Recuperación ante desastres y distribución geográfica en Azure Durable Functions
Microsoft se esfuerza por garantizar que los servicios de Azure siempre estén disponibles. Sin embargo, es posible que se produzcan interrupciones en el servicio. Si su aplicación requiere resistencia, Microsoft recomienda que la configure para usar la redundancia geográfica. Además, los clientes deben tener implementado un plan de recuperación ante desastres para controlar una interrupción del servicio regional. Parte importante de un plan de recuperación ante desastres es preparar la conmutación por error a la réplica secundaria de la aplicación y almacenamiento ante la eventualidad de que la réplica principal deje de estar disponible.
En Durable Functions, todos los estados se conservan en Azure Storage de manera predeterminada. Una central de tareas es un contenedor lógico para los recursos de Azure Storage que se usan para las orquestaciones y las entidades. Las funciones de orquestador, actividad y entidad solo pueden interactuar entre sí si pertenecen a la misma central de tareas. Este documento hará referencia a las centrales de tareas cuando se describan escenarios para hacer que estos recursos de Azure Storage tengan una alta disponibilidad.
Nota
En las instrucciones de este artículo se da por supuesto que usa el proveedor de Azure Storage predeterminado para almacenar el estado del entorno de ejecución de Durable Functions. Sin embargo, es posible configurar proveedores de almacenamiento alternativos que almacenen el estado en otro lugar, como una base de datos SQL Server. Es posible que se requieran diferentes estrategias de recuperación ante desastres y distribución geográfica para los proveedores de almacenamiento alternativos. Para obtener más información sobre los proveedores de almacenamiento alternativos, consulte la documentación sobre Proveedores de almacenamiento de Durable Functions.
Las orquestaciones y entidades se pueden desencadenar mediante funciones de cliente que se desencadenan mediante HTTP o uno de los otros tipos de desencadenadores de Azure Functions compatibles. También se pueden desencadenar mediante las API HTTP integradas. Para simplificarlo, este artículo se centrará en escenarios que involucren a Azure Storage y desencadenadores de función basados en HTTP, así como opciones para aumentar la disponibilidad y minimizar el tiempo de inactividad durante las actividades de recuperación ante desastres. Otros tipos de desencadenadores, como los desencadenadores de Service Bus o Azure Cosmos DB, no se tratarán a explícitamente.
Los siguientes escenarios se basan en configuraciones activas/pasivas, ya que se guían por el uso de Azure Storage. Este patrón consiste en implementar una aplicación de función de copia de seguridad (pasiva) en otra región. Traffic Manager supervisará la disponibilidad HTTP de la aplicación de función principal (activa). Si se produce un error en la principal, conmutará por error a la aplicación de función de copia de seguridad. Para más información, consulte el Método de enrutamiento de tráfico Prioridad de Azure Traffic Manager.
Nota
- La configuración activa/pasiva propuesta garantiza que el cliente siempre puede desencadenar nuevas orquestaciones a través de HTTP. Sin embargo, como consecuencia de tener dos aplicaciones de funciones que comparten el mismo central de tareas en almacenamiento, algunas transacciones de almacenamiento en segundo plano se distribuirán entre ambos. Por lo tanto, esta configuración implica algunos costos de salida adicionales a la aplicación de funciones secundaria.
- La cuenta de almacenamiento subyacente y la central de tareas se crean en la región primaria, y las comparten ambas aplicaciones de función.
- Todas las aplicaciones de funciones que se implementan de forma redundante deben compartir las mismas claves de acceso de la función en caso de que se activen a través de HTTP. Functions Runtime expone una API de administración que permite a los consumidores agregar, eliminar y actualizar las teclas de función mediante programación. También puede administrar las claves mediante las API de Azure Resource Manager.
Escenario 1: proceso con almacenamiento compartido y equilibrio de carga
Si se produce un error en la infraestructura de proceso de Azure, la aplicación de función podría no estar disponible. Para minimizar este riesgo de tiempo de inactividad, en este escenario se utilizan dos aplicaciones de función implementadas en regiones diferentes. Traffic Manager está configurado para detectar problemas en la aplicación de función principal y redirigir el tráfico automáticamente a la aplicación de función de la región secundaria. Esta aplicación de función comparte la cuenta de Azure Storage y la central de tareas. Por lo tanto, el estado de las aplicaciones de función no se pierde y el trabajo se reinicia con normalidad. Una vez restaurado el estado en la región primaria, Azure Traffic Manager empezará automáticamente a enrutar las solicitudes a esa aplicación de función.
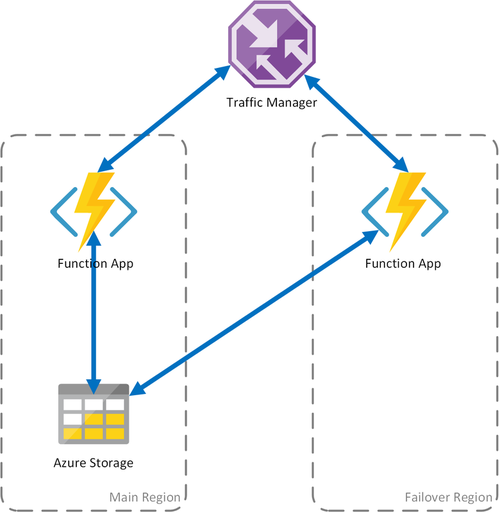
Este escenario de implementación supone varias ventajas:
- Si se produce un error en la infraestructura de proceso, el trabajo se puede reanudar en la región en la que se conmutó por error sin pérdida de datos.
- Traffic Manager se encarga de la conmutación por error a la aplicación de funciones correcta automáticamente.
- Traffic Manager restablece automáticamente el tráfico a la aplicación de función principal una vez corregida la interrupción.
Sin embargo, con este escenario, valore:
- Si la aplicación de funciones se implementó mediante un plan de App Service específico, la replicación de la infraestructura de proceso en el centro de datos de conmutación por error aumentará los costos.
- En este escenario se tratan las interrupciones en la infraestructura de proceso, pero la cuenta de Storage sigue siendo el único punto de error de la función de aplicación. Si sucede una interrupción en Storage, la aplicación sufre de tiempo de inactividad.
- Si la aplicación de función se conmuta por error, la latencia aumentará, ya que se accederá a las cuentas de Storage de las distintas regiones.
- Acceder al servicio de almacenamiento desde una región distinta a donde se ubica implica mayores costos debido al tráfico de salida de la red.
- Este escenario depende de Traffic Manager. Teniendo en cuenta cómo funciona Traffic Manager, una aplicación cliente que consuma una instancia de Durable Functions puede tardar un tiempo en necesitar consultar de nuevo la dirección de la aplicación de función de Traffic Manager.
Nota
A partir de la versión v2.3.0 de la extensión de Durable Functions, se pueden ejecutar de forma segura dos aplicaciones de funciones a la vez con la misma cuenta de almacenamiento y la misma configuración de central de tareas. La primera aplicación que se inicie adquirirá una concesión de blobs en el nivel de aplicación que impedirá que otras aplicaciones roben mensajes de las colas del centro de tareas. Si esta primera aplicación deja de ejecutarse, la concesión expirará y podrá adquirirla una segunda aplicación, que después seguirá procesando los mensajes del centro de tareas.
Antes de la versión v2.3.0, las aplicaciones de funciones que se hayan configurado para usar la misma cuenta de almacenamiento procesarán los mensajes y actualizarán los artefactos de almacenamiento simultáneamente, lo que provocará mayores latencias y costos de salida. Si las aplicaciones principal y de réplica tienen un código diferente implementado, incluso de forma temporal, las orquestaciones también podrían no ejecutarse correctamente debido a las incoherencias en las funciones de orquestador de las dos aplicaciones. Por lo tanto, se recomienda que todas las aplicaciones que requieren distribución geográfica con fines de recuperación ante desastres usen la versión v2.3.0 o una versión superior de la extensión de Durable Functions.
Escenario 2: proceso con almacenamiento regional y equilibrio de carga
En el escenario anterior se cubre solo el caso de error en la infraestructura de proceso. Si se produce un error en el servicio de almacenamiento, se producirá una interrupción en la aplicación de función. Para garantizar el funcionamiento continuo de Durable Functions, para este escenario se utiliza una cuenta de almacenamiento local en cada región donde se implementan las aplicaciones de función.
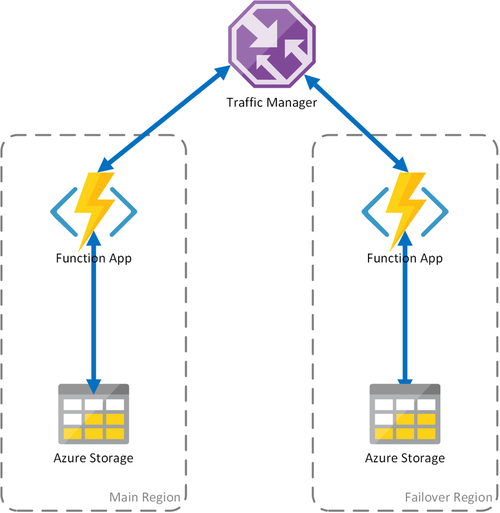
Este método agrega mejoras al escenario anterior:
- Si se produce un error en la aplicación de función, Traffic Manager se encarga de la conmutación por error a la región secundaria. Sin embargo, dado que la aplicación de función se basa en su propia cuenta de almacenamiento, Durable Functions continuará funcionando.
- Durante la conmutación por error no hay latencia adicional en la región en la que se realiza, ya que la aplicación de funciones y la cuenta de almacenamiento se ubican en el mismo sitio.
- Un error de la capa de almacenamiento provocará errores en Durable Functions que, a su vez, desencadenarán el redireccionamiento a la región de conmutación por error. Una vez más, como la aplicación de función y el almacenamiento están aislados por región, Durable Functions continúa funcionando.
Consideraciones importantes sobre este escenario:
- Si la aplicación de funciones se implementó mediante un plan de App Service específico, la replicación de la infraestructura de proceso en el centro de datos de conmutación por error aumentará los costos.
- El estado actual no se ha conmutado por error, lo que implica que las orquestaciones y entidades existentes estarán en pausa y no estarán disponibles hasta que se recupere la región principal.
En pocas palabras, la contrapartida entre el primer y el segundo escenario es que se conserva la latencia y se reducen los costos de salida, aunque las orquestaciones y entidades existentes no estarán disponibles durante el tiempo de inactividad. Si estas soluciones intermedias son aceptables o no dependerá de los requisitos de la aplicación.
Escenario 3: proceso con almacenamiento con redundancia geográfica compartido y equilibrio de carga
Este escenario es una modificación del primer escenario en el que se implementa una cuenta de almacenamiento compartido. La diferencia principal es que la cuenta de almacenamiento se crea con la replicación geográfica habilitada. Funcionalmente, este escenario proporciona las mismas ventajas que el número 1, pero incorpora ventajas de recuperación de datos adicionales:
- El almacenamiento con redundancia geográfica (GRS) y el almacenamiento con redundancia geográfica y acceso de lectura (RA-GRS) maximizan la disponibilidad de la cuenta de almacenamiento.
- Si se produce una interrupción regional del servicio Storage, puede iniciar manualmente una conmutación por error a la réplica secundaria. En casos extremos en los que se pierde una región debido a un desastre importante, Microsoft puede iniciar una conmutación por error regional. En este caso, no se requieren acciones por su parte.
- Cuando se produzca una conmutación por error, el estado de Durable Functions se conservará hasta la última replicación de la cuenta de almacenamiento, que normalmente se producirá cada pocos minutos.
Al igual que con los demás escenarios, hay consideraciones importantes:
- Una conmutación por error a la réplica puede tardar un momento. Hasta que se complete la conmutación por error y se actualicen los registros DNS de Azure Storage, la aplicación de funciones sufrirá una interrupción.
- El uso de cuentas de almacenamiento con replicación geográfica no aumenta el costo.
- La replicación GRS copia los datos de forma asincrónica. Algunas de las últimas transacciones pueden perderse a causa de la latencia del proceso de replicación.
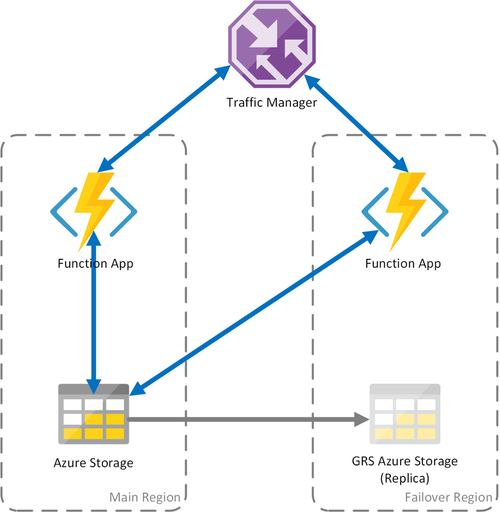
Nota:
Como se describe en el escenario 1, se recomienda que las aplicaciones de funciones implementadas con esta estrategia usen la versión v2.3.0 o una posterior de la extensión de Durable Functions.
Para más información, consulte la documentación Recuperación ante desastres y conmutación por error de la cuenta de almacenamiento en Azure Storage.