Como todos ya sabemos, la inteligencia artificial ofrece el potencial de transformar el comercio minorista. Es razonable creer que los minoristas desarrollarán una arquitectura de la experiencia del cliente respaldada por la inteligencia artificial. Algunas de las expectativas son que una plataforma mejorada con inteligencia artificial proporcionará un aumento notable de los ingresos debido a la hiperpersonalización. El comercio digital continúa reforzando las expectativas, las preferencias y el comportamiento del cliente. Demandas como interacción en tiempo real, recomendaciones pertinentes e hiperpersonalización están impulsando la velocidad y la comodidad al clic de un botón. Habilitamos la inteligencia en las aplicaciones mediante la voz natural, la visión, y así sucesivamente. Esta inteligencia permite mejoras en el sector minorista que aumentarán el valor y afectaran al modo en que los clientes compran.
Este documento se centra en el concepto de inteligencia artificial de búsqueda visual y ofrece algunas consideraciones importantes sobre su implementación. Se proporciona un flujo de trabajo de ejemplo y se asignan sus fases a las tecnologías de Azure pertinentes. El concepto se basa en que los clientes puedan aprovechar una imagen tomada con su dispositivo móvil o que se encuentre en Internet. Realizarían una búsqueda de elementos pertinentes y similares, en función de la intención de la experiencia. Por lo tanto, la búsqueda visual mejora la velocidad desde la entrada de texto a una imagen con varios puntos de metadatos a fin de que aparezcan rápidamente los artículos aplicables disponibles.
Motores de búsqueda visual
Los motores de búsqueda visual recuperan información mediante el uso de imágenes como entrada y, con frecuencia, aunque no exclusivamente, también como salida.
Los motores son cada vez más comunes en el sector minorista y por muy buenas razones:
- Según un informe publicado por Emarketer en 2017, casi un 75 % de los usuarios de Internet buscan imágenes o vídeos de un producto antes de realizar una compra.
- De acuerdo con el informe de Slyce (una compañía de búsqueda visual) de 2015, el 74 % de los consumidores también considera que las búsquedas de texto no son eficaces.
Por lo tanto, según la investigación realizada por Markets & Markets, el mercado de reconocimiento de imágenes representará más de 25 000 millones de dólares USD para el año 2019.
La tecnología ya ha arraigado en las principales marcas de comercio electrónico, quienes también han contribuido significativamente a su desarrollo. Los usuarios pioneros más importantes son probablemente:
- eBay con sus herramientas Image Search y "Find It on eBay" de la aplicación (por ahora solo una experiencia móvil).
- Pinterest con su herramienta de detección visual, Lens.
- Microsoft con Bing Visual Search.
Adopción y adaptación
Afortunadamente, no se necesitan grandes cantidades de potencia de computación para beneficiarse de la búsqueda visual. Cualquier negocio con un catálogo de imágenes puede sacar partido de la experiencia de inteligencia artificial de Microsoft integrada en sus servicios de Azure.
La API Bing Visual Search proporciona una manera de extraer información de contexto de las imágenes e identificar, por ejemplo, mobiliario para el hogar, moda, varias clases de productos, etc.
También devuelve imágenes de su propio catálogo que son visualmente parecidas, productos con orígenes de compra relativos o búsquedas relacionadas. Si bien es interesante, su uso será limitado si la empresa no es uno de esos orígenes.
Bing también proporciona:
- Etiquetas que le permiten explorar objetos o conceptos que se encuentran en la imagen.
- Rectángulos de selección para regiones de interés de la imagen (por ejemplo, artículos de ropa o muebles).
Puede tomar esa información para reducir considerablemente el espacio (y el tiempo) de búsqueda en el catálogo de productos de la empresa y limitarlo a los objetos que son como los de la región y categoría de interés.
Implementación por su cuenta
Hay algunos componentes clave que debe tener en cuenta al implementar la búsqueda visual:
- Ingesta y filtrado de imágenes
- Técnicas de almacenamiento y recuperación
- Caracterización, codificación o "configuración de hash"
- Medidas o distancias de similitud y clasificación

Figura 1: Ejemplo de canalización de Visual Search
Origen de las imágenes
Si no dispone de un catálogo de imágenes, es posible que deba entrenar los algoritmos en conjuntos de datos disponibles públicamente, como fashion MNIST, deep fashion y similar. Estos algoritmos contienen varias categorías de productos y se usan normalmente para comparar los algoritmos de clasificación y búsqueda de imágenes.

Figura 2: Un ejemplo del conjunto de datos DeepFashion
Filtrado de las imágenes
La mayoría de los conjuntos de datos de referencia, como los antes mencionados, se han procesado previamente.
Si va a compilar su propio punto de referencia, como mínimo, le interesará que todas las imágenes tengan el mismo tamaño, determinado principalmente por la entrada para la que se entrena el modelo.
En muchos casos, es mejor también normalizar la luminosidad de las imágenes. Según el nivel de detalle de la búsqueda, color puede ser también información redundante, por lo que reducirlo a blanco y negro le ayudará con los tiempos de procesamiento.
Por último, pero no menos importante, el conjunto de datos de imagen debe estar equilibrado entre las diferentes clases que representa.
Base de datos de imágenes
La capa de datos es un componente especialmente delicado de su arquitectura. Contendrá:
- Imágenes
- Los metadatos sobre las imágenes (tamaño, etiquetas, SKU del producto o descripción)
- Los datos generados por el modelo de aprendizaje automático (por ejemplo, un vector numérico de 4096 elementos por imagen)
A medida que recupera imágenes de distintos orígenes o usa modelos de aprendizaje automático para obtener un rendimiento óptimo, la estructura de los datos cambia. Por lo tanto, es importante elegir una tecnología o una combinación que pueda tratar con datos semiestructurados y sin esquema fijo.
También puede necesitar un número mínimo de puntos de datos útiles (por ejemplo, un identificador o clave de imagen, una SKU de producto, una descripción o un campo de etiqueta).
Azure Cosmos DB ofrece la flexibilidad necesaria y una variedad de mecanismos de acceso para las aplicaciones integradas en este servicio (lo que ayudará con la búsqueda en el catálogo). Sin embargo, hay que tener cuidado para alcanzar la mejor relación precio/rendimiento. Azure Cosmos DB permite el almacenamiento de los datos adjuntos de los documentos, pero existe un límite total por cuenta y puede ser una propuesta costosa. Una práctica común es almacenar los archivos de imagen reales en blobs e insertar un vínculo a ellos en la base de datos. En el caso de Azure Cosmos DB, esto implica crear un documento que contenga las propiedades del catálogo asociadas a esa imagen (como una SKU, una etiqueta, etc.) y un archivo adjunto que contenga la dirección URL del archivo de la imagen (por ejemplo, en Azure Blob Storage, OneDrive, etc.).
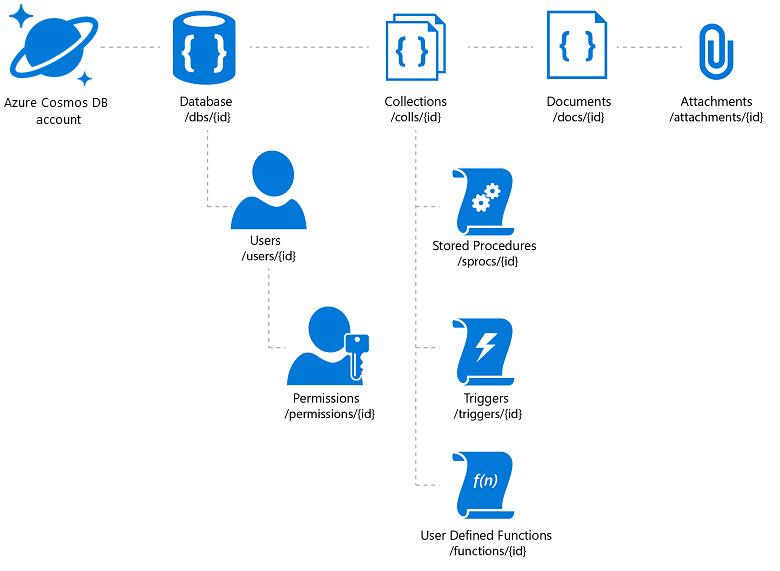
Figura 3: modelo jerárquico de recursos de Azure Cosmos DB
Si tiene previsto aprovechar las ventajas de la distribución global de Azure Cosmos DB, tenga en cuenta que se replicarán los documentos y datos adjuntos, pero no los archivos vinculados. Para ello, puede considerar una red de distribución de contenido.
Otras tecnologías aplicables son una combinación de Azure SQL Database (si es aceptable el esquema fijo) y blobs, o incluso tablas de Azure y blobs para almacenamiento y recuperación de forma rápida y económica.
Extracción de características y codificación
El proceso de codificación extrae características destacadas de las imágenes de la base de datos y asigna a cada una de ellas un "vector de características" disperso (un vector con muchos ceros) que puede tener miles de componentes. Este vector es una representación numérica de las características (por ejemplo, bordes o formas) que caracterizan la imagen. Es similar a un código.
Las técnicas de extracción de características usan normalmente mecanismos de aprendizaje por transferencia. Esto tiene lugar cuando selecciona una red neuronal previamente entrenada, ejecuta cada imagen a través de ella y almacena el vector de características de nuevo en la base de datos de imágenes. En este modo, el aprendizaje se "transfiere" desde la persona que haya entrenado la red. Microsoft ha desarrollado y publicado varias redes previamente entrenadas que se han usado ampliamente en las tareas de reconocimiento de imágenes, como ResNet50.
Dependiendo de la red neuronal, el vector de características será más o menos largo y disperso, de ahí que los requisitos de memoria y almacenamiento varíen.
Además, puede encontrarse con que diferentes redes son aplicables a diferentes categorías, de ahí que una implementación de la búsqueda visual pueda generar en realidad vectores de características de diverso tamaño.
Las redes neuronales previamente entrenadas son relativamente fáciles de usar pero podrían no ser tan eficaces como un modelo personalizado entrenado en el catálogo de imágenes. Estas redes están diseñadas normalmente para la clasificación de conjuntos de datos de referencia y no para realizar búsquedas en una colección de imágenes específica.
Como es posible que quiera modificarlas y volverlas a entrenar de modo que generen una predicción de categorías y un vector denso (es decir, más pequeño, no disperso), lo que sería muy útil para restringir el espacio de búsqueda, reduzca los requisitos de almacenamiento y memoria. Se pueden usar vectores binarios y con frecuencia se conocen como "hash semántico": un término derivado de las técnicas de codificación y recuperación de documentos. La representación binaria simplifica la realización de cálculos adicionales.

Figura 4: Modificaciones de ResNet para Visual Search (F. Yang et al, 2017)
Si elige modelos previamente entrenados o prefiere desarrollar los suyos propios, también deberá decidir dónde ejecutar la caracterización o el entrenamiento del modelo propiamente dicho.
Azure ofrece varias opciones: máquinas virtuales, Azure Batch, Batch AI o clústeres de Databricks. Sin embargo, en todos los casos, la mejor relación precio/rendimiento viene dada por el uso de GPU.
Microsoft ha anunciado recientemente la disponibilidad de matrices de puertas programables, o FPGA, para el cálculo rápido por una mínima parte del costo de GPU (proyecto Brainwave). Sin embargo, en el momento de escribir este artículo, esta oferta está limitada a determinadas arquitecturas de red, por lo que deberá evaluar su rendimiento detenidamente.
Medida o distancia de similitud
Cuando las imágenes se representan en el espacio del vector de característica, encontrar similitudes se convierte en una cuestión de definir una medida de distancia entre los puntos de dicho espacio. Una vez que se ha definido una distancia, puede calcular los clústeres de imágenes similares o definir matrices de similitud. En función de la métrica de distancia seleccionada, los resultados pueden variar. La medida de distancia euclidiana más común sobre vectores de números reales, por ejemplo, es fácil de entender: captura la magnitud de la distancia. Sin embargo, es bastante ineficaz en términos de cálculo.
La distancia coseno se usa a menudo para capturar la orientación del vector, en lugar de su magnitud.
Alternativas como la distancia de Hamming a través de representaciones binarias renuncian a cierta precisión a favor de eficiencia y velocidad.
La combinación de medida de distancia y tamaño de vector determinará la cantidad de cálculo y memoria que consumirá la búsqueda.
Búsqueda y clasificación
Una vez que se ha definido la similitud, es necesario idear un método eficaz para recuperar los N elementos más cercanos al que se ha pasado como entrada y, luego, devolver una lista de identificadores. Esto también se conoce como "clasificación de imágenes". En un conjunto de datos grande, el tiempo para calcular cada distancia es prohibitivo, por lo que se usan algoritmos vecinos aproximados. Para ellos existen varias bibliotecas de código abierto, por lo que no tendrá que escribir el código desde cero.
Por último, los requisitos de memoria y cálculo determinarán la elección de la tecnología de implementación para el modelo entrenado, así como la alta disponibilidad. Normalmente, el espacio de búsqueda se particionará y varias instancias del algoritmo de clasificación se ejecutarán en paralelo. Una opción que permite escalabilidad y disponibilidad son los clústeres de Azure Kubernetes. En ese caso, es conveniente implementar el modelo de clasificación en varios contenedores (de modo que cada uno controle una partición del espacio de búsqueda) y varios nodos (para lograr una alta disponibilidad).
Colaboradores
Microsoft mantiene este artículo. Originalmente lo escribieron los siguientes colaboradores.
Creadores de entidad de seguridad:
- Giovanni Marchetti | Administrador, arquitectos de soluciones de Azure
- Mariya Zorotovich | Responsable de experiencia del cliente, tecnología emergente y HLS
Otros colaboradores:
- Scott Seely | Arquitecto de software
Pasos siguientes
La implementación de la búsqueda visual no tiene que ser compleja. Puede usar Bing o crear la suya propia con los servicios de Azure, mientras se beneficia de la investigación sobre inteligencia artificial de Microsoft y las herramientas desarrolladas para esta tecnología.
Desarrollar
- Para empezar a crear un servicio personalizado, consulte Introducción a Bing Visual Search API.
- Para crear su primera solicitud, consulte las guías de inicio rápido: C# | Java | node.js | Python
- Familiarícese con la referencia de Visual Search API.
Información previa
- Deep Learning Image Segmentation (Segmentación de imágenes de aprendizaje profundo): documento de Microsoft que describe el proceso de separar las imágenes de los fondos.
- Visual Search at Ebay (Búsqueda visual en Ebay): investigación de la Universidad de Cornell.
- Visual Discovery at Pinterest (Detección visual en Pinterest): investigación de la Universidad de Cornell.
- Semantic Hashing (Hash semántico): investigación de la Universidad de Toronto.