Uso de un contenedor de Visión de Azure AI con Kubernetes y Helm
Una opción para administrar los contenedores de Visión de Azure AI en el entorno local es usar Kubernetes y Helm. Vamos a crear un paquete de Kubernetes usando Kubernetes y Helm para definir una imagen de contenedor de Visión de Azure AI. Este paquete se va a implementar en un clúster de Kubernetes en el entorno local. Por último, exploraremos cómo probar los servicios implementados. Para más información sobre la ejecución de contenedores de Docker sin orquestación de Kubernetes, consulte Instalación y ejecución de contenedores de Visión de Azure AI.
Requisitos previos
Estos son los requisitos previos para poder usar contenedores de Visión de Azure AI en el entorno local:
| Obligatorio | Propósito |
|---|---|
| Cuenta de Azure | Si no tiene una suscripción a Azure, cree una cuenta gratuita antes de empezar. |
| CLI de Kubernetes | La CLI de Kubernetes es necesaria para administrar las credenciales compartidas desde el registro de contenedor. Kubernetes también se necesita antes que Helm, que es el administrador de paquetes de Kubernetes. |
| CLI de Helm | Instale la CLI de Helm, que se usa para instalar un gráfico de Helm (definición de paquete de contenedor). |
| Recurso de Computer Vision | Para poder usar el contenedor, debe tener: Un recurso de Computer Vision y la clave de API asociada con el URI del punto de conexión. Ambos valores están disponibles en las páginas de introducción y claves del recurso y son necesarios para iniciar el contenedor. {API_KEY} : una de las dos claves de recurso disponibles en la página Claves {ENDPOINT_URI} : el punto de conexión tal como se proporciona en la página de Información general. |
Recopilación de todos los parámetros obligatorios
Se requieren tres parámetros principales para todos los contenedores Azure AI. Los Términos de licencia del software de Microsoft deben estar presentes con el valor Acepto. También se necesitan un URI de punto de conexión y una clave de API.
URI de punto de conexión
El valor de {ENDPOINT_URI} está disponible en la página Información general de Azure Portal del recurso de servicios de Azure AI correspondiente. Vaya a la página Información general, mantenga el puntero sobre el punto de conexión y aparecerá un icono Copiar en el Portapapeles. Copie y use el punto de conexión cuando sea necesario.
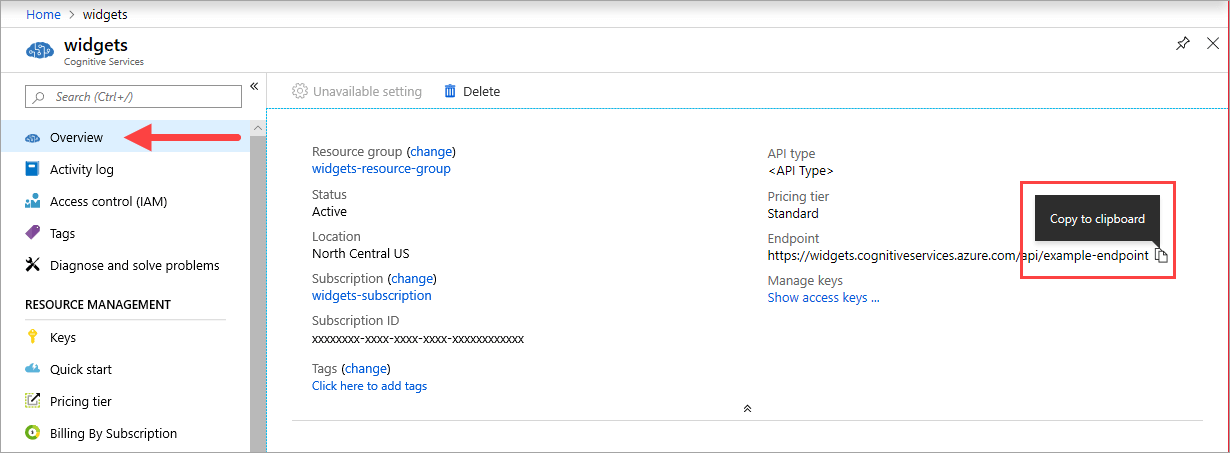
Teclas
El valor {API_KEY} se usa para iniciar el contenedor y está disponible en la página Claves de Azure Portal del recurso de servicios de Azure AI correspondiente. Vaya a la página Claves y seleccione el icono Copiar en el Portapapeles.
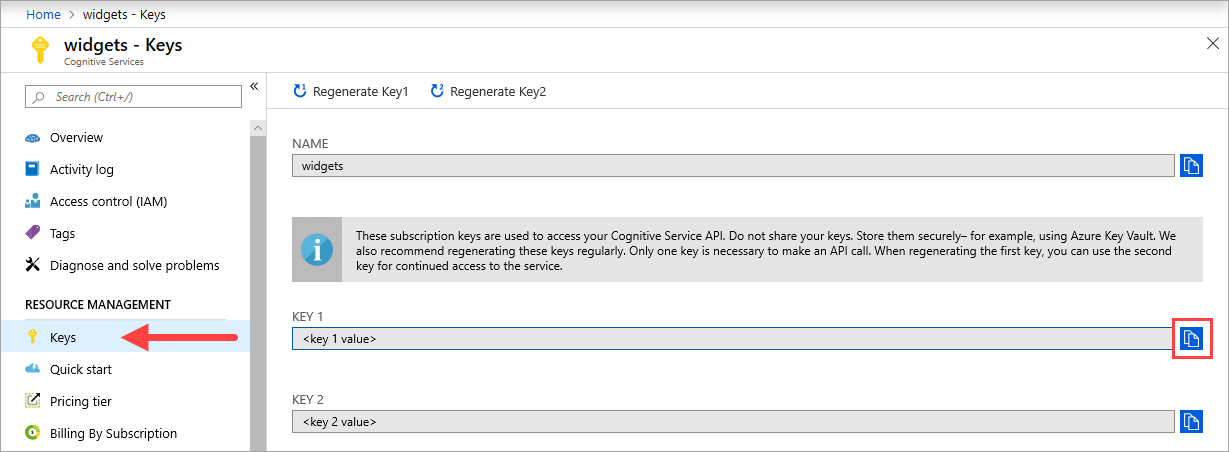
Importante
Estas claves de suscripción se usan para acceder a la API de servicios de Azure AI. No comparta sus claves. Almacénelas de forma segura. Por ejemplo, use Azure Key Vault. También se recomienda volver a generar estas claves con regularidad. Solo se necesita una clave para realizar una llamada API. Al volver a generar la primera clave, puede usar la segunda para seguir teniendo acceso al servicio.
El equipo host
El host es un equipo basado en x64 que ejecuta el contenedor de Docker. Puede ser un equipo del entorno local o un servicio de hospedaje de Docker incluido en Azure, como:
- Azure Kubernetes Service.
- Azure Container Instances.
- Un clúster de Kubernetes implementado en Azure Stack. Para obtener más información, consulte Implementación de Kubernetes en Azure Stack.
Recomendaciones y requisitos del contenedor
Nota
Los requisitos y las recomendaciones se basan en pruebas comparativas con una única solicitud por segundo, con una imagen de 523 kB de una carta comercial escaneada que contiene 29 líneas y 803 caracteres en total. La configuración recomendada dio como resultado una respuesta aproximadamente dos veces más rápida en comparación con la configuración mínima.
En la tabla siguiente se describe la asignación mínima y recomendada de recursos para cada contenedor OCR de Read.
| Contenedor | Mínima | Recomendado |
|---|---|---|
| Read 3.2 2022-04-30 | 4 núcleos, 8 GB de memoria | 8 núcleos, 16 GB de memoria |
| Read 3.2 2021-04-12 | 4 núcleos, 16 GB de memoria | 8 núcleos, 24 GB de memoria |
- Cada núcleo debe ser de 2,6 gigahercios (GHz) como mínimo.
El núcleo y la memoria se corresponden con los valores de --cpus y --memory que se usan como parte del comando docker run.
Conectar al clúster de Kubernetes
Se espera que el equipo host tenga un clúster de Kubernetes disponible. Vea este tutorial sobre la implementación de un clúster de Kubernetes para lograr un reconocimiento conceptual de cómo implementar un clúster de Kubernetes en un equipo host. Encontrará más información sobre las implementaciones en la documentación de Kubernetes.
Configuración de los valores del gráfico de Helm para la implementación
Empiece por crear una carpeta llamada read. Luego pegue el siguiente contenido de YAML en un nuevo archivo denominado chart.yaml:
apiVersion: v2
name: read
version: 1.0.0
description: A Helm chart to deploy the Read OCR container to a Kubernetes cluster
dependencies:
- name: rabbitmq
condition: read.image.args.rabbitmq.enabled
version: ^6.12.0
repository: https://kubernetes-charts.storage.googleapis.com/
- name: redis
condition: read.image.args.redis.enabled
version: ^6.0.0
repository: https://kubernetes-charts.storage.googleapis.com/
Para configurar los valores predeterminados del gráfico de Helm, copie y pegue el contenido de YAML en un archivo denominado values.yaml. Reemplace los comentarios # {ENDPOINT_URI} y # {API_KEY} por sus propios valores. Configure resultExpirationPeriod, Redis y RabbitMQ si es necesario.
# These settings are deployment specific and users can provide customizations
read:
enabled: true
image:
name: cognitive-services-read
registry: mcr.microsoft.com/
repository: azure-cognitive-services/vision/read
tag: 3.2-preview.1
args:
eula: accept
billing: # {ENDPOINT_URI}
apikey: # {API_KEY}
# Result expiration period setting. Specify when the system should clean up recognition results.
# For example, resultExpirationPeriod=1, the system will clear the recognition result 1hr after the process.
# resultExpirationPeriod=0, the system will clear the recognition result after result retrieval.
resultExpirationPeriod: 1
# Redis storage, if configured, will be used by read OCR container to store result records.
# A cache is required if multiple read OCR containers are placed behind load balancer.
redis:
enabled: false # {true/false}
password: password
# RabbitMQ is used for dispatching tasks. This can be useful when multiple read OCR containers are
# placed behind load balancer.
rabbitmq:
enabled: false # {true/false}
rabbitmq:
username: user
password: password
Importante
Si no se proporcionan los valores
billingyapikey, los servicios expiran pasados 15 minutos. Del mismo modo, se produce un error en la comprobación porque los servicios no están disponibles.Si implementa varios contenedores OCR de lectura detrás de un equilibrador de carga en, por ejemplo, Docker Compose o Kubernetes, debe tener una caché externa. Dado que el contenedor de procesamiento y el contenedor de la solicitud GET podrían no ser los mismos, una caché externa almacena los resultados y los comparte entre contenedores. Para más información sobre la configuración de caché, consulte Configuración de contenedores de Docker de Visión de Azure AI.
Cree una carpeta plantillas en el directorio lectura. Copie y pegue el siguiente YAML en un archivo denominado deployment.yaml. El archivo deployment.yaml servirá como una plantilla de Helm.
Las plantillas generan archivos de manifiesto, que son descripciones de recursos con formato YAML que Kubernetes puede entender. -Guía de plantilla de gráfico de Helm
apiVersion: apps/v1
kind: Deployment
metadata:
name: read
labels:
app: read-deployment
spec:
selector:
matchLabels:
app: read-app
template:
metadata:
labels:
app: read-app
spec:
containers:
- name: {{.Values.read.image.name}}
image: {{.Values.read.image.registry}}{{.Values.read.image.repository}}
ports:
- containerPort: 5000
env:
- name: EULA
value: {{.Values.read.image.args.eula}}
- name: billing
value: {{.Values.read.image.args.billing}}
- name: apikey
value: {{.Values.read.image.args.apikey}}
args:
- ReadEngineConfig:ResultExpirationPeriod={{ .Values.read.image.args.resultExpirationPeriod }}
{{- if .Values.read.image.args.rabbitmq.enabled }}
- Queue:RabbitMQ:HostName={{ include "rabbitmq.hostname" . }}
- Queue:RabbitMQ:Username={{ .Values.read.image.args.rabbitmq.rabbitmq.username }}
- Queue:RabbitMQ:Password={{ .Values.read.image.args.rabbitmq.rabbitmq.password }}
{{- end }}
{{- if .Values.read.image.args.redis.enabled }}
- Cache:Redis:Configuration={{ include "redis.connStr" . }}
{{- end }}
imagePullSecrets:
- name: {{.Values.read.image.pullSecret}}
---
apiVersion: v1
kind: Service
metadata:
name: read-service
spec:
type: LoadBalancer
ports:
- port: 5000
selector:
app: read-app
En la misma carpeta templates, copie y pegue las siguientes funciones auxiliares en helpers.tpl. helpers.tpl define funciones útiles para ayudar a generar la plantilla de Helm.
{{- define "rabbitmq.hostname" -}}
{{- printf "%s-rabbitmq" .Release.Name -}}
{{- end -}}
{{- define "redis.connStr" -}}
{{- $hostMain := printf "%s-redis-master:6379" .Release.Name }}
{{- $hostReplica := printf "%s-redis-replica:6379" .Release.Name -}}
{{- $passWord := printf "password=%s" .Values.read.image.args.redis.password -}}
{{- $connTail := "ssl=False,abortConnect=False" -}}
{{- printf "%s,%s,%s,%s" $hostMain $hostReplica $passWord $connTail -}}
{{- end -}}
La plantilla especifica un servicio de equilibrador de carga y la implementación del contenedor o la imagen para lectura.
Paquete de Kubernetes (gráfico de Helm)
El gráfico de Helm contiene la configuración de las imágenes de Docker que se van a extraer del registro de contenedor mcr.microsoft.com.
Un gráfico de Helm es una colección de archivos que describen un conjunto relacionado de recursos de Kubernetes. Un solo gráfico se podría usar para implementar algo sencillo, como un pod almacenado en memoria, o complejo, como una pila de aplicación web completa con servidores HTTP, bases de datos, memorias caché, etc.
Los gráficos de Helm proporcionados extraen las imágenes de Docker del servicio Visión de Azure AI y el servicio correspondiente del registro de contenedor mcr.microsoft.com.
Instalación del gráfico de Helm en el clúster de Kubernetes
Para instalar el gráfico de Helm, es necesario ejecutar el comando helm install. Asegúrese de ejecutar el comando de instalación desde el directorio situado encima de la carpeta read.
helm install read ./read
Este es el resultado de ejemplo que se puede ver tras una ejecución de instalación correcta:
NAME: read
LAST DEPLOYED: Thu Sep 04 13:24:06 2019
NAMESPACE: default
STATUS: DEPLOYED
RESOURCES:
==> v1/Pod(related)
NAME READY STATUS RESTARTS AGE
read-57cb76bcf7-45sdh 0/1 ContainerCreating 0 0s
==> v1/Service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
read LoadBalancer 10.110.44.86 localhost 5000:31301/TCP 0s
==> v1beta1/Deployment
NAME READY UP-TO-DATE AVAILABLE AGE
read 0/1 1 0 0s
La implementación de Kubernetes puede tardar varios minutos en completarse. Para confirmar que los pods y los servicios se han implementado correctamente y están disponibles, ejecute el siguiente comando:
kubectl get all
Debería ver algo parecido al resultado siguiente:
kubectl get all
NAME READY STATUS RESTARTS AGE
pod/read-57cb76bcf7-45sdh 1/1 Running 0 17s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 45h
service/read LoadBalancer 10.110.44.86 localhost 5000:31301/TCP 17s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/read 1/1 1 1 17s
NAME DESIRED CURRENT READY AGE
replicaset.apps/read-57cb76bcf7 1 1 1 17s
Implementación de varios contenedores de la versión 3 en el clúster de Kubernetes
A partir de la versión 3 del contenedor, puede utilizar los contenedores en paralelo tanto a nivel de tarea como de página.
Por naturaleza, cada contenedor de la versión 3 tiene un distribuidor y un trabajo de reconocimiento. El primero es responsable de dividir una tarea de varias páginas en varias subtareas de una sola página. El trabajo de reconocimiento está optimizado para reconocer documentos de una sola página. Para lograr el paralelismo en el nivel de página, implemente varios contenedores de la versión 3 detrás de un equilibrador de carga y deje que los contenedores compartan una cola y un almacenamiento universales.
Nota
Actualmente solo se admiten Azure Storage y Azure Queue.
El contenedor que recibe la solicitud puede dividir la tarea en subtareas de una sola página y agregarlas a la cola universal. Cualquier trabajo de reconocimiento de un contenedor menos ocupado puede consumir subtareas de una sola página de la cola, realizar el reconocimiento y cargar el resultado en el almacenamiento. El rendimiento se puede mejorar hasta n veces, en función del número de contenedores que se implementen.
El contenedor v3 expone la API de sondeo de ejecución en la ruta de acceso /ContainerLiveness. Use el ejemplo de implementación siguiente para configurar un sondeo de ejecución para Kubernetes.
Copie y pegue el siguiente YAML en un archivo denominado deployment.yaml. Reemplace los comentarios # {ENDPOINT_URI} y # {API_KEY} por sus propios valores. Reemplace el comentario # {AZURE_STORAGE_CONNECTION_STRING} por su cadena de conexión de Azure Storage. Configure el número de replicas que desee, que se establece en 3 en el ejemplo siguiente.
apiVersion: apps/v1
kind: Deployment
metadata:
name: read
labels:
app: read-deployment
spec:
selector:
matchLabels:
app: read-app
replicas: # {NUMBER_OF_READ_CONTAINERS}
template:
metadata:
labels:
app: read-app
spec:
containers:
- name: cognitive-services-read
image: mcr.microsoft.com/azure-cognitive-services/vision/read
ports:
- containerPort: 5000
env:
- name: EULA
value: accept
- name: billing
value: # {ENDPOINT_URI}
- name: apikey
value: # {API_KEY}
- name: Storage__ObjectStore__AzureBlob__ConnectionString
value: # {AZURE_STORAGE_CONNECTION_STRING}
- name: Queue__Azure__ConnectionString
value: # {AZURE_STORAGE_CONNECTION_STRING}
livenessProbe:
httpGet:
path: /ContainerLiveness
port: 5000
initialDelaySeconds: 60
periodSeconds: 60
timeoutSeconds: 20
---
apiVersion: v1
kind: Service
metadata:
name: azure-cognitive-service-read
spec:
type: LoadBalancer
ports:
- port: 5000
targetPort: 5000
selector:
app: read-app
Ejecute el siguiente comando.
kubectl apply -f deployment.yaml
A continuación hay un resultado de ejemplo que se puede ver tras la ejecución de una implementación correcta:
deployment.apps/read created
service/azure-cognitive-service-read created
La implementación de Kubernetes puede tardar varios minutos en completarse. Para confirmar que tanto los pods como los servicios se han implementado correctamente y están disponibles, ejecute el siguiente comando:
kubectl get all
Debería ver una salida de la consola similar a esta:
kubectl get all
NAME READY STATUS RESTARTS AGE
pod/read-6cbbb6678-58s9t 1/1 Running 0 3s
pod/read-6cbbb6678-kz7v4 1/1 Running 0 3s
pod/read-6cbbb6678-s2pct 1/1 Running 0 3s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/azure-cognitive-service-read LoadBalancer 10.0.134.0 <none> 5000:30846/TCP 17h
service/kubernetes ClusterIP 10.0.0.1 <none> 443/TCP 78d
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/read 3/3 3 3 3s
NAME DESIRED CURRENT READY AGE
replicaset.apps/read-6cbbb6678 3 3 3 3s
Comprobación de que un contenedor está en ejecución
Hay varias maneras de comprobar que el contenedor está en ejecución. Busque la dirección IP externa y el puerto expuesto del contenedor en cuestión y abra el explorador web que prefiera. Use las distintas direcciones URL de solicitud que se indican a continuación para validar que el contenedor se está ejecutando. Las direcciones URL de solicitud de ejemplo que se enumeran aquí son http://localhost:5000, pero el contenedor específico puede variar. Asegúrese de confiar en la dirección IP externa y el puerto expuesto del contenedor.
| URL de la solicitud | Propósito |
|---|---|
http://localhost:5000/ |
El contenedor ofrece una página principal. |
http://localhost:5000/ready |
Esta URL, solicitada con GET, proporciona una comprobación de que el contenedor está listo para aceptar una consulta para el modelo. Esta solicitud se puede usar con los sondeos de ejecución y preparación de Kubernetes. |
http://localhost:5000/status |
Esta URL, también solicitada con GET, comprueba si el valor de api-key usado para iniciar el contenedor es válido sin generar una consulta de punto de conexión. Esta solicitud se puede usar con los sondeos de ejecución y preparación de Kubernetes. |
http://localhost:5000/swagger |
El contenedor cuenta con un completo conjunto de documentación sobre los puntos de conexión y una característica de prueba. Esta característica le permite especificar la configuración en un formulario HTML basado en web y realizar la consulta sin necesidad de escribir código. Una vez que la consulta devuelve resultados, se proporciona un ejemplo del comando CURL para mostrar los encabezados HTTP y el formato de cuerpo requeridos. |
Pasos siguientes
Para obtener más información sobre la instalación de aplicaciones con Helm en Azure Kubernetes Service (AKS), visite esta página.