Antipatrón Chatty I/O
El efecto acumulado de un gran número de solicitudes de E/S puede afectar notablemente al rendimiento y la capacidad de respuesta.
Descripción del problema
Las llamadas de red y otras operaciones de E/S son inherentemente lentas en comparación con las tareas de proceso. Cada solicitud de E/S normalmente tiene una sobrecarga importante y el efecto acumulado de numerosas operaciones de E/S puede ralentizar el sistema. Estas son algunas causas comunes de Chatty I/O.
Lectura y escritura de registros individuales en una base de datos como solicitudes distintas
En el ejemplo siguiente se lee de una base de datos de productos. Hay tres tablas, Product, ProductSubcategory y ProductPriceListHistory. El código recupera todos los productos en una subcategoría, junto con la información sobre los precios, mediante la ejecución de una serie de consultas:
- Consulte la subcategoría en la tabla
ProductSubcategory. - Consulte la tabla
Productpara buscar todos los productos de esa subcategoría. - Para cada producto, consulte los datos de precio en la tabla
ProductPriceListHistory.
La aplicación usa Entity Framework para consultar la base de datos. Puede encontrar el ejemplo completo aquí.
public async Task<IHttpActionResult> GetProductsInSubCategoryAsync(int subcategoryId)
{
using (var context = GetContext())
{
// Get product subcategory.
var productSubcategory = await context.ProductSubcategories
.Where(psc => psc.ProductSubcategoryId == subcategoryId)
.FirstOrDefaultAsync();
// Find products in that category.
productSubcategory.Product = await context.Products
.Where(p => subcategoryId == p.ProductSubcategoryId)
.ToListAsync();
// Find price history for each product.
foreach (var prod in productSubcategory.Product)
{
int productId = prod.ProductId;
var productListPriceHistory = await context.ProductListPriceHistory
.Where(pl => pl.ProductId == productId)
.ToListAsync();
prod.ProductListPriceHistory = productListPriceHistory;
}
return Ok(productSubcategory);
}
}
En este ejemplo se muestra el problema de forma explícita, pero, en ocasiones, si captura implícitamente los registros secundarios uno a uno, el asignador relacional de objetos puede enmascarar el problema. Esto se conoce como el "problema N+1".
Implementación de una única operación lógica como serie de solicitudes HTTP
Esto suele ocurrir cuando los desarrolladores intentan seguir un paradigma basado en los objetos y tratan los objetos remotos como si fueran objetos locales en la memoria. Esto puede producir demasiado recorrido de ida y vuelta en la red. Por ejemplo, la siguiente API de web expone las propiedades individuales de los objetos User a través de métodos HTTP GET individuales.
public class UserController : ApiController
{
[HttpGet]
[Route("users/{id:int}/username")]
public HttpResponseMessage GetUserName(int id)
{
...
}
[HttpGet]
[Route("users/{id:int}/gender")]
public HttpResponseMessage GetGender(int id)
{
...
}
[HttpGet]
[Route("users/{id:int}/dateofbirth")]
public HttpResponseMessage GetDateOfBirth(int id)
{
...
}
}
Aunque técnicamente no hay ningún problema con este enfoque, la mayoría de los clientes probablemente tendrá que obtener varias propiedades para cada User, lo cual dará lugar a código de cliente similar al siguiente.
HttpResponseMessage response = await client.GetAsync("users/1/username");
response.EnsureSuccessStatusCode();
var userName = await response.Content.ReadAsStringAsync();
response = await client.GetAsync("users/1/gender");
response.EnsureSuccessStatusCode();
var gender = await response.Content.ReadAsStringAsync();
response = await client.GetAsync("users/1/dateofbirth");
response.EnsureSuccessStatusCode();
var dob = await response.Content.ReadAsStringAsync();
Lectura y escritura en un archivo de disco
Las operaciones de E/S de archivos implican la apertura de un archivo y su desplazamiento al punto adecuado para leer o escribir datos. Una vez completada la operación, el archivo podría cerrarse para ahorrar recursos del sistema operativo. Una aplicación que lee y escribe constantemente pequeñas cantidades de información en un archivo generará una sobrecarga de E/S considerable. Las solicitudes de escritura pequeñas también pueden provocar la fragmentación del archivo, lo cual mermará aún más las operaciones de E/S posteriores.
En el siguiente ejemplo se usa un objeto FileStream para escribir un objeto Customer en un archivo. Al crear FileStream, el archivo se abre y al eliminarlo, se cierra. (La instrucción using elimina automáticamente el objeto FileStream). Si la aplicación llama a este método varias veces cuando se agregan nuevos clientes, la sobrecarga de E/S puede acumularse rápidamente.
private async Task SaveCustomerToFileAsync(Customer customer)
{
using (Stream fileStream = new FileStream(CustomersFileName, FileMode.Append))
{
BinaryFormatter formatter = new BinaryFormatter();
byte [] data = null;
using (MemoryStream memStream = new MemoryStream())
{
formatter.Serialize(memStream, customer);
data = memStream.ToArray();
}
await fileStream.WriteAsync(data, 0, data.Length);
}
}
Procedimiento para corregir el problema
Reduzca el número de solicitudes de E/S al empaquetar los datos en menos solicitudes, pero mayores.
Capture los datos de una base de datos como una sola consulta, en lugar de como varias consultas menores. Esta es una versión revisada del código que recupera información del producto.
public async Task<IHttpActionResult> GetProductCategoryDetailsAsync(int subCategoryId)
{
using (var context = GetContext())
{
var subCategory = await context.ProductSubcategories
.Where(psc => psc.ProductSubcategoryId == subCategoryId)
.Include("Product.ProductListPriceHistory")
.FirstOrDefaultAsync();
if (subCategory == null)
return NotFound();
return Ok(subCategory);
}
}
Siga los principios de diseño de REST para las API web. Esta es una versión revisada de la API web del ejemplo anterior. En lugar de métodos GET independientes para cada propiedad, hay un único método GET que devuelve el objeto User. Esto da como resultado un cuerpo de respuesta mayor por solicitud, pero es probable que los clientes realicen menos llamadas API.
public class UserController : ApiController
{
[HttpGet]
[Route("users/{id:int}")]
public HttpResponseMessage GetUser(int id)
{
...
}
}
// Client code
HttpResponseMessage response = await client.GetAsync("users/1");
response.EnsureSuccessStatusCode();
var user = await response.Content.ReadAsStringAsync();
Para las operaciones de E/S de archivos, considere la posibilidad de almacenar en búfer los datos en memoria y de escribirlos en un archivo como una única operación. Este enfoque reduce la sobrecarga de al abrir y cerrar el archivo repetidamente y ayuda a reducir la fragmentación del archivo en el disco.
// Save a list of customer objects to a file
private async Task SaveCustomerListToFileAsync(List<Customer> customers)
{
using (Stream fileStream = new FileStream(CustomersFileName, FileMode.Append))
{
BinaryFormatter formatter = new BinaryFormatter();
foreach (var customer in customers)
{
byte[] data = null;
using (MemoryStream memStream = new MemoryStream())
{
formatter.Serialize(memStream, customer);
data = memStream.ToArray();
}
await fileStream.WriteAsync(data, 0, data.Length);
}
}
}
// In-memory buffer for customers.
List<Customer> customers = new List<Customers>();
// Create a new customer and add it to the buffer
var customer = new Customer(...);
customers.Add(customer);
// Add more customers to the list as they are created
...
// Save the contents of the list, writing all customers in a single operation
await SaveCustomerListToFileAsync(customers);
Consideraciones
En los dos primeros ejemplos se realizan menos llamadas de E/S, pero cada una de ellas recupera más información. Debe tener en cuenta el equilibrio entre estos dos factores. La respuesta correcta dependerá de los patrones de uso reales. Por ejemplo, en el ejemplo de API web, puede que los clientes a menudo solo necesiten el nombre de usuario. En ese caso, tendría sentido exponerlo como una llamada API independiente. Para más información, consulte el antipatrón Extraneous Fetching.
Al leer datos, no realice solicitudes de E/S demasiado grandes. Las aplicaciones solo deben recuperar la información que sea probable que usen.
En ocasiones resulta útil para la partición de la información de un objeto en dos fragmentos, los datos de acceso frecuente en la mayoría de las solicitudes y los datos de acceso menos frecuente que casi no se usan. A menudo, los datos a los que se accede con más frecuencia son una cantidad relativamente pequeña del total de datos de un objeto, por lo que devolver solo esa parte puede prevenir notablemente la sobrecarga de E/S.
Al escribir los datos, evite bloquear los recursos durante más tiempo del necesario para reducir las posibilidades de contención durante las operaciones largas. Si una operación de escritura abarca varios almacenes de datos, archivos o servicios, adopte un enfoque coherente. Consulte la guía de coherencia de los datos.
Si almacena los datos en búfer en memoria antes de escribir, estos son vulnerables si se bloquea el proceso. Si la velocidad de los datos normalmente tiene ráfagas o es relativamente dispersa, puede ser más seguro para almacenarlos en búfer en una cola durable externa como Event Hubs.
Considere la posibilidad de almacenar en caché los datos que recupere de un servicio o una base de datos. Esto puede ayudar a reducir el volumen de E/S, al evitar repetir las solicitudes de los mismos datos. Para más información, consulte los procedimientos recomendados para el almacenamiento en caché.
Procedimiento para detectar el problema
Algunos síntomas de Chatty I/O son una latencia elevada y un rendimiento bajo. Es probable que los usuarios finales informen de tiempos de respuesta prolongados o errores provocados por el agotamiento del tiempo de espera de los servicios, debido al aumento de contención de los recursos de E/S.
Puede realizar los pasos siguientes para ayudar a identificar la causa de cualquier problema:
- Supervise los procesos del sistema de producción para identificar las operaciones con tiempos de respuesta prolongados.
- Realice pruebas de carga de cada operación identificada en el paso anterior.
- Durante las pruebas de carga, recopile datos de telemetría acerca de las solicitudes de acceso de datos realizadas por cada operación.
- Recopile estadísticas detalladas de cada solicitud enviada a un almacén de datos.
- Genere perfiles de aplicación en el entorno de prueba para establecer dónde se pueden estar produciendo cuellos de botella de E/S.
Busque alguno de estos síntomas:
- Un gran número de solicitudes de E/S pequeñas en el mismo archivo.
- Un gran número de solicitudes de red pequeñas realizadas por una instancia de la aplicación al mismo servicio.
- Un gran número de solicitudes pequeñas realizadas por una instancia de la aplicación al mismo almacén de datos.
- Aplicaciones y servicios dependientes de las operaciones de E/S.
Diagnóstico de ejemplo
En las siguientes secciones se aplican estos pasos al ejemplo anterior donde se consulta una base de datos.
Prueba de carga de la aplicación
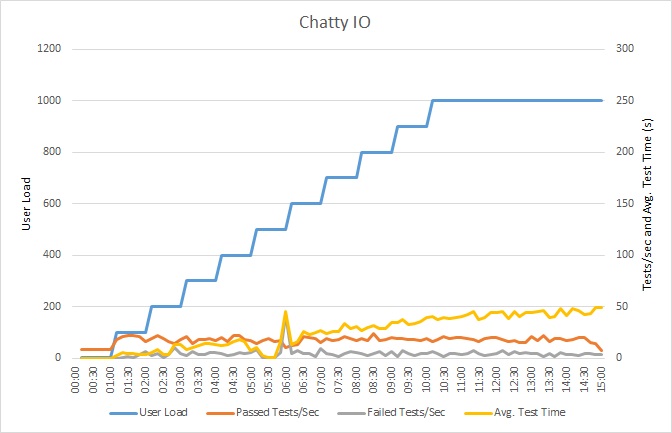
En este gráfico se muestran los resultados de las pruebas de carga. La mediana de tiempo de respuesta se mide con decenas de segundos por solicitud. En el gráfico se muestra una latencia muy alta. Con una carga de 1000 usuarios, uno de ellos podría tener que esperar casi un minuto ver los resultados de una consulta.
Nota:
La aplicación se implementó como aplicación web de Azure App Service, con Azure SQL Database. Para la prueba de carga se utilizó una carga de trabajo de pasos simulada de hasta 1000 usuarios simultáneos. La base de datos se configuró con un grupo de conexiones que admitía hasta 1000 conexiones simultáneas, para reducir la posibilidad de que la contención para las conexiones afectara a los resultados.
Supervisión de la aplicación
Puede usar un paquete de supervisión del rendimiento de la aplicación (APM) para capturar y analizar las métricas clave que pueden identificar Chatty I/O. La importancia de las distintas métricas dependerá de la carga de trabajo de E/S. En este ejemplo, las solicitudes de E/S interesantes eran las consultas de base de datos.
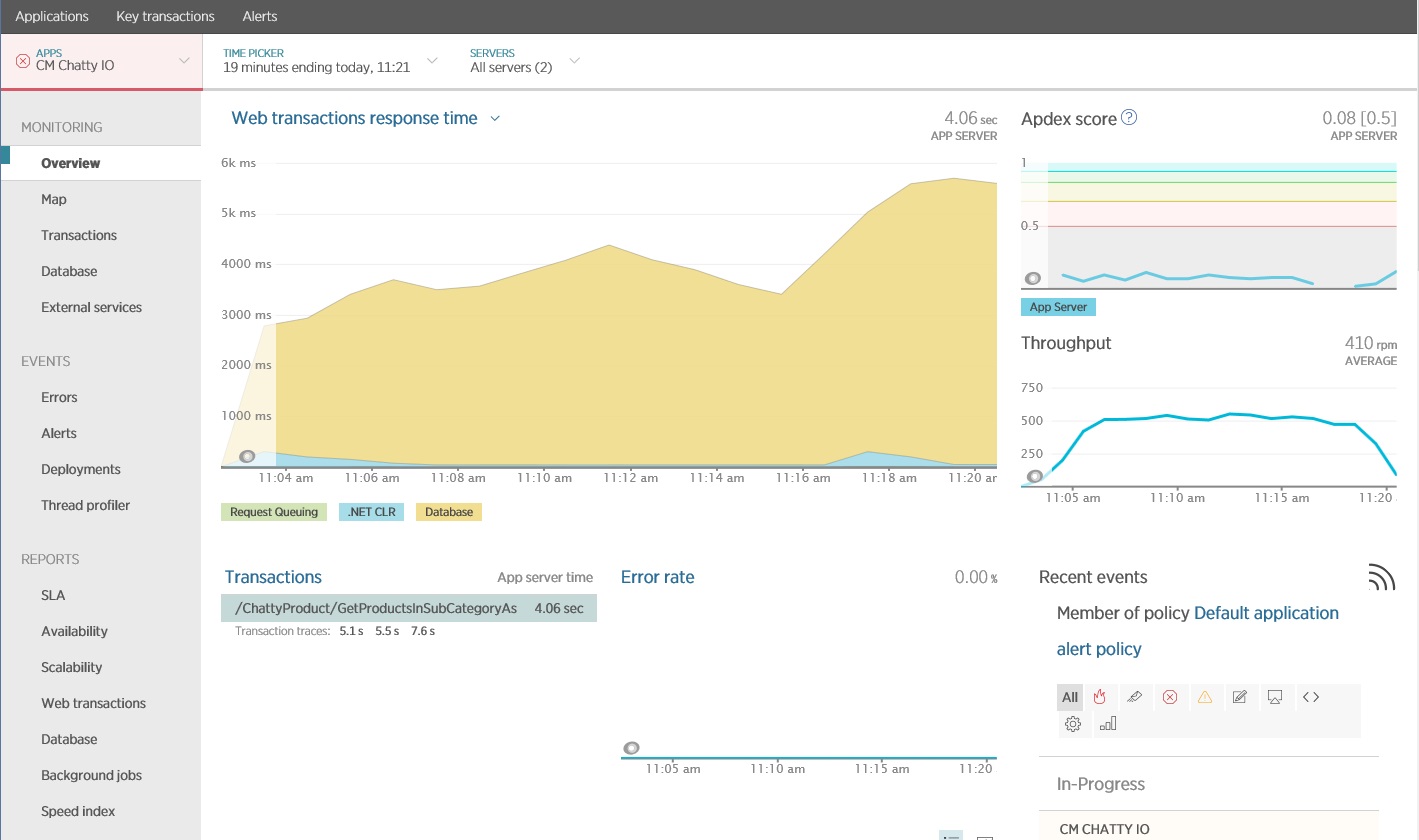
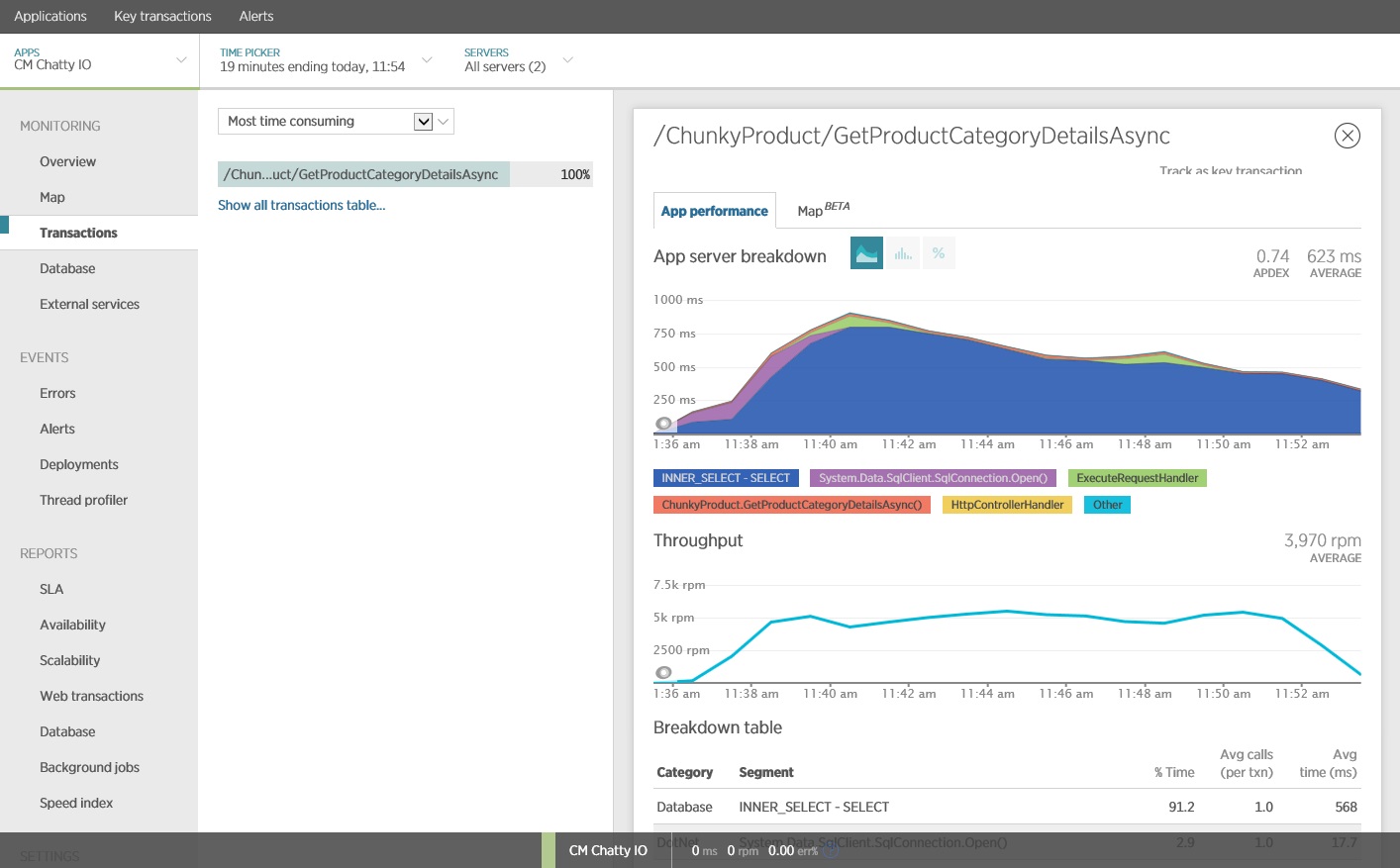
En la siguiente imagen se muestran los resultados generados mediante APM de New Relic. El tiempo de respuesta promedio de la base de datos fue de unos 5,6 segundos por solicitud como máximo durante la carga de trabajo máxima. El sistema admitió un promedio de 410 solicitudes por minuto durante la prueba.
Recopilación de la información de acceso a los datos detallados
Al profundizar más en los datos de supervisión se observa que la aplicación ejecuta tres instrucciones SQL SELECT diferentes. Estas corresponden a las solicitudes generadas por Entity Framework para capturar los datos de las tablas ProductListPriceHistory, Product y ProductSubcategory. Además, la consulta que recupera los datos de la tabla ProductListPriceHistory es la instrucción SELECT ejecutada con mucha más frecuencia, en un orden de magnitud.
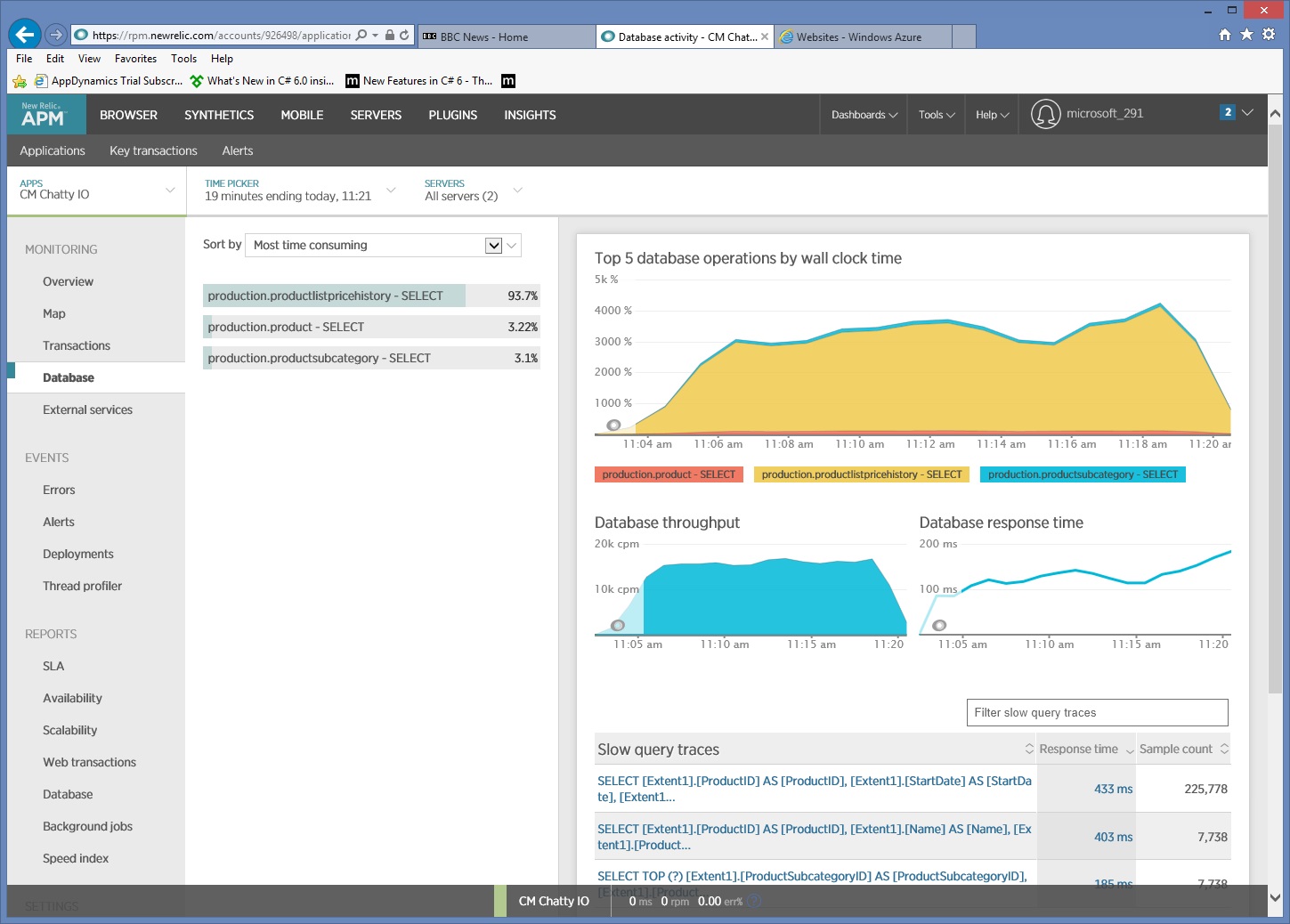
Parece que el método GetProductsInSubCategoryAsync anterior realiza 45 consultas SELECT. Cada consulta hace que la aplicación abra una nueva conexión de SQL.
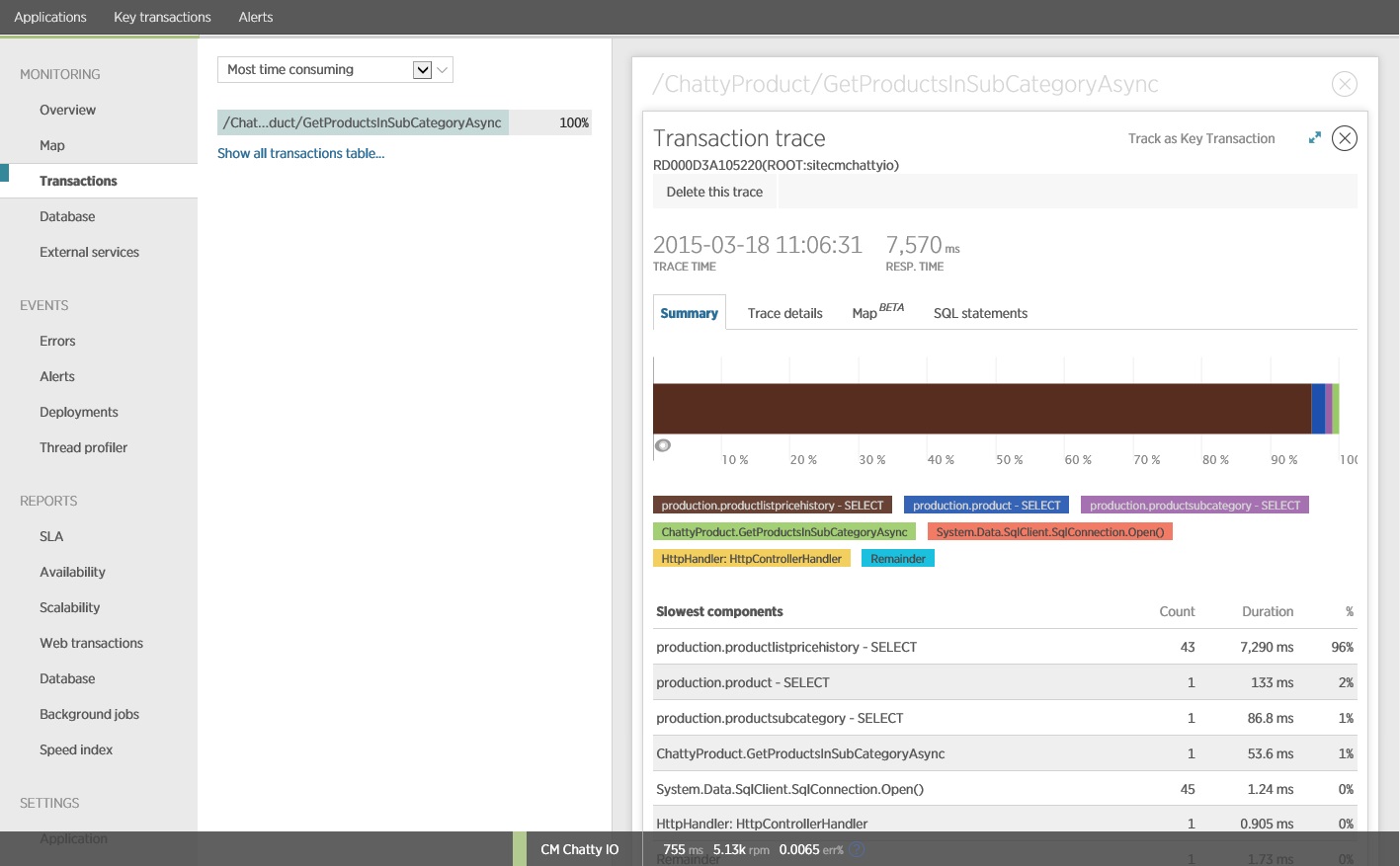
Nota:
En esta imagen se muestra información de seguimiento de la instancia más lenta de la operación GetProductsInSubCategoryAsync en la prueba de carga. En un entorno de producción, es útil examinar el seguimiento de las instancias más lentas para ver si hay un patrón que indique un problema. Si simplemente observa los valores promedio, podría pasar por alto los problemas que provoquen la disminución considerable del rendimiento con carga.
En la imagen siguiente se muestran las instrucciones SQL reales que se han emitido. La consulta que captura la información de precios se ejecuta para cada producto de la subcategoría de producto. El uso de una combinación de reduciría considerablemente el número de llamadas a la base de datos.
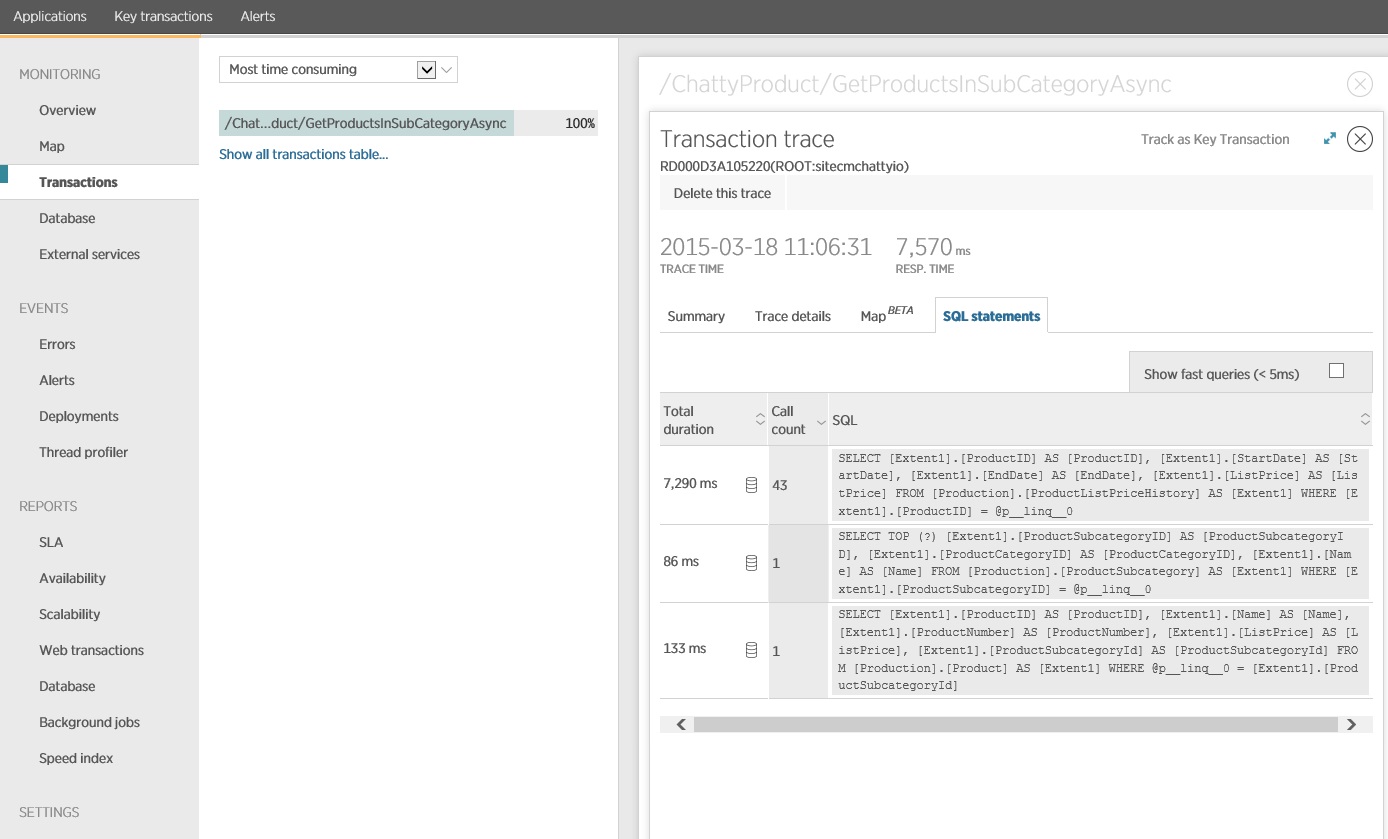
Si usa un asignador relacional de objetos como Entity Framework, el seguimiento de las consultas SQL puede proporcionar una visión general de cómo este convierte las llamadas con programación en instrucciones SQL e indicar las áreas donde se podría optimizar el acceso a los datos.
Implementación de la solución y comprobación del resultado
Al volver a escribir la llamada a Entity Framework se produjeron los siguientes resultados.
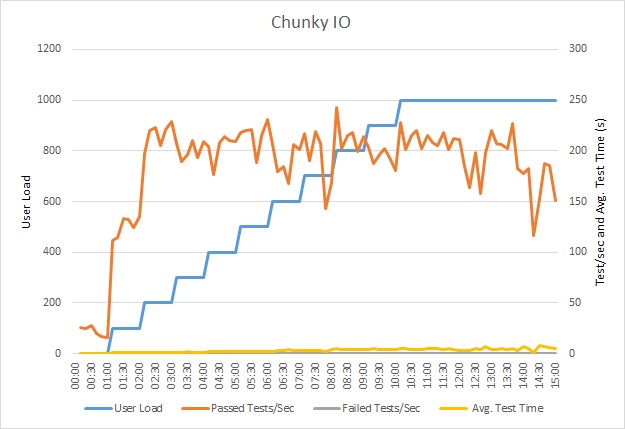
Esta prueba de carga se realizó en la misma implementación, con el mismo perfil de carga. Esta vez, en el gráfico se muestra una latencia mucho menor. El tiempo medio de solicitud con 1000 usuarios es de 5-6 segundos, ha descendido casi un minuto.
Ahora el sistema admite un promedio de 3970 solicitudes por minuto, en comparación con las 410 de la prueba anterior.
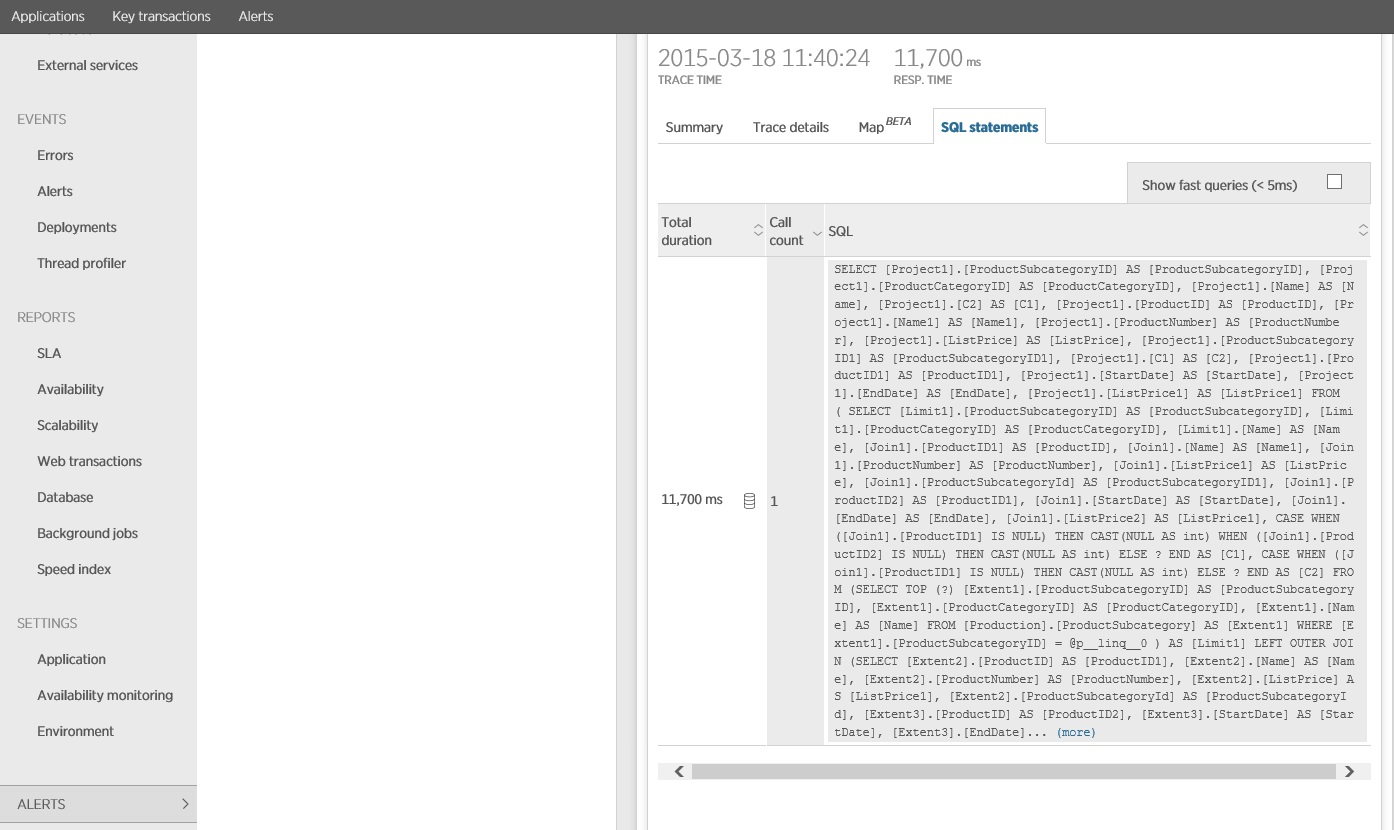
El seguimiento de la instrucción SQL muestra que todos los datos se capturan en una única instrucción SELECT. Aunque esta consulta es considerablemente más compleja, se realiza solo una vez por operación. Y mientras las combinaciones complejas pueden resultar caras, los sistemas de bases de datos relacionales están optimizados para este tipo de consulta.
Recursos relacionados
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de