Proceso de las operaciones de aprendizaje automático
Ciclo de desarrollo del modelo
El proceso de desarrollo debe generar los resultados siguientes:
El entrenamiento es automático y los modelos se validan, lo que incluye la funcionalidad y el rendimiento de las pruebas (por ejemplo, el uso de métricas de precisión).
La implementación en la infraestructura que se usa para la inferencia (incluida la supervisión) está automatizada.
Los mecanismos crean un registro de auditoría de datos integral. El reentrenamiento automático de los modelos se produce cuando hay un desfase de datos a lo largo del tiempo, lo que resulta pertinente para sistemas basados en aprendizaje automático a gran escala.
En el siguiente diagrama se muestra el ciclo de vida de la implementación de un sistema de aprendizaje automático:
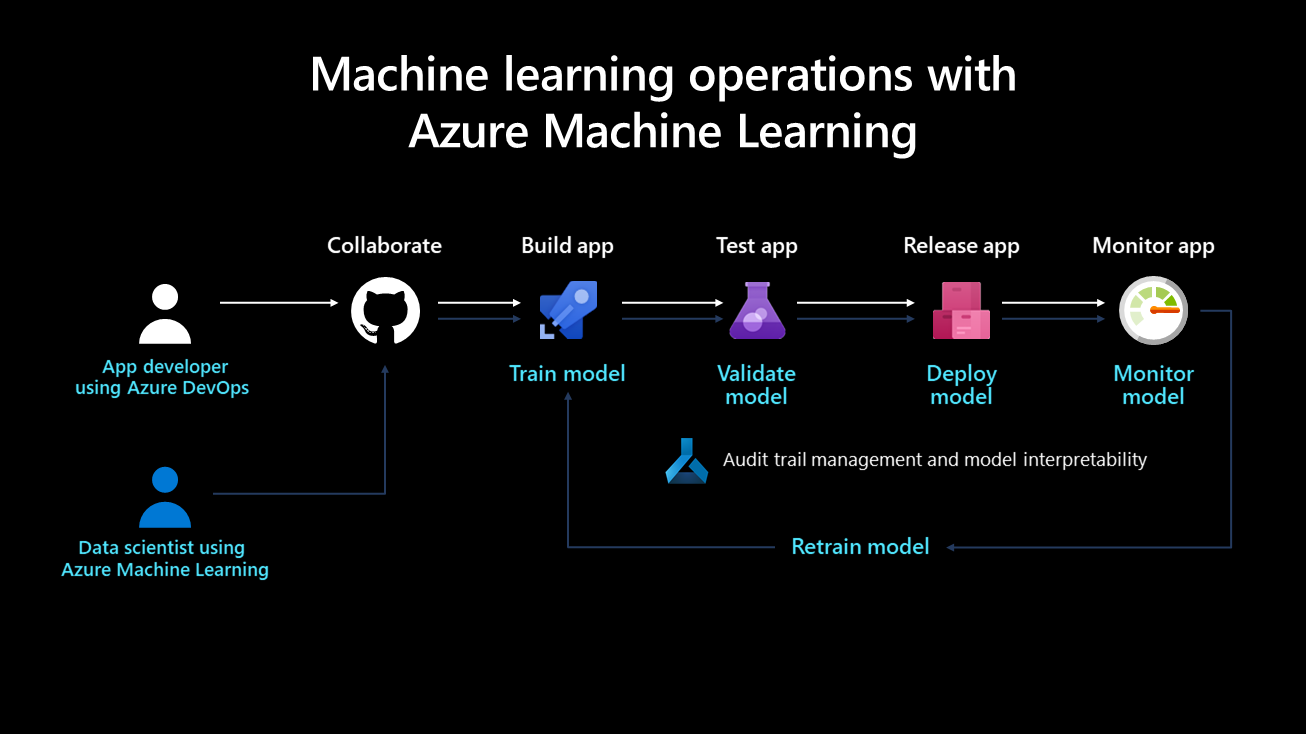
Una vez desarrollado, se entrena, valida, implementa y supervisa un modelo de aprendizaje automático. Desde el punto de vista de la organización y en el nivel técnico y administrativo, es importante definir quién se encarga de este proceso y lo implementa. En las empresas más grandes, un científico de datos podría encargarse de los pasos de entrenamiento y validación del modelo, mientras que un ingeniero de aprendizaje automático podría ocuparse de los pasos restantes. En empresas más pequeñas, un científico de datos podría encargarse de todos los pasos.
Entrenamiento del modelo
En este paso, un conjunto de datos de entrenamiento entrena el modelo de aprendizaje automático. El código de entrenamiento tiene control de versiones y es reutilizable, y esta característica optimiza los clics de botón y los desencadenadores de eventos (p. ej., una nueva versión de los datos que pasan a estar disponibles) a fin de automatizar cómo se entrena el modelo.
Validación del modelo
Este paso usa métricas establecidas, como una métrica de precisión, para validar automáticamente el modelo recién entrenado y compararlo con los más antiguos. ¿La precisión aumentó? En caso afirmativo, este modelo podría registrarse en el registro de modelos a fin de garantizar que se puede usar en los pasos siguientes. Si la precisión del nuevo modelo es peor, se puede avisar a un científico de datos para que investigue el motivo o descartar el modelo recién entrenado.
Implementación del modelo
Implemente el modelo como un servicio de API para aplicaciones web en el paso de implementación. Este enfoque permite escalar y actualizar el modelo de forma independiente de las aplicaciones. Como alternativa, el modelo se puede utilizar para realizar la puntuación por lotes, en la que se usa una vez o periódicamente para calcular las predicciones en los nuevos puntos de datos. Esto resulta útil cuando se deben procesar grandes cantidades de datos de forma asincrónica. Puede encontrar más detalles sobre los modelos de implementación en la página inferencia de aprendizaje automático durante la implementación .
Supervisión del modelo
Es necesario supervisar el modelo por dos motivos clave. En primer lugar, la supervisión del modelo permite garantizar que sea técnicamente funcional, por ejemplo, que pueda generar predicciones. Esto es importante si las aplicaciones de una organización dependen del modelo y lo usan en tiempo real. La supervisión del modelo también ayuda a las organizaciones a medir si genera predicciones útiles continuamente. Esto podría no resultar útil cuando se produce el desfase de datos, por ejemplo, cuando los datos usados para entrenar el modelo difieren significativamente de los datos que se envían a este durante la fase de predicción. Por ejemplo, un modelo entrenado para recomendar productos a personas jóvenes podría producir resultados no deseados si recomienda productos a personas de otro grupo de edad. La supervisión de modelos con el desfase de datos puede detectar este tipo de discrepancia, alertar a los ingenieros de aprendizaje automático y volver a entrenar de manera automática el modelo con datos más pertinentes o más recientes.
Cómo supervisar los modelos
Dado que el desfase de datos, la estacionalidad o la arquitectura más reciente optimizada para mejorar el rendimiento pueden provocar que el rendimiento del modelo varíe a lo largo del tiempo, es importante establecer un proceso para implementar modelos continuamente. Algunos de los procedimientos recomendados son los siguientes:
Propiedad: se debe asignar un propietario al proceso de supervisión del rendimiento del modelo a fin de administrar activamente su rendimiento.
Canalizaciones de versión: configure una canalización de versión en Azure DevOps primero y establezca el desencadenador en el registro de modelo. Cuando se registra un nuevo modelo en el registro, la canalización de versión se desencadena y se aprueba en un proceso de implementación.
Requisitos previos para volver a entrenar modelos
La recopilación de datos de modelos en producción es un requisito previo para volver a entrenar modelos en un marco de desarrollo continuo o de integración continua, y este proceso usa datos de entrada de solicitudes de puntuación. Actualmente, esta funcionalidad está limitada a los datos tabulares que se pueden analizar como JSON con un formato y manipulación mínimos. Se excluyen los vídeos, los audios y las imágenes. Esta funcionalidad está disponible para los modelos en Azure Kubernetes Service (AKS). Los datos recopilados se almacenan en un blob de Azure.
Para preparar el reentrenamiento de un modelo, haga lo siguiente:
Supervise el desfase de datos de los datos de entrada recopilados. La configuración de un proceso de supervisión requiere la extracción de la marca de tiempo de los datos de producción. Esto se requiere para comparar los datos de producción y los datos de la base de referencia (los datos de entrenamiento que se usan para generar el modelo). La mejor manera de supervisar el desfase de datos es a través de Azure Monitor Application Insights. Esta característica proporciona una alerta que puede desencadenar acciones, como correo electrónico, texto SMS, inserciones o Azure Functions. Debe habilitar Application Insights para registrar datos.
Analice los datos recopilados. Asegúrese de recopilar datos de los modelos en producción e incluya los resultados en el script de puntuación del modelo. Recopile todas las características usadas para la puntuación del modelo, ya que ello garantiza que existen todas las características necesarias y se pueden usar como datos de entrenamiento.
Decida si es necesario volver a entrenarlo con los datos recopilados. Hay muchos factores que causan el desfase de datos, incluidos los problemas del sensor en la estacionalidad, los cambios en el comportamiento del usuario y los problemas de calidad de los datos relacionados con el origen de datos. No es necesario volver a entrenar los modelos en todos los casos, por lo que, antes de hacerlo, se recomienda investigar y comprender la causa del desfase de datos.
Vuelva a entrenar el modelo. El entrenamiento del modelo ya debe estar automatizado, y este paso implica desencadenar el paso de entrenamiento actual. Esto podría ser cuando se ha detectado un desfase de datos (y no está relacionado con un problema de datos) o cuando un ingeniero de datos ha publicado una nueva versión de un conjunto de datos. En función del caso de uso, los usuarios pueden automatizar o supervisar por completo estos pasos. Por ejemplo, aunque puede que algunos casos de uso, como las recomendaciones de productos, se ejecuten de forma autónoma en el futuro, otros relacionados con finanzas podrían tener en cuenta estándares, como la equidad y la transparencia del modelo, y requerir que un usuario apruebe modelos recién entrenados.
En primer lugar, es habitual que una organización solo automatice el entrenamiento y la implementación de un modelo, pero no los pasos de validación, supervisión y reentrenamiento, que se realizan manualmente. Finalmente, los pasos de automatización de estas tareas pueden progresar hasta que se alcance el estado deseado. Las operaciones de DevOps y aprendizaje automático son conceptos que se desarrollan a lo largo del tiempo, y las organizaciones deben tener en cuenta su evolución.
El ciclo de vida del proceso de ciencia de datos en equipo
El proceso de ciencia de datos en equipo (TDSP) proporciona un ciclo de vida para estructurar el desarrollo de los proyectos de ciencia de datos. El ciclo de vida describe las fases principales por las que pasan normalmente los proyectos, a menudo de forma iterativa:
- Conocimiento del negocio
- Adquisición y comprensión de los datos
- Modelado
- Implementación
En el tema El ciclo de vida del proceso de ciencia de datos en equipo se describen los objetivos, las tareas y los artefactos de documentación de cada fase del ciclo de vida de TDSP.
Roles y las actividades de las operaciones de aprendizaje automático
Según el ciclo de vida de TDSP, los roles clave del proyecto de IA son el ingeniero de datos, el científico de datos y el ingeniero de operaciones de aprendizaje automático. Estos roles son fundamentales para el éxito del proyecto y deben funcionar juntos a fin de lograr soluciones precisas, repetibles, escalables y listas para la producción.

Ingeniero de datos: este rol ingiere, valida y limpia los datos. Una vez que se refinan los datos, se catalogan y se ponen a disposición de los científicos de datos para su uso. En esta fase, es importante explorar y analizar los datos duplicados, quitar los valores atípicos e identificar los datos que faltan. Estas actividades se deben definir en los pasos de canalización y se ejecutan a medida que se realiza el procesamiento previo de la canalización de entrenamiento. Los nombres únicos y específicos deben asignarse a las características básicas y generadas.
Ingeniero de datos (o inteligencia de IA): este rol navega por el proceso de canalización de entrenamiento y evalúa los modelos. Un científico de datos recibe datos del ingeniero de datos e identifica patrones y relaciones en estos, posiblemente seleccionando o generando características para el experimento. Dado que la ingeniería de características desempeña un papel importante en la creación de un modelo generalizado de sonido, es fundamental que esta fase se complete lo mejor posible. Se pueden realizar varios experimentos con distintos algoritmos e hiperparámetros. Las herramientas de Azure, como el aprendizaje automático automatizado, pueden automatizar esta tarea, lo que también puede permitir realizar un sobreajuste o un ajuste insuficiente en un modelo. A continuación, un modelo entrenado correctamente se registra en el registro del modelo. El modelo debe tener un nombre único y específico, y se debe conservar un historial de versiones con fines de rastreabilidad.
Ingeniero de operaciones de aprendizaje automático: este rol crea canalizaciones integrales para la integración y entrega continuas. Incluye el empaquetado del modelo en una imagen de Docker, la validación y generación de perfiles del modelo, la espera de la aprobación de una parte interesada y la implementación del modelo en un servicio de orquestación de contenedores como AKS. Se pueden establecer varios desencadenadores durante la integración continua, y el código del modelo puede desencadenar la canalización de entrenamiento y la canalización de versión posteriormente.
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de