que aumenta el nivel de disponibilidad y el número de sistemas que se desean hacer altamente disponibles, también aumenta la complejidad y el coste de una solución de disponibilidad.
Los avances en la tecnología de virtualización permiten a las organizaciones usar equipos virtuales como repuestos fríos, templados o calientes. Los equipos virtuales pueden ser adecuados para proporcionar la misma funcionalidad. La virtualización puede proporcionar flexibilidad y rentabilidad. Sin embargo, debe verificarse que un equipo virtual tiene la capacidad para tratar la misma carga que el equipo físico al que va a reemplazar.
Creación de una arquitectura de granja de servidores que admita la alta disponibilidad
En la siguiente ilustración se muestra cómo distribuir y configurar diferentes partes de un entorno SharePoint para aumentar la disponibilidad en una granja de servidores. Este ejemplo también muestra cómo la redundancia permite solucionar dominios de error.
Nota:
El ejemplo no es completo. Por ejemplo, no muestra todos los dominios de error ni todo el hardware de tolerancia a errores.
Ejemplos de redundancia en una topología de granja para tratar puntos de error
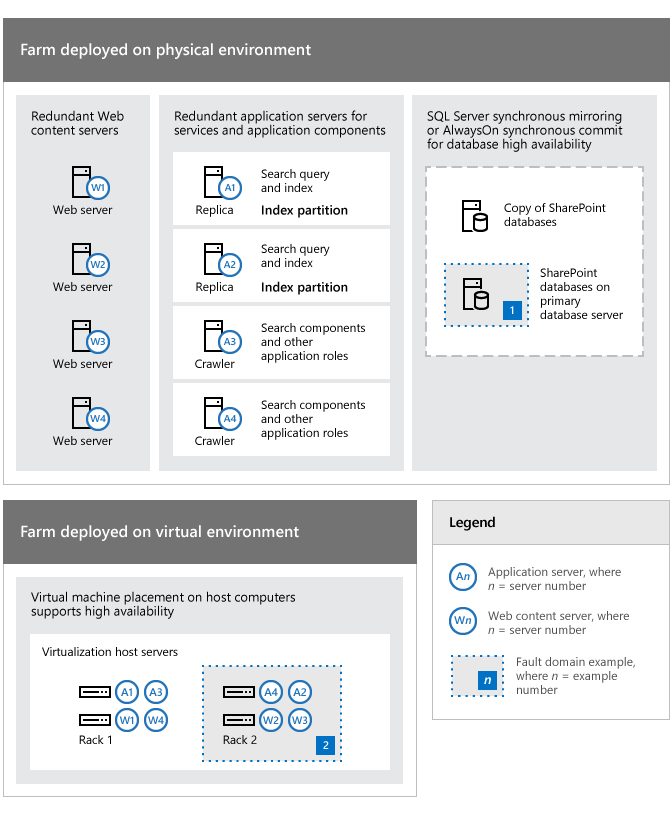
Con referencia a la topología de la ilustración anterior, tenga en cuenta lo siguiente:
Los servidores de la granja de este ejemplo pueden ser equipos físicos o máquinas virtuales que se implementan en servidores host Hyper-V. El principio de identificación y respuesta a puntos de error se aplica a ambos tipos de entorno.
Cuatro servidores (W1-W4) se dedican a servir contenido y esta redundancia incrementa la disponibilidad si se produce un error en uno o varios servidores. Este nivel de redundancia también permite a la granja de servidores continuar con las operaciones mientras se aplican actualizaciones de software.
Cuatro servidores de aplicaciones (A1-A4) incrementan la disponibilidad para los servicios de la granja de servidores y componentes de aplicación específicos, como la búsqueda. La búsqueda de roles y componentes es redundante.
Los servidores de bases de datos de la granja son redundantes y la alta disponibilidad de las bases de datos se puede lograr mediante la creación de reflejo de bases de datos y la agrupación en clústeres.
En un entorno virtual, las máquinas virtuales se colocan en servidores host Hyper-V independientes para eliminar un único punto de error. Este enfoque para la colocación de las máquinas virtuales sigue las instrucciones de prácticas recomendadas para la disponibilidad y el rendimiento.
El servidor de bases de datos principal (con la etiqueta 1) y el bastidor 2 (con la etiqueta 2), que contiene dos de los equipos host de virtualización, se identifican como dominios de error para mostrar cómo la granja de servidores y la infraestructura se pueden visualizar como una colección de dominios de error. Esto muestra cómo se puede realizar un análisis detallado del entorno para desarrollar una estrategia global y un análisis de costes y beneficios.
Otros roles y servicios de la granja de servidores
Nuestro ejemplo no incluye todos los roles, servicios y aplicaciones de servicios que se pueden ejecutar en una granja de servidores SharePoint concreta. No se puede usar un enfoque genérico de alta disponibilidad para todo en una granja de servidores de SharePoint. A continuación se enumeran algunas exclusiones importantes a la hora de usar un enfoque estándar de alta disponibilidad:
La caché distribuida requiere consideraciones especiales durante la conmutación por error. Para más información, vea Plan para el servicio de caché distribuido y Administrar el servicio de caché distribuida en SharePoint Server.
Para usar Flujo de trabajo de SharePoint se necesita Administrador de flujos de trabajo 1.0, actualización acumulativa 3. Configure el flujo de trabajo para SharePoint Server 2016 del mismo modo que para SharePoint Server 2013. Para obtener más información, vea Descripción de la actualización acumulativa 3 para Administrador de flujos de trabajo 1.0 y Configurar un flujo de trabajo de alta disponibilidad en Administrador de flujos de trabajo 1.0.
Nota:
La configuración de Flujo de trabajo para SharePoint Server 2016 no cambió desde SharePoint Server 2013. Necesita instalar Administrador de flujos de trabajo 1.0, actualización acumulativa 3.
Aunque las aplicaciones de servicio se pueden ejecutar en varios equipos, y se recomienda, algunas tienen requisitos de instalación y configuración únicos para la alta disponibilidad. La aplicación Perfil de usuario es un ejemplo conocido.
Uso de la tolerancia de errores en la solución de alta disponibilidad
Después de diseñar una arquitectura que soporta roles y cargas de trabajo de alta disponibilidad, se pueden usar componentes de tolerancia a errores para incrementar la disponibilidad. Las soluciones de tolerancia a errores están disponibles en la infraestructura, que incluye las bases de datos.
Una infraestructura de tolerancia a errores
La tolerancia a errores es altamente disponible para casi cualquier componente de hardware de la infraestructura de una granja de servidores SharePoint. Como parte del diseño de alta disponibilidad, se deben determinar las partes de la infraestructura que debe tener tolerancia a errores desde un punto de vista operativo y de costes. Aunque se pueden hacer cada parte tolerante a errores, no significa que tenga que hacerse.
Servidores de bases de datos y bases de datos de tolerancia a errores
Puesto que la plataforma de SharePoint y las cargas de trabajo de su aplicación dependen de la disponibilidad y confiabilidad de todas las bases de datos de SharePoint, las bases de datos de alta disponibilidad son un aspecto extremadamente importante de la estrategia de alta disponibilidad. Puede usar las siguientes características como soluciones de tolerancia a errores para servidores de bases de datos y bases de datos de SharePoint:
SQL Server clústeres de conmutación por error (Always On instancias de clúster de conmutación por error (FCI) en SQL Server 2014 con Service Pack 1 (SP1)) y SQL Server 2012
grupos de disponibilidad de Always On
Reflejo de base de datos SQL Server de alta disponibilidad
Acerca de Always On instancias de clúster de conmutación por error y grupos de disponibilidad de Always On
Un clúster de conmutación por error necesita un almacenamiento en disco compartido entre dos equipos. En una configuración de dos nodos, los equipos se configuran como activos o pasivos, lo que proporciona una instancia del nodo principal totalmente redundante. El nodo pasivo solo pasa a estar en línea si el nodo principal produce errores. El disco compartido solo se presenta en un equipo a la vez. Esta configuración normalmente necesita la mayor cantidad de hardware adicional. En SQL Server 2014 (SP1) y SQL Server 2012, este tipo de configuración de clúster es una instancia de clúster de conmutación por error de Always On y es una manera específica de instalar SQL Server. Debido a los requisitos de configuración, no se puede cambiar fácilmente una instalación estándar de SQL Server a una instancia de clúster de conmutación por error.
Un grupo de disponibilidad de Always On es una tecnología diferente en SQL Server 2014 (SP1) y SQL Server 2012 (considérelo descendiente de la creación de reflejo de la base de datos) que usa algunas características expuestas por clústeres de Windows. Pero no necesita almacenamiento de disco compartido, ni es necesario que los equipos de un grupo de disponibilidad tengan instalada una configuración especializada de SQL Server. Después de agregar un servidor de base de datos a un clúster de Windows, es bastante fácil habilitar Always On grupos de disponibilidad y, a continuación, configurar el grupo de disponibilidad que quiera.
En resumen, cualquier servidor que ejecute SQL Server 2014 (SP1) y SQL Server 2012 Enterprise Edition puede usar Always On grupos de disponibilidad uniéndose a un clúster y configurando el grupo de disponibilidad. Always On clústeres de conmutación por error requieren pasos especiales de hardware y configuración para configurar instancias de clúster de conmutación por error. Cada una de estas tecnologías tiene su uso para entornos específicos, y ambas son competidores complementarias. Para obtener más información sobre estas características, vea Soluciones de alta disponibilidad (SQL Server). Para obtener ayuda para decidir qué tecnología de disponibilidad SQL Server usar, consulte Continuidad empresarial y recuperación de bases de datos: SQL Server.
Importante
Puesto que cada opción de alta disponibilidad de SQL Server tiene sus propias características, ventajas y desventajas, un opción no es necesariamente mejor que la otra. Por ejemplo, en un escenario determinado que usa Always On grupos de disponibilidad, minimizar la pérdida de datos podría ser mejor que cualquier ganancia de rendimiento que logre Always On instancias de clúster de conmutación por error. Se debe elegir una solución de alta disponibilidad en función de las necesidades empresariales y de los requisitos de la infraestructura de TI.
Un factor determinante a la hora de seleccionar una opción de SQL Server para usar son las bases de datos de datos SharePoint. Es necesario comprender las características de las bases de datos SharePoint Server. Cada base de datos puede tener restricciones o requisitos específicos que determinarán la solución SQL Server de tolerancia a errores más apropiada y totalmente compatible con el entorno de producción. Se recomienda revisar los artículos siguientes:
Clústeres de conmutación por error de SQL Server
Los clústeres de conmutación por error admiten la disponibilidad para una instancia de SQL Server en SQL Server 2014 (SP1) o SQL Server 2012.
Un clúster de conmutación por error es una combinación de uno o más nodos o servidores y dos o más discos compartidos. Aunque una instancia de un clúster de conmutación por error aparece como un equipo único, la instancia proporciona la conmutación por error de un nodo a otro si el nodo actual deja de estar disponible. SharePoint Server se puede ejecutar en cualquier combinación de nodos activos y pasivos en un clúster compatible con SQL Server.
SharePoint Server hace referencia al clúster en conjunto. Por lo tanto, la conmutación por error es automática y directa desde el punto de vista de SharePoint Server.
Nota:
Cuando se produce una conmutación por error planeada o no planeada, se interrumpen las conexiones y deben establecerse de nuevo al pasar de un nodo de clúster a otro.
Para obtener información detallada sobre SQL Server clústeres de conmutación por error, consulte Always On Instancias de clúster de conmutación por error (SQL Server).
SQL Server Always On grupos de disponibilidad y SQL Server creación de reflejo de la base de datos
La ventaja clave de SQL Server Always On grupos de disponibilidad y SQL Server creación de reflejo de la base de datos es que proporcionan redundancia de datos completa o casi completa en función de cómo los configure para el procesamiento de transacciones. Además de minimizar la pérdida de datos, la conmutación por error automática minimiza el tiempo de inactividad de las bases de datos de producción.
Importante
Aunque SQL Server 2016, SQL Server 2014 (SP1) y SQL Server 2012 admiten la creación de reflejo de la base de datos, está previsto que esta característica esté en desuso. Se recomienda evitar el uso de esta característica en el nuevo trabajo de desarrollo. Planee cambiar las aplicaciones que actualmente usan esta característica. Use Always On grupos de disponibilidad en su lugar.
grupos de disponibilidad de Always On
La característica SQL Server Always On grupos de disponibilidad es una solución de alta disponibilidad y recuperación ante desastres que proporciona una alternativa de nivel empresarial a la creación de reflejo de la base de datos. Always On grupos de disponibilidad admite un entorno de conmutación por error para una o varias bases de datos de usuario contenidas en una colección definida por el usuario. Esta colección, un grupo de disponibilidad, está formada por los componentes siguientes:
Replicas, que son un conjunto discreto de bases de datos del usuario denominadas bases de datos de disponibilidad que se tratan como una sola unidad. Un grupo de disponibilidad admite una réplica principal y hasta cuatro réplicas secundarias.
Una instancia específica de SQL Server para hospedar cada réplica y mantener una copia local de cada base de datos que pertenece al grupo de disponibilidad.
Cuando un grupo de disponibilidad se conmuta por error en una instancia de destino o un servidor de destino, todas las bases de datos del grupo también se conmutan por error. Dado que SQL Server 2014 (SP1) y SQL Server 2012 pueden hospedar varios grupos de disponibilidad en un único servidor, puede configurar Always On para conmutar por error a instancias de SQL Server en servidores diferentes. Esto reduce la necesidad de usar servidores de alto rendimiento inactivos en espera para administrar la carga total del servidor principal, que es una de las muchas ventajas de los grupos de disponibilidad.
Nota:
Las incidencias de las bases de datos, como una base de datos que se convierte en sospechosa a causa de la pérdida de un archivo de datos, la eliminación de una base de datos o la corrupción de un registro de transacción, no causan una conmutación por error.
Para obtener más información sobre las ventajas de los grupos de disponibilidad de Always On y una introducción a la terminología de Always On grupos de disponibilidad, consulte Always On grupos de disponibilidad (SQL Server).
Creación de reflejos de base de datos
Nota:
Aunque SQL Server 2016, SQL Server 2014 (SP1) y SQL Server 2012 admiten la creación de reflejo de la base de datos, está previsto que esta característica esté en desuso. Se recomienda evitar el uso de esta característica en el nuevo trabajo de desarrollo. Planee cambiar las aplicaciones que actualmente usan esta característica. Use Always On grupos de disponibilidad en su lugar.
La creación de reflejos de base de datos proporciona redundancia de base de datos al conservar una copia reflejada de las bases de datos en el servidor de bases de datos principal. La creación de reflejos se implementa por base de datos y solo funciona con bases de datos que usan el modelo de recuperación completa.
Nota:
Existen dos modos de funcionamiento de la creación de reflejos. Uno de ellos, el modo de seguridad alta, admite la operación sincrónica. En el modo de seguridad alta, cuando se inicia una sesión, el servidor reflejado sincroniza la base de datos reflejada y la base de datos principal lo más rápido posible. Una vez sincronizadas las bases de datos, se escribe una transacción en el registro del servidor secundario y se vuelve a reproducir. (El control vuelve al servidor principal una vez protegida la transacción.) El otro modo de creación de reflejos es de rendimiento alto y utiliza la operación asincrónica para reducir la latencia de la transacción, con el coste de una mayor pérdida de datos.
Para la creación de reflejos de alta disponibilidad en una granja de servidores SharePoint, se debe usar el modo de seguridad alta con conmutación por error automática. La creación de reflejos de seguridad alta requiere tres instancias de servidor: una principal, un reflejo y un testigo. El servidor testigo habilita SQL Server para que conmute por error automáticamente del servidor principal al servidor reflejado. La conmutación por error a la base de datos reflejada tarda normalmente unos segundos.
Para obtener información general sobre la creación de reflejos de bases de datos, vea Creación de reflejo de la base de datos.
Importante
No se pueden crear reflejos de las bases de datos configuradas para usar el proveedor de almacén BLOB remoto FILESTREAM de SQL Server.
Comparación de la disponibilidad de las bases de datos y las estrategias de recuperación para una única granja de servidores
La elección de una tecnología SQL Server para la alta disponibilidad y la recuperación ante desastres debería basarse en los objetivos de negocio de la organización para el Objetivo de punto de recuperación (RPO) y el Objetivo de tiempo de recuperación (RTO). Aunque RPO y RTO se asocian normalmente con la recuperación ante desastres, algunos eventos de error se encuentran fuera del ámbito de un desastre pero requieren recuperación desde un medio de copia de seguridad local en la base de datos principal.
Importante
En función de la base de datos específica, las distintas bases de datos de SharePoint Server solo admiten opciones específica de alta disponibilidad de SQL Server. Para más información, vea Compatibilidad de alta disponibilidad y opciones de recuperación ante desastres para bases de datos de SharePoint.
En la tabla siguiente se ofrece una comparación general de los resultados RPO y RTO que las soluciones de SQL Server disponibles logran.
Nota:
Los tiempos en la tabla siguiente son para comparar las opciones de bases de datos. En la práctica, todos los tiempos dependen de la carga de trabajo, el volumen de datos y los procedimientos de conmutación por error.
Comparación de RPO y RTO en función de la tecnología de bases de datos
| Solución SQL Server | Pérdida de datos potencial (RPO) | Tiempo de recuperación potencial (RTO). | Conmutación por error automática | Secundarias legibles Nota: SharePoint Server admite réplicas secundarias legibles para el uso en tiempo de ejecución. Para obtener más información, vea Actualización acumulativa de Office 2013 para abril de 2014 y Ejecución de una granja de servidores que usa bases de datos de solo lectura en SharePoint Server. |
|---|---|---|---|---|
| Always On grupo de disponibilidad (confirmación sincrónica) |
Cero |
Segundos |
Sí |
0 - 2 |
| Always On grupo de disponibilidad (confirmación asincrónica) |
Segundos |
Minutos |
No |
0 - 4 |
| Always On instancia de clúster de conmutación por error |
No se aplica Una instancia de clúster de conmutación por error por sí sola no proporciona protección de datos. La cantidad de pérdida de datos depende de la implementación del sistema de almacenamiento. |
Segundos a minutos |
Sí |
No se aplica |
| Creación de reflejos de base de datos: seguridad alta (modo sincrónico + servidor testigo) |
Cero |
Segundos |
Sí |
No se aplica |
| Creación de reflejos de base de datos: rendimiento alto (modo asincrónico) |
Segundos |
Minutos |
No |
No se aplica |
| Copia de seguridad, copia, restauración. |
Horas o cero si se puede obtener acceso al final del registro después del error. |
Horas a días |
No |
No durante una restauración |
Comparación de SQL Server clúster, Always On grupo de disponibilidad y reflejo de la base de datos
| Proceso | Clúster de conmutación por error de SQL Server | SQL Server 2014 (SP1) y SQL Server 2012 Always On grupo de disponibilidad | Reflejo de alta disponibilidad de SQL Server |
|---|---|---|---|
| Tiempo de la conmutación por error |
El miembro del clúster toma el control casi inmediatamente después del error. Se produce un retardo mientras el nodo del clúster se pone en funcionamiento. |
La réplica toma el control casi inmediatamente después del error. Se produce un retardo mientras la réplica secundaria se pone en funcionamiento. |
El reflejo toma el control tan pronto como se procesa la cola rehecha. |
| Coherencia de las transacciones |
Sí |
Sí |
Sí |
| Simultaneidad de las transacciones |
Sí |
Sí |
Sí |
| Tiempo de recuperación |
Menos tiempo de recuperación que un grupo de disponibilidad. |
Mayor tiempo de recuperación que un clúster de conmutación por error, pero más rápido que una solución reflejada. |
Tiempo de recuperación ligeramente mayor que un clúster o un grupo de disponibilidad. |
| Pasos necesarios para la conmutación por error |
Los nodos de la base de datos detectan un error automáticamente. SharePoint Server hace referencia al clúster para que la conmutación por error sea directa y automática. |
La escucha del grupo de disponibilidad detecta un error automáticamente y la conmutación por error es directa y automática. |
La base de datos detecta un error automáticamente. SharePoint Server identifica la ubicación del reflejo si este se configuró correctamente para que la conmutación por error sea automática. |
| Protección frente a errores de almacenamiento |
El clúster de conmutación por error por sí solo no proporciona protección de datos. La cantidad de pérdida de datos depende de la implementación del sistema de almacenamiento. Por ejemplo, un entorno SAN tiene componentes redundantes como múltiples rutas de archivo, RAID y reservas activas. |
Protege frente a errores de almacenamiento ya que la réplica principal escribe en los discos locales de las réplicas secundarias. |
Protege frente a errores de almacenamiento ya que tanto el servidor principal como el de la base de datos reflejada escriben en discos locales. |
| Tipos de almacenamiento admitidos |
Requiere almacenamiento compartido, que es más caro que el almacenamiento dedicado. |
Puede usar soluciones de almacenamiento conectadas directamente más económicas. |
Puede usar almacenamiento conectado directamente más económico. |
| Requisitos de ubicación |
Los miembros del clúster deben encontrarse en la misma subred. Note: Este no es el caso para SQL Server 2014 (SP1) y SQL Server 2012. |
Las réplicas pueden encontrarse en diferentes subredes si la latencia no causa problemas de rendimiento. |
Los servidores principal, reflejado y testigo deben estar en la misma LAN (ida y vuelta con una latencia de hasta 1 milisegundo). |
| Modelo de recuperación |
Se recomienda el modelo de recuperación completa de SQL Server. Se puede usar el modelo de recuperación simple de SQL Server. Sin embargo, el único punto de recuperación disponible si se pierde el clúster será la última copia de seguridad completa. |
Requiere el modelo de recuperación completa de SQL Server 2012 y SQL Server 2014 (SP1). |
Requiere el modelo de recuperación completa de SQL Server. |
| Sobrecarga de rendimiento |
Durante una conmutación por error se puede producir alguna disminución del rendimiento. El servidor no estará disponible durante la conmutación por error y las conexiones se interrumpen y se vuelven a establecer en el nuevo nodo activo. |
Always On grupos de disponibilidad presentan latencia transaccional debido a la confirmación sincrónica en las réplicas secundarias. La cantidad de latencia depende del número de réplicas secundarias que se deben sincronizar. La sobrecarga de la memoria y del procesador es mayor que en los clústeres, pero menor que en la creación de reflejos. |
La creación de reflejos de alta disponibilidad introduce la latencia transaccional, ya que es sincrónica. También requiere una sobrecarga de la memoria y del procesador adicional. |
| Sobrecarga de operaciones |
Se configuran y mantienen en el nivel del servidor. |
La sobrecarga operativa es mayor que en los clústeres y la creación de reflejos. Always On requiere sobrecarga en el nivel del servidor de base de datos de SQL Server además del nivel de Windows Server. Nota: Los objetos de nivel de servidor (como los trabajos de agente y los inicios de sesión) necesitan mantenerse de forma manual. Si se agregan bases de datos de contenido, se deben agregar a un grupo de disponibilidad y, después, sincronizar la réplica principal con las réplicas secundarias. Un entorno de granja de servidores SharePoint requiere varios pasos de configuración para asegurarse de que la cadena de conexión de SharePoint Server está asociada correctamente con el nombre de la escucha del grupo de disponibilidad. |
La sobrecarga de operaciones es mayor que en los clústeres. Se debe configurar y mantener para todas las bases de datos. La reconfiguración después de la conmutación por error es manual. Nota: Los objetos de nivel de servidor (como los trabajos de agente y los inicios de sesión) necesitan mantenerse de forma manual. Si se agregan bases de datos de contenido, se deben agregar al principal y después sincronizarlas con el principal del reflejo. |
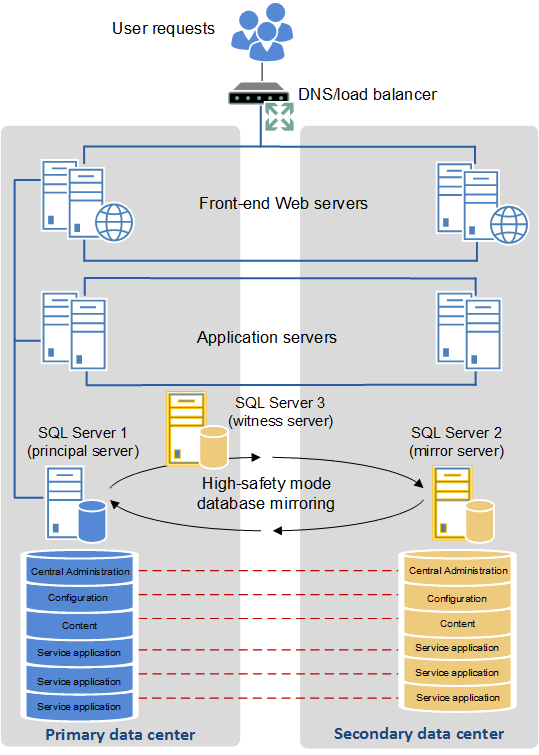
Configuración de dos centros de datos como una única granja de servidores (granja de servidores "expandida") para proporcionar una alta disponibilidad
Algunas empresas tienen centros de datos ubicados cerca los unos de los otros, conectados mediante cables de fibra óptica de banda ancha. Si este entorno está disponible, es posible configurar ambos centros de datos como una sola granja de servidores. Esta topología de granja de servidores distribuida se denomina granja de servidores "expandida".
Para que una arquitectura de granja de servidores expandida funcione como solución de alta disponibilidad compatible, se deben cumplir los siguientes requisitos previos:
Hay una latencia dentro de la granja de servidores de gran constancia, de <1ms (unidireccional), el 99,9% del tiempo durante un período de diez minutos. (La latencia dentro de la granja se define comúnmente como la latencia entre los servidores web front end y los servidores de bases de datos.)
La velocidad de ancho de banda debe ser de al menos 1 gigabit por segundo.
Para proporcionar tolerancia a errores en una granja de servidores expandida, usa las instrucciones de prácticas recomendadas estándar para configurar aplicaciones de servicio y bases de datos redundantes.
En la ilustración siguiente se muestra una granja de servidores expandida.
Granja de servidores expandida
Incorporación de operaciones de copia de seguridad y de restauración en una estrategia de alta disponibilidad
La estrategia de alta disponibilidad debe incluir las operaciones de copia de seguridad y de restauración apropiadas para asegurar que la granja de servidores es resistente. En el caso de un incidente, como un error del medio o del usuario, se debe poder restaurar la parte afectada del entorno o de los datos de la granja de servidores de forma inmediata. Una solución de copia de seguridad y de restauración efectiva debe permitir el cumplimiento de los objetivos de tiempo de recuperación (RTO) y los objetivos de recuperación potencial (RPO) definidos.
Vea también
Conceptos
Conceptos de alta disponibilidad y recuperación ante desastres en SharePoint Server
Seleccionar una estrategia de recuperación ante desastres para SharePoint Server