Opciones de almacenamiento de datos (Creación de aplicaciones en la nube reales con Azure)
por Rick Anderson, Tom Dykstra
Descargar proyecto Fix It o Descargar libro electrónico
El libro electrónico Creación de aplicaciones en la nube reales con Azure se basa en una presentación desarrollada por Scott Guthrie. Explica 13 patrones y prácticas que pueden ayudarle a tener éxito en el desarrollo de aplicaciones web para la nube. Para obtener información sobre el libro electrónico, consulte el primer capítulo.
La mayoría de las personas están acostumbradas a las bases de datos relacionales y tienden a pasar por alto otras opciones de almacenamiento de datos cuando diseñan una aplicación en la nube. El resultado puede ser un rendimiento poco óptimo, gastos elevados o peor, ya que las bases de datos NoSQL (no relacionales) pueden controlar algunas tareas de forma más eficaz que las bases de datos relacionales. Cuando los clientes nos solicitan ayuda para resolver un problema crítico de almacenamiento de datos, suele deberse a que tienen una base de datos relacional en la que una de las opciones de NoSQL hubiera funcionado mejor. En esas situaciones, el cliente habría estado mejor si hubiera implementado la solución NoSQL antes de implementar la aplicación en producción.
Por otro lado, también sería un error suponer que una base de datos NoSQL puede hacer todo bien o lo suficientemente bien. No hay una única mejor opción de administración de datos para todas las tareas de almacenamiento de datos; las diferentes soluciones de administración de datos están optimizadas para diferentes tareas. La mayoría de las aplicaciones en la nube del mundo real tienen una variedad de requisitos de almacenamiento de datos y a menudo se sirven mejor mediante una combinación de varias soluciones de almacenamiento de datos.
El propósito de este capítulo es darle un sentido más amplio de las opciones de almacenamiento de datos disponibles para una aplicación en la nube y algunas instrucciones básicas sobre cómo elegir las que se ajustan a su escenario. Es mejor tener en cuenta las opciones disponibles y pensar en sus puntos fuertes y débiles antes de desarrollar una aplicación. Cambiar las opciones de almacenamiento de datos en una aplicación de producción puede ser extremadamente difícil, como tener que cambiar el motor de un avión mientras este está en vuelo.
Opciones de almacenamiento de datos en Azure
La nube facilita el uso de una variedad de almacenes de datos relacionales y NoSQL. Estas son algunas de las plataformas de almacenamiento de datos que puede usar en Azure.
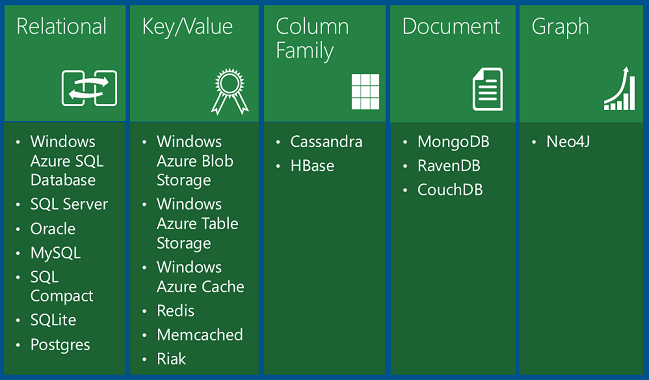
En la tabla se muestran cuatro tipos de bases de datos NoSQL:
Las bases de datos clave-valor almacenan un único objeto serializado para cada valor de clave. Se recomiendan para almacenar grandes volúmenes de datos donde se desee obtener un elemento para un valor de clave determinado valor de clave y no tiene que realizar consultas basándose en otras propiedades del elemento.
Azure Blob Storage es una base de datos clave-valor que funciona como el almacenamiento de archivos en la nube, con valores de clave que corresponden a nombres de carpeta y archivo. Puede recuperar un archivo mediante su carpeta y nombre de archivo, no buscando valores en el contenido del archivo.
Azure Table Storage también es una base de datos clave-valor. Cada valor se denomina una entidad (similar a una fila, identificada por una clave de partición y una clave de fila) y contiene varias propiedades (similares a las columnas, pero no todas las entidades de una tabla tienen que compartir las mismas columnas). Realizar consultas en columnas distintas de la clave es extremadamente ineficaz y debe evitarse. Por ejemplo, puede almacenar datos de perfil de usuario con una partición que almacena información sobre un solo usuario. Puede almacenar datos como el nombre de usuario, el hash de contraseña, la fecha de nacimiento, etc., en propiedades independientes de una entidad o en entidades independientes en la misma partición. Pero no querrá hacer una consulta de todos los usuarios con un intervalo determinado de fechas de nacimiento y no puede ejecutar una consulta de combinación entre la tabla de perfil y otra tabla. Table Storage es más escalable y menos costoso que una base de datos relacional, pero no habilita consultas complejas ni combinaciones.
Documentdatabases son bases de datos clave-valor en las que los valores son documentos. "Documento" aquí no se usa en el sentido de un documento de Word o Excel, sino que significa una colección de campos y valores con nombre, cualquiera de los cuales podría ser un documento secundario. Por ejemplo, en una tabla de historial de pedidos, un documento de pedido podría tener campos de número de pedido, fecha de pedido y cliente; y el campo de cliente puede tener los campos de nombre y dirección. La base de datos codifica los datos de campo en un formato como XML, YAML, JSON o BSON; o puede usar texto sin formato. Una característica que establece las bases de datos de documentos aparte de las bases de datos clave-valor es la capacidad de realizar consultas en campos que no son de clave y definir índices secundarios para que las consultas sean más eficaces. Esta capacidad hace que una base de datos de documentos sea más adecuada para las aplicaciones que necesitan recuperar datos en función de criterios más complejos que el valor de la clave de documento. Por ejemplo, en una base de datos de documentos del historial de pedidos de ventas, podría realizar consultas en varios campos, como el identificador de producto, el identificador de cliente, el nombre del cliente, etc. MongoDB es una base de datos de documentos popular.
Las bases de datos de familia de columnas son almacenes de datos clave-valor que permiten estructurar el almacenamiento de datos en colecciones de columnas relacionadas denominadas familias de columnas. Por ejemplo, una base de datos de un censo podría tener un grupo de columnas para el nombre de una persona (primer nombre, segundo nombre, apellido), un grupo para la dirección de la persona y un grupo para la información de perfil de la persona (fecha de nacimiento, género, etc.). Después, la base de datos puede almacenar cada familia de columnas en una partición independiente y mantener todos los datos de una persona relacionados con la misma clave. Después, puede leer toda la información del perfil sin tener que leer toda la información de nombre y dirección. Cassandra es una base de datos de familia de columnas popular.
Las bases de datos de grafos almacenan la información como una colección de objetos y relaciones. El propósito de una base de datos de grafos es permitir que una aplicación realice consultas de forma eficaz que atraviesan la red de objetos y las relaciones entre ellos. Por ejemplo, los objetos pueden ser empleados en una base de datos de recursos humanos y es posible que desee facilitar consultas como "buscar a todos los empleados que trabajan directa o indirectamente para Scott". Neo4j es una base de datos de grafos popular.
En comparación con las bases de datos relacionales, las opciones de NoSQL ofrecen una escalabilidad y una rentabilidad mucho mayor para el almacenamiento y el análisis de datos no estructurados. El inconveniente es que no proporcionan las funcionalidades enriquecidas de consulta e integridad de datos sólidas de las bases de datos relacionales. NoSQL funcionaría bien para los datos de registro de IIS, que implica un gran volumen sin necesidad de consultas de combinación. NoSQL no funcionaría tan bien para las transacciones bancarias, que requieren integridad de datos absoluta e implica muchas relaciones con otros datos relacionados con la cuenta.
También hay una categoría más reciente de la plataforma de base de datos denominada NewSQL que combina la escalabilidad de una base de datos NoSQL con la capacidad de consulta y la integridad transaccional de una base de datos relacional. Las bases de datos NewSQL están diseñadas para el almacenamiento distribuido y el procesamiento de consultas, que a menudo resulta difícil de implementar en bases de datos "OldSQL". NuoDB es un ejemplo de una base de datos NewSQL que se puede usar en Azure.
Hadoop y MapReduce
Los grandes volúmenes de datos que puede almacenar en bases de datos NoSQL pueden ser difíciles de analizar de forma eficaz y oportuna. Para ello, puede usar un marco como Hadoop que implemente la funcionalidad MapReduce. Básicamente, lo que hace un proceso de MapReduce es lo siguiente:
- Limita el tamaño de los datos que se deben procesar seleccionando del almacén de datos solo los datos que realmente necesita analizar. Por ejemplo, quiere conocer la composición de la base de usuarios por año de nacimiento, por lo que solo seleccionará los años de nacimiento del almacén de datos de perfil de usuario.
- Divida los datos en partes y envíelos a diferentes equipos para su procesamiento. El equipo A calcula el número de personas con fechas de 1950 a 1959, el equipo B calcula de 1960 a 1969, etc. Este grupo de equipos se denomina Clúster de Hadoop.
- Coloque los resultados de cada parte de nuevo juntos después de que se realice el procesamiento en las partes. Ahora tiene una lista relativamente corta de cuántas personas hay para cada año de nacimiento y la tarea de calcular porcentajes en esta lista general es manejable.
En Azure, HDInsight le permite procesar, analizar y obtener nuevas conclusiones de macrodatos mediante la tecnología de Hadoop. Por ejemplo, puede usarlo para analizar los registros del servidor web:
Habilite el registro del servidor web en la cuenta de almacenamiento. Esto configura Azure para escribir registros en Blob service para cada solicitud HTTP a la aplicación. Blob service es básicamente un almacenamiento de archivos en la nube y se integra perfectamente con HDInsight.

A medida que la aplicación obtiene tráfico, los registros de IIS del servidor web se escriben en Blob Storage.

En el portal, haga clic en Nuevo - Data Services - HDInsight - Creación rápida y especifique un nombre de clúster de HDInsight, un tamaño de clúster (número de nodos de datos del clúster de HDInsight) y un nombre de usuario y una contraseña para el clúster de HDInsight.

Ahora puede configurar trabajos de MapReduce para analizar los registros y obtener respuestas a preguntas como:
- ¿Qué horas del día obtiene mi aplicación la mayor y la menor cantidad de tráfico?
- ¿De qué países procede el tráfico?
- ¿Cuál es el promedio de ingresos en el vecindario de las áreas de las que proviene mi tráfico? (Hay un conjunto de datos público que le proporciona ingresos en el vecindario por dirección IP y puede hacer coincidir esto con la dirección IP en los registros del servidor web).
- ¿Cómo se correlacionan los ingresos en el vecindario con páginas o productos específicos en el sitio?
A continuación, podría usar las respuestas a preguntas como estas para dirigir anuncios en función de la probabilidad de que un cliente esté interesado o probablemente esté interesado en comprar un producto determinado.
Como se explica en el capítulo Automatizar todo, la mayoría de las funciones que puede realizar en el portal se pueden automatizar, y eso incluye la configuración y ejecución de trabajos de análisis de HDInsight. Un script típico de HDInsight puede contener los pasos siguientes:
- Aprovisione un clúster de HDInsight y vincúlelo a la cuenta de almacenamiento para la entrada de Blob Storage.
- Cargue los archivos ejecutables del trabajo de MapReduce (archivos .jar o .exe) en el clúster de HDInsight.
- Envíe un MapReduce que almacene los datos de salida en Blob Storage.
- Espere a que el trabajo se complete.
- Elimine el clúster de HDInsight.
- Acceda a la salida desde Blob Storage.
Al ejecutar un script que hace todo esto, se minimiza la cantidad de tiempo que se aprovisiona el clúster de HDInsight, lo que minimiza los costos.
Plataforma como servicio (PaaS) frente a Infraestructura como servicio (IaaS)
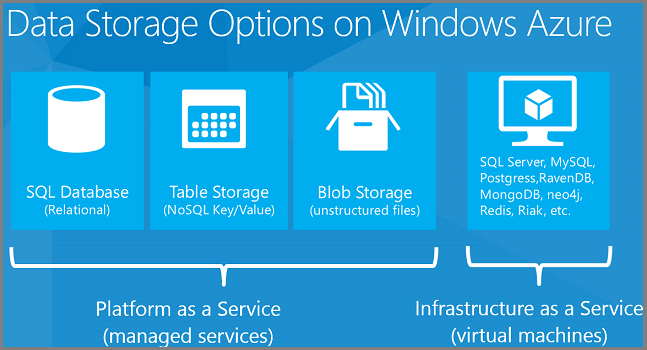
Las opciones de almacenamiento de datos enumeradas anteriormente incluyen soluciones de plataforma como servicio (PaaS) e infraestructura como servicio (IaaS). PaaS significa que administramos la infraestructura de hardware y software y solo usamos el servicio. SQL Database es una característica PaaS de Azure. Pide bases de datos y, en segundo plano, Azure configura las máquinas virtuales y configura las bases de datos en ellas. No tiene acceso directo a las máquinas virtuales y no tiene que administrarlas. IaaS significa que configura y administra las máquinas virtuales que se ejecutan en nuestra infraestructura de centro de datos y coloca lo que quiera en ellas. Proporcionamos una galería de imágenes de máquina virtual preconfiguradas para configuraciones comunes de máquinas virtuales. Por ejemplo, puede instalar imágenes de máquina virtual preconfiguradas para Windows Server 2008, Windows Server 2012, BizTalk Server, Oracle WebLogic Server, Oracle Database, etc.
Entre las soluciones de datos de PaaS que ofrece Azure se incluyen:
- Azure SQL Database (anteriormente conocido como SQL Azure). Una base de datos relacional en la nube basada en SQL Server.
- Azure Table Storage. Una base de datos NoSQL de clave-valor.
- Azure Blob Storage. Almacenamiento de archivos en la nube.
En el caso de IaaS, puede ejecutar cualquier cosa que pueda cargar en una máquina virtual, por ejemplo:
- Bases de datos relacionales como SQL Server, Oracle, MySQL, SQL Compact, SQLite o Postgres.
- Almacenes de datos de clave-valor como Memcached, Redis, Cassandra y Riak.
- Almacenes de datos de columna como HBase.
- Bases de datos de documentos como MongoDB, RavenDB y CouchDB.
- Bases de datos de grafos como Neo4j.
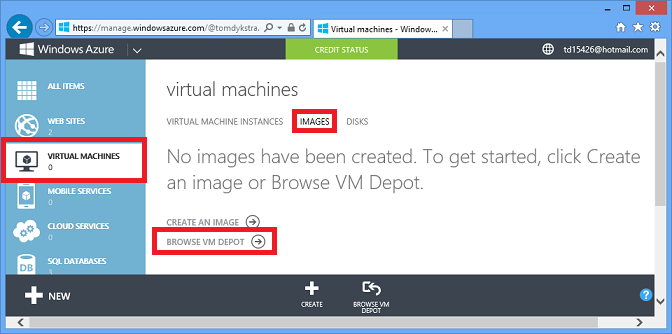
La opción IaaS ofrece opciones de almacenamiento de datos casi ilimitadas y muchas de ellas son especialmente fáciles de usar porque puede crear máquinas virtuales mediante imágenes preconfiguradas. Por ejemplo, en el portal de administración, vaya a Máquinas virtuales, haga clic en la pestaña Imágenes y haga clic en Examinar VM Depot.
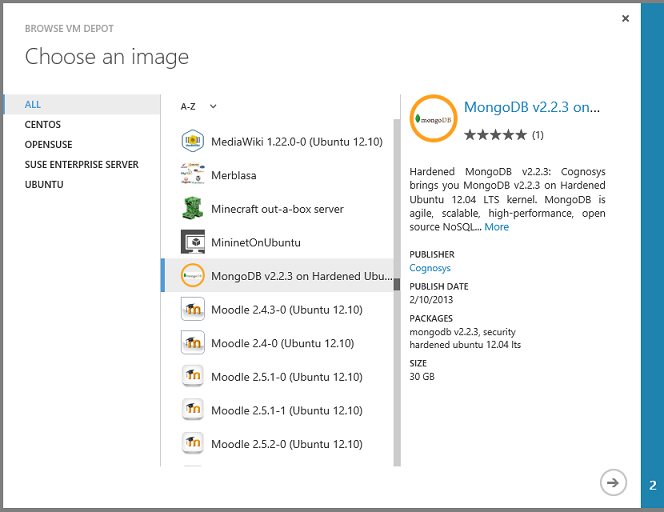
A continuación, verá una lista de cientos de imágenes de máquina virtual preconfiguradas y puede crear una máquina virtual a partir de una imagen que tenga preinstalado un sistema de administración de bases de datos, como MongoDB, Neo4J, Redis, Cassandra o CouchDB:
Azure hace que las opciones de almacenamiento de datos de IaaS sean lo más fáciles de usar posible, pero las ofertas de PaaS tienen muchas ventajas que les hacen más rentables y prácticas para muchos escenarios:
- No tiene que crear máquinas virtuales, solo tiene que usar el portal o un script para configurar un almacén de datos. Si desea un almacén de datos de 200 terabytes, puede hacer clic en un botón o ejecutar un comando y, en segundos, está listo para su uso.
- No tiene que administrar ni aplicar revisiones a las máquinas virtuales usadas por el servicio; Microsoft lo hace automáticamente. - No tiene que preocuparse por configurar la infraestructura para el escalado o la alta disponibilidad; Microsoft controla todo eso por usted.
- No tiene que comprar licencias; las tarifas de licencia se incluyen en las tarifas de servicio.
- Solo paga por lo que usa.
Las opciones de almacenamiento de datos PaaS en Azure incluyen ofertas de proveedores de terceros.
Elegir una opción de almacenamiento de datos
Ningún enfoque es adecuado para todos los escenarios. Si alguien dice que esta tecnología es la respuesta, lo primero que se debe preguntar es "¿Cuál es la pregunta?", porque las diferentes soluciones están optimizadas para diferentes cosas. Hay ventajas definitivas para el modelo relacional; es por eso que ha estado por aquí por tanto tiempo. Pero también hay desventajas de SQL que se pueden solucionar con una solución NoSQL.
A menudo, lo que vemos que funciona mejor es un enfoque compuesto, donde se usa SQL y NoSQL en una única solución. Incluso cuando las personas dicen que están adoptando NoSQL, si profundiza en lo que están haciendo, a menudo encuentra que usan varios marcos NoSQL diferentes: usan CouchDB, Redisy Riak para diferentes cosas. Incluso Facebook, que usa NoSQL ampliamente, usa diferentes marcos NoSQL para diferentes partes del servicio. La flexibilidad de combinar los enfoques de almacenamiento de datos es uno de los aspectos agradables sobre la nube, ya que es fácil usar varias soluciones de datos e integrarlas en una sola aplicación.
Estas son algunas preguntas que debe tener en cuenta al elegir un enfoque:
| Semántica de datos | - ¿Cuál es la semántica de acceso a datos y almacenamiento de datos principal (almacena datos relacionales o no estructurados)? Los datos no estructurados, como los archivos multimedia, se ajustan mejor a Blob Storage; una colección de datos relacionados, como productos, inventarios, proveedores, pedidos de clientes, etc., encaja mejor en una base de datos relacional. |
|---|---|
| Compatibilidad con consultas | - ¿Qué tan fácil es consultar los datos? - ¿Qué tipos de preguntas se pueden formular de forma eficaz? Los almacenes de datos clave-valor son muy buenos para obtener una sola fila cuando se proporciona una clave-valor, pero no tan buenos para las consultas complejas. Para un almacén de datos de perfil de usuario en el que siempre obtiene los datos de un usuario determinado, un almacén de datos clave-valor podría funcionar bien; para un catálogo de productos en el que desea obtener diferentes agrupaciones basadas en varios atributos de producto, una base de datos relacional podría funcionar mejor. Las bases de datos NoSQL pueden almacenar grandes volúmenes de datos de forma eficaz, pero tiene que estructurar la base de datos en torno a cómo la aplicación consulta los datos y esto dificulta la realización de consultas ad hoc. Con una base de datos relacional, puede compilar casi cualquier tipo de consulta. |
| Proyección funcional | - ¿Se pueden ejecutar preguntas, agregaciones, etc., en el lado servidor? Si ejecuto SELECT COUNT(*) desde una tabla de SQL, realizará de forma muy eficaz todo el trabajo en el servidor y devolverá el número que estoy buscando. Si quiero el mismo cálculo de un almacén de datos NoSQL que no admite la agregación, se trata de una "consulta ilimitada" ineficaz y probablemente agotará el tiempo de espera. Incluso si la consulta se realiza correctamente, tengo que recuperar todos los datos del servidor al cliente y contar las filas del cliente. - ¿Qué lenguajes o tipos de expresiones se pueden usar? Con una base de datos relacional puedo usar SQL. Con algunas bases de datos NoSQL, como Azure Table Storage, usaré OData y todo lo que puedo hacer es filtrar por la clave principal y obtener proyecciones (seleccione un subconjunto de los campos disponibles). |
| Facilidad de escalabilidad | - ¿Con qué frecuencia y hasta que punto se necesitarán escalar los datos? - ¿La plataforma implementa de forma nativa la escalabilidad horizontal? - ¿Qué tan fácil es agregar o quitar capacidad (tamaño y rendimiento)? Las bases de datos relacionales y las tablas no se particionan automáticamente para que sean escalables, por lo que son difíciles de escalar más allá de ciertas limitaciones. Los almacenes de datos NoSQL, como Azure Table Storage, crean una partición inherente de todo y casi no hay límite para agregar particiones. Puede escalar fácilmente Table Storage hasta 200 terabytes, pero el tamaño máximo de la base de datos para Azure SQL Database es de 500 gigabytes. Puede escalar datos relacionales realizando particiones en varias bases de datos, pero configurar una aplicación para admitir ese modelo implica mucho trabajo de programación. |
| Instrumentación y capacidad de administración | - ¿Qué tan fácil es instrumentar, supervisar y administrar la plataforma? Tendrá que mantenerse informado sobre el estado y el rendimiento del almacén de datos, por lo que debe saber por adelantado qué métricas le ofrece una plataforma de manera gratuita y lo que tiene que desarrollar usted mismo. |
| Operations | - ¿Qué tan fácil es implementar y ejecutar la plataforma en Azure? ¿PaaS? ¿Iaas? ¿Linux? Table Storage y SQL Database son fáciles de configurar en Azure. Las plataformas que no son soluciones PaaS de Azure integradas requieren más esfuerzo. |
| Compatibilidad de la API | - ¿Hay una API disponible que facilita el trabajo con la plataforma? Para Azure Table Service hay un SDK con una API de .NET que admite el modelo de programación asincrónica de .NET 4.5. Si va a escribir una aplicación de .NET, será mucho más fácil escribir y probar código para Azure Table Service en comparación con otra plataforma de almacén de datos de columna clave-valor que no tenga API o tenga una menos completa. |
| Integridad transaccional y coherencia de datos | - ¿Es fundamental que la plataforma admita transacciones para garantizar la coherencia de los datos? Para realizar un seguimiento de los correos electrónicos masivos enviados, el rendimiento y el bajo costo de almacenamiento de datos pueden ser más importantes que la compatibilidad automática con las transacciones o la integridad referencial en la plataforma de datos, lo que hace que Azure Table Service sea una buena opción. Para realizar el seguimiento de saldos de cuentas bancarias o pedidos de compra, una plataforma de base de datos relacional que proporciona garantías transaccionales sólidas sería una mejor opción. |
| Continuidad del negocio | - ¿Qué tan fácil es la copia de seguridad, la restauración y la recuperación ante desastres? Tarde o temprano, los datos de producción se dañarán y necesitará una función de deshacer. Las bases de datos relacionales suelen tener funcionalidades de restauración más específicas, como la capacidad de restaurar a un momento dado. Comprender qué características de restauración están disponibles en cada plataforma en consideración es un factor importante que se debe tener en cuenta. |
| Costee | - Si más de una plataforma puede admitir la carga de trabajo de datos, ¿cómo se comparan en términos de costo? Por ejemplo, si usa ASP.NET Identity, puede almacenar datos de perfil de usuario en Azure Table Service o Azure SQL Database. Si no necesita las instalaciones de consulta enriquecidas de SQL Database, puede elegir Azure Tables en parte porque cuesta mucho menos para una cantidad determinada de almacenamiento. |
Por lo general, se recomienda conocer la respuesta a las preguntas de cada una de estas categorías antes de elegir las soluciones de almacenamiento de datos.
Además, la carga de trabajo puede tener requisitos específicos que algunas plataformas pueden admitir mejor que otras. Por ejemplo:
- ¿La aplicación requiere funcionalidades de auditoría?
- ¿Cuáles son los requisitos de durabilidad de los datos: ¿necesita funcionalidades automatizadas de archivado o purga?
- ¿Tiene necesidades de seguridad especializadas? Por ejemplo, los datos incluyen PII (información de identificación personal), pero debe poder asegurarse de que la PPI se excluye de los resultados de la consulta.
- Si tiene algunos datos que no se pueden almacenar en la nube por motivos normativos o tecnológicos, es posible que necesite una plataforma de almacenamiento de datos en la nube que facilite la integración con el almacenamiento local.
Demostración: uso de SQL Database en Azure
La aplicación Fix It usa una base de datos relacional para almacenar tareas. El script de Windows PowerShell de creación del entorno que se muestra en el capítulo Automatizar todo crea dos instancias de SQL Database. Para verlas en el portal, haga clic en la pestaña Bases de datos SQL.
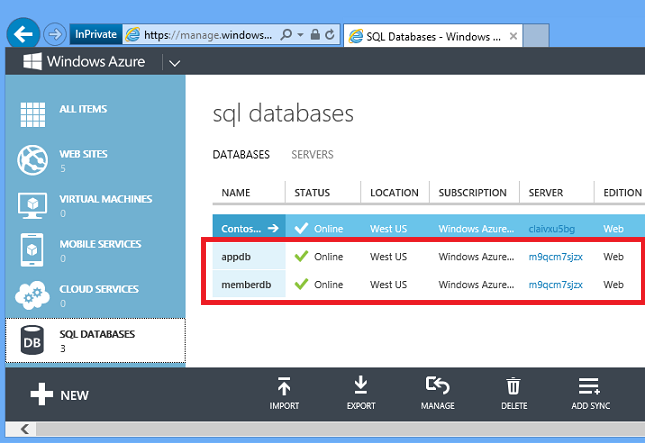
También es fácil crear bases de datos mediante el portal.
Haga clic en Nuevo: Data Services -- Base de datos SQL -- Creación rápida, escriba un nombre de base de datos, elija un servidor que ya tenga en su cuenta o cree uno nuevo, y haga clic en Crear base de datos SQL.
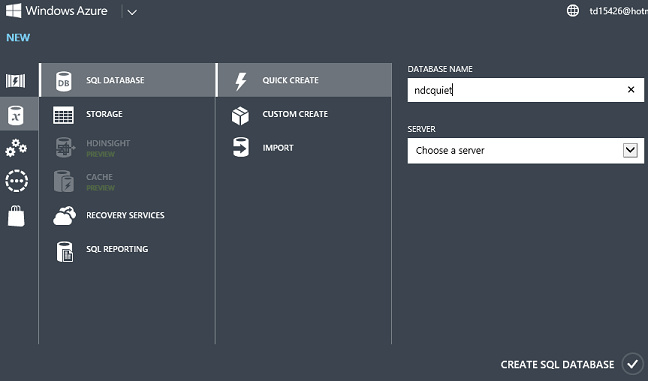
Espere varios segundos y tendrá una base de datos en Azure lista para su uso.
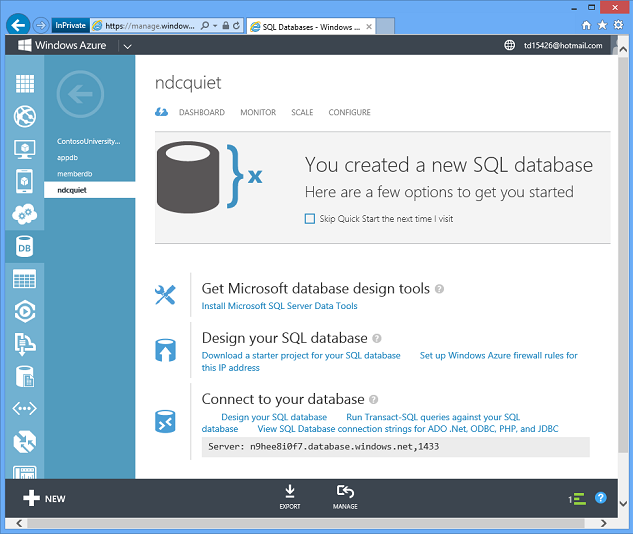
Por lo tanto, Azure hace en unos segundos lo que puede tardar un día o una semana o más en lograr en el entorno local. Además, dado que puede crear bases de datos fácilmente de forma automática en un script o mediante una API de administración, puede escalar horizontalmente de manera dinámica extendiendo los datos entre varias bases de datos, siempre y cuando la aplicación se haya programado para ello.
Este es un ejemplo de nuestro modelo de plataforma como servicio. No tiene que administrar los servidores, nosotros lo hacemos. No tiene que preocuparse por las copias de seguridad, nosotros lo hacemos. Se ejecuta en alta disponibilidad: los datos de la base de datos se replican automáticamente en tres servidores. Si una máquina deja de funcionar, se conmuta por error automáticamente y no se pierden los datos. El servidor se revisa periódicamente, no es necesario preocuparse por eso.
Haga clic en un botón y obtenga la cadena de conexión exacta que necesita y puede empezar a usar inmediatamente la nueva base de datos.

El panel muestra el historial de conexiones y la cantidad de almacenamiento usado.
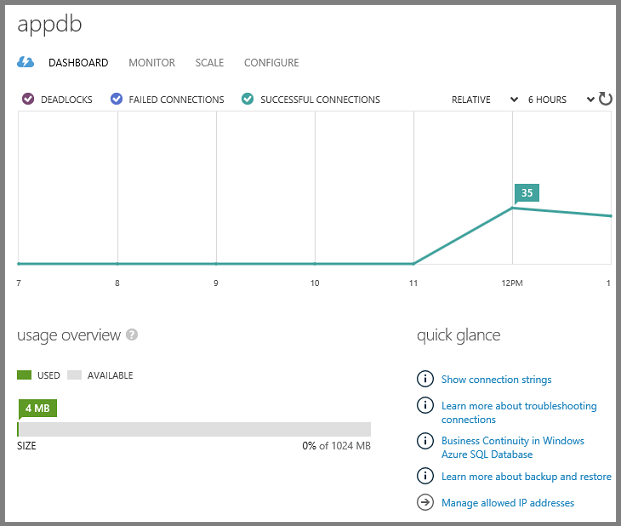
Puede administrar bases de datos en el portal o mediante herramientas de SQL Server con las que ya está familiarizado, incluido SQL Server Management Studio (SSMS) y las herramientas de Visual Studio Explorador de objetos de SQL Server (SSOX) y el Explorador de servidores.
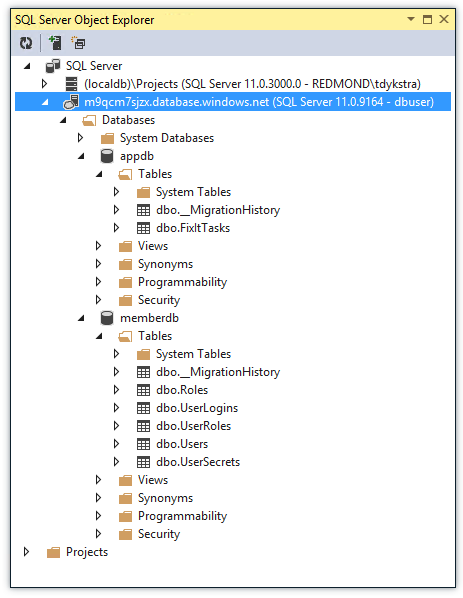
Otra cosa agradable es el modelo de precios. Puede empezar a desarrollar con una base de datos gratuita de 20 MB y una base de datos de producción comienza en aproximadamente 5 USD al mes. Solo paga por la cantidad de datos que realmente almacena en la base de datos, no por la capacidad máxima. No tiene que comprar una licencia.
SQL Database es fácil de escalar. Para la aplicación Fix It, la base de datos que creamos en nuestro script de automatización está limitada a 1 gig. Si quiere escalar verticalmente hasta 150 gig, puede ir al portal y cambiar ese valor, o ejecutar un comando de la API de REST y, en segundos, tiene una base de datos de 150 gig en la que puede implementar datos.
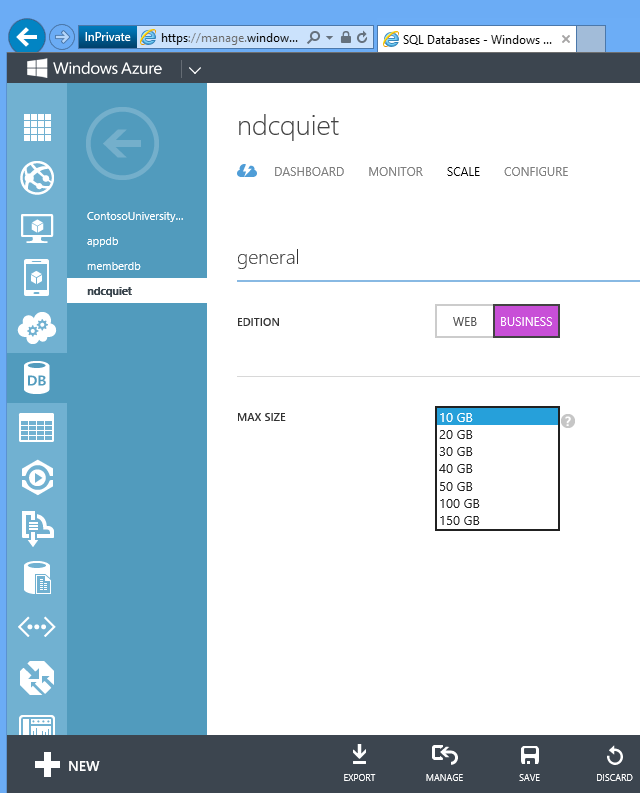
Esa es la eficacia de la nube para soportar la infraestructura de forma rápida y sencilla y empezar a usarla de inmediato.
La aplicación Fix It usa dos bases de datos SQL, una para la pertenencia (autenticación y autorización) y otra para los datos, y esto es todo lo que tiene que hacer para aprovisionarla y escalarla. Ha visto anteriormente cómo aprovisionar las bases de datos a través de scripts de Windows PowerShell y ahora también ha visto lo fácil que es hacerlo en el portal.
Entity Framework frente al acceso directo a bases de datos mediante ADO.NET
La aplicación Fix It accede a estas bases de datos mediante Entity Framework, el ORM (asignador relacional de objetos) recomendado por Microsoft para aplicaciones .NET. Un ORM es una excelente herramienta que facilita la productividad del desarrollador, pero la productividad se produce a costa de un rendimiento deteriorado en algunos escenarios. En una aplicación en la nube del mundo real, no va a elegir entre usar EF o usar ADO.NET directamente; usará ambos. La mayoría de las veces que está escribiendo código que funciona con la base de datos, obtener el máximo rendimiento no es crítico y puede aprovechar la codificación simplificada y las pruebas que obtiene con Entity Framework. En situaciones en las que la sobrecarga de EF provocaría un rendimiento inaceptable, puede escribir y ejecutar sus propias consultas mediante ADO.NET, idealmente mediante una llamada a procedimientos almacenados.
Sea cual sea el método que use para acceder a la base de datos, querrá minimizar la "locuacidad" tanto como sea posible. En otras palabras, si puede obtener todos los datos que necesita en un conjunto de resultados de consulta mayor en lugar de decenas o cientos de más consultas pequeñas, esto suele ser preferible. Por ejemplo, si necesita enumerar alumnos y los cursos en los que están inscritos, suele ser mejor obtener todos los datos en una consulta de combinación en lugar de obtener los alumnos en una consulta y ejecutar consultas independientes para los cursos de cada alumno.
Bases de datos SQL y Entity Framework en la aplicación Fix It
En la aplicación Fix It, la clase FixItContext, que deriva de la clase de Entity Framework DbContext, identifica la base de datos y especifica las tablas de la base de datos. El contexto especifica un conjunto de entidades (tabla) para las tareas y el código pasa al contexto el nombre de la cadena de conexión. Ese nombre hace referencia a una cadena de conexión definida en el archivo Web.config.
public class MyFixItContext : DbContext
{
public MyFixItContext()
: base("name=appdb")
{
}
public DbSet<MyFixIt.Persistence.FixItTask> FixItTasks { get; set; }
}
La cadena de conexión del archivo Web.config se denomina appdb (aquí apunta a la base de datos de desarrollo local):
<connectionStrings>
<add name="DefaultConnection" connectionString="Data Source=(LocalDb)\v11.0;Initial Catalog=aspnet-MyFixIt-20130604091232_4;Integrated Security=True" providerName="System.Data.SqlClient" />
<add name="appdb" connectionString="Data Source=(localdb)\v11.0; Initial Catalog=MyFixItContext-20130604091609_11;Integrated Security=True; MultipleActiveResultSets=True" providerName="System.Data.SqlClient" />
</connectionStrings>
Entity Framework crea una tabla FixItTasks basada en las propiedades incluidas en la clase de entidad FixItTask. Se trata de una clase POCO simple (Plain Old CLR Object), lo que significa que no hereda de ninguna dependencias ni tiene ninguna dependencia en Entity Framework. Pero Entity Framework sabe cómo crear una tabla basada en ella y ejecutar operaciones CRUD (create-read-update-delete) con ella.
public class FixItTask
{
public int FixItTaskId { get; set; }
public string CreatedBy { get; set; }
[Required]
public string Owner { get; set; }
[Required]
public string Title { get; set; }
public string Notes { get; set; }
public string PhotoUrl { get; set; }
public bool IsDone { get; set; }
}

La aplicación Fix It incluye una interfaz de repositorio que usa para las operaciones CRUD que funcionan con el almacén de datos.
public interface IFixItTaskRepository
{
Task<List<FixItTask>> FindOpenTasksByOwnerAsync(string userName);
Task<List<FixItTask>> FindTasksByCreatorAsync(string userName);
Task<MyFixIt.Persistence.FixItTask> FindTaskByIdAsync(int id);
Task CreateAsync(FixItTask taskToAdd);
Task UpdateAsync(FixItTask taskToSave);
Task DeleteAsync(int id);
}
Tenga en cuenta que todos los métodos del repositorio son asincrónicos, por lo que todo el acceso a los datos se puede realizar de forma completamente asincrónica.
La implementación del repositorio llama a los métodos asincrónicos de Entity Framework para trabajar con los datos, incluidas las consultas LINQ, así como para las operaciones de inserción, actualización y eliminación. Este es un ejemplo del código para buscar una tarea de Fix It.
public async Task<FixItTask> FindTaskByIdAsync(int id)
{
FixItTask fixItTask = null;
Stopwatch timespan = Stopwatch.StartNew();
try
{
fixItTask = await db.FixItTasks.FindAsync(id);
timespan.Stop();
log.TraceApi("SQL Database", "FixItTaskRepository.FindTaskByIdAsync", timespan.Elapsed, "id={0}", id);
}
catch(Exception e)
{
log.Error(e, "Error in FixItTaskRepository.FindTaskByIdAsynx(id={0})", id);
}
return fixItTask;
}
Observará que también hay algún código de tiempo y registro de errores aquí; lo veremos más adelante en el capítulo Supervisión y telemetría.
Elección de SQL Database (PaaS) frente a SQL Server en una máquina virtual (IaaS) en Azure
Lo bueno de SQL Server y Azure SQL Database es que el modelo de programación principal para ambos es idéntico. Puede usar la mayoría de las mismas aptitudes en ambos entornos. Incluso puede usar una base de datos de SQL Server en desarrollo y una instancia de SQL Database en la nube, que es cómo se configura la aplicación Fix It.
Como alternativa, puede ejecutar la misma instancia de SQL Server en la nube que ejecuta localmente instalándola en máquinas virtuales de IaaS. Para algunas aplicaciones heredadas, ejecutar SQL Server en una máquina virtual podría ser una mejor solución. Dado que una base de datos de SQL Server se ejecuta en una máquina virtual dedicada, tiene más recursos disponibles que una base de datos de SQL Database que se ejecuta en un servidor compartido. Esto significa que una base de datos de SQL Server puede ser mayor y seguir funcionando bien. En general, cuanto menor sea el tamaño de la base de datos y el tamaño de la tabla, mejor funciona el caso de uso para SQL Database (PaaS).
Estas son algunas directrices sobre cómo elegir entre los dos modelos.
| Azure SQL Database (PaaS) | SQL Server en una máquina virtual (IaaS) |
|---|---|
| Ventajas: no tiene que crear ni administrar máquinas virtuales, actualizar o aplicar revisiones al sistema operativo o SQL; Azure lo hace por usted. - Alta disponibilidad integrada, con un Acuerdo de Nivel de Servicio de nivel de base de datos. - Bajo costo total de propiedad (TCO) porque solo paga por lo que usa (no se requiere licencia). - Adecuado para controlar grandes cantidades de bases de datos más pequeñas (<=500 GB cada una). - Fácil de crear dinámicamente nuevas bases de datos para habilitar la escalabilidad horizontal. | Ventajas: compatible con características con SQL Server local. - Puede implementar la alta disponibilidad de SQL Server a través de AlwaysOn en más de 2 máquinas virtuales, con un Acuerdo de Nivel de Servicio de nivel de máquina virtual. - Tiene un control completo sobre cómo se administra SQL. - Puede volver a usar las licencias de SQL que ya posee o pagar por hora. - Adecuado para controlar menos bases de datos, pero más grandes (1 TB+). |
| Desventajas - Algunas brechas de características en comparación con SQL Server local (falta de integración de CLR, TDE, compatibilidad con compresión, SQL Server Reporting Services, etc.) - Límite de tamaño de base de datos de 500 GB. | Desventajas - Las actualizaciones y revisiones (SO y SQL) son su responsabilidad - La creación y administración de bases de datos son su responsabilidad - IOPS de disco (operaciones de entrada y salida por segundo) limitadas a aproximadamente 8000 (a través de 16 unidades de datos). |
Si desea usar SQL Server en una máquina virtual, puede usar su propia licencia de SQL Server o puede pagar por hora. Por ejemplo, en el portal o a través de la API de REST, puede crear una máquina virtual mediante una imagen de SQL Server.

Cuando se crea una máquina virtual con una imagen de SQL Server, se prorratea el costo de la licencia de SQL Server por hora en función del uso de la máquina virtual. Si tiene un proyecto que solo se ejecutará durante un par de meses, es más barato pagar por hora. Si cree que su proyecto va a durar durante años, es más barato comprar la licencia de la manera que normalmente hace.
Resumen
La informática en la nube facilita la combinación de enfoques de almacenamiento de datos para adaptarse mejor a las necesidades de la aplicación. Si va a compilar una nueva aplicación, piense detenidamente en las preguntas enumeradas aquí para elegir enfoques que seguirán funcionando bien cuando la aplicación crezca. En el capítulo siguiente se explican algunas estrategias de creación de particiones que puede usar para combinar varios enfoques de almacenamiento de datos.
Recursos
Para obtener más información, vea los recursos siguientes.
Elección de una plataforma de base de datos:
- Acceso a datos para soluciones altamente escalables: uso de la SQL, NoSQL y la persistencia políglota. Libro electrónico de Patrones y prácticas de Microsoft que profundiza en los diferentes tipos de almacenes de datos disponibles para las aplicaciones en la nube.
- Patrones y procedimientos de Microsoft: Guía de Azure. Consulte Manual de coherencia de datos, Guía de replicación y sincronización de datos, Patrón de tabla de índices, Patrón de vista materializada.
- BASE: una alternativa al ácido. Artículo sobre los inconvenientes entre la coherencia y la escalabilidad de los datos.
- Siete bases de datos en siete semanas: una guía para bases de datos modernas y el movimiento NoSQL. Libro de Eric Redmond y Jim R. Wilson. Se recomienda encarecidamente para familiarizarse con la gama de plataformas de almacenamiento de datos disponibles en la actualidad.
Elección entre SQL Server y SQL Database:
- Instrucciones sobre la versión preliminar Premium de SQL Database. Introducción a Prémium para SQL Database e instrucciones sobre cuándo elegirla en lugar de las ediciones Web y Empresarial de SQL Database.
- Instrucciones y limitaciones (Azure SQL Database). Página del portal que se vincula a la documentación sobre las limitaciones de SQL Database, incluida una que se centra en las características de SQL Server que SQL Database no admite.
- SQL Server en Azure Virtual Machines. Página del portal que se vincula a la documentación sobre la ejecución de SQL Server en Azure.
- Scott Guthrie explica las bases de datos SQL en Azure. Vídeo de introducción de 6 minutos a SQL Database por Scott Guthrie.
- Estrategias de desarrollo y patrones de aplicación de SQL Server en Azure Virtual Machines.
Uso de Entity Framework y SQL Database en una aplicación web de ASP.NET
- Introducción a EF 6 mediante MVC 5. Serie de tutoriales de nueve partes que le guía a través de la creación de una aplicación de MVC que usa EF e implementa la base de datos en Azure y SQL Database.
- Implementación web de ASP.NET con Visual Studio. Serie de tutoriales de doce partes que profundiza en cómo implementar una base de datos mediante EF Code First.
- Implemente una aplicación ASP.NET MVC 5 segura con pertenencia, OAuth y SQL Database en un sitio web de Azure. Tutorial paso a paso que le guía por la creación de una aplicación web que usa autenticación, almacena tablas de aplicación en la base de datos de pertenencia, modifica el esquema de la base de datos e implementa la aplicación en Azure.
- Mapa de contenido de acceso a datos de ASP.NET. Vínculos a recursos para trabajar con EF y SQL Database.
Uso de MongoDB en Azure:
- MongoDB Atlas en Azure. Página del portal para obtener documentación sobre cómo ejecutar MongoDB Atlas en Azure.
- Creación de un sitio web de Azure que se conecte a MongoDB que se ejecuta en una máquina virtual de Azure. Tutorial paso a paso que muestra cómo usar una base de datos de MongoDB en una aplicación web de ASP.NET.
HDInsight (Hadoop en Azure):
- HDInsight. Portal a la documentación de HDInsight en el sitio web de Azure.
- Hadoop y HDInsight: macrodatos en Azure. Artículo de MSDN Magazine de Bruno Terkaly y Ricardo Villalobos que presenta Hadoop en Azure.
- Patrones y procedimientos de Microsoft: Guía de Azure. Consulte Patrón de MapReduce.
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de