¿Qué es el reconocimiento de palabras clave?
El reconocimiento de palabras clave detecta una palabra o frase corta dentro de una secuencia de audio. Esta técnica también se conoce como descubrimiento de palabra clave.
El caso de uso más común del reconocimiento de palabras clave es la activación por voz de los asistentes virtuales. Por ejemplo, "Hola Cortana" es la palabra clave para el asistente Cortana. Tras el reconocimiento de la palabra clave, se lleva a cabo una acción específica de cada escenario. En escenarios de asistentes virtuales, una acción resultante común es el reconocimiento de voz de audio que sigue a la palabra clave.
Por lo general, los asistentes virtuales siempre están a la escucha. El reconocimiento de palabras clave actúa como límite de privacidad para el usuario. Un requisito de palabra clave actúa como una barrera que impide que el audio no relacionado del usuario pase del dispositivo local a la nube.
Para equilibrar la precisión, la latencia y la complejidad computacional, el reconocimiento de palabras clave se implementa como un sistema de varias fases. Para todas las fases más allá de la primera, el audio solo se procesa si la fase anterior reconoce la palabra clave de interés.
El sistema actual está diseñado con varias fases que abarcan el perímetro y la nube:
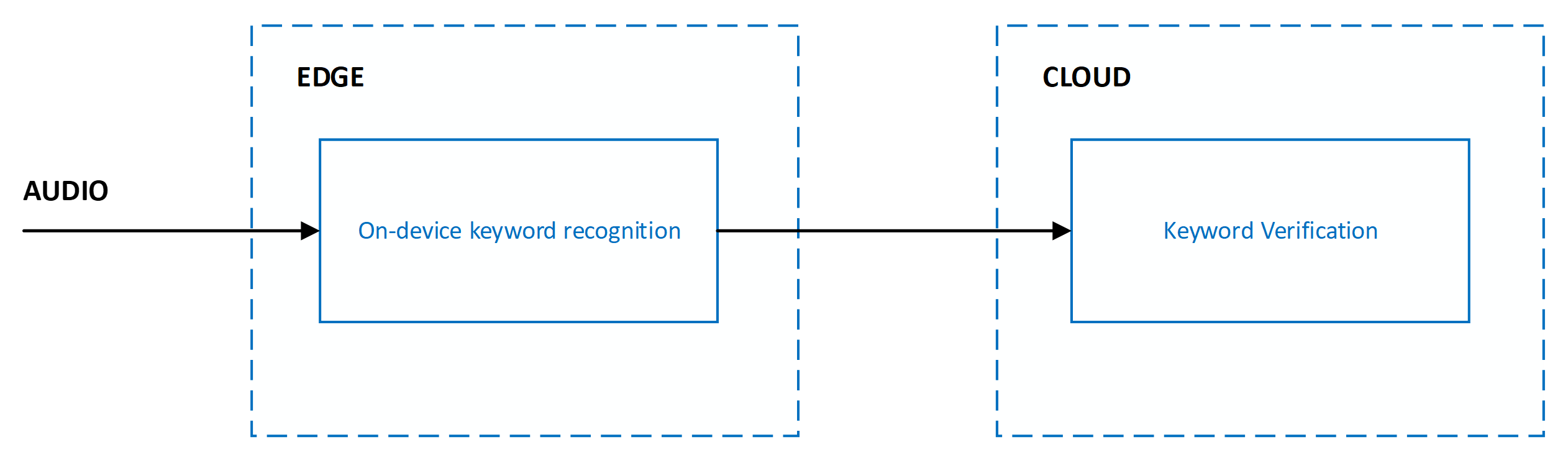
La precisión del reconocimiento de palabras clave se mide mediante las métricas siguientes:
- Tasa de aceptación correcta: mide la capacidad del sistema para reconocer la palabra clave cuando la pronuncia un usuario final. La tasa de aceptación correcta también se conoce como la tasa de verdaderos positivos.
- Tasa de aceptación falsa: mide la capacidad del sistema para filtrar el audio que no sea la palabra clave pronunciada por un usuario final. La tasa de aceptación falsa también se conoce como tasa de falsos positivos.
El objetivo es maximizar la tasa de aceptación correcta al tiempo que se minimiza la tasa de aceptación falsa. El sistema actual está diseñado para detectar una palabra clave o frase precedida de un breve silencio. No se admite la detección de una palabra clave en medio de una frase o expresión.
Palabra clave personalizada para modelos en el dispositivo
Con el portal Palabra clave personalizada en Speech Studio, puede generar modelos de reconocimiento de palabras clave que se ejecutan en el perímetro especificando cualquier palabra o frase corta. Puede personalizar aún más el modelo de palabras clave mediante la elección de las pronunciaciones correctas.
Precios
No hay ningún costo por usar Palabra clave personalizada para generar modelos, incluidos los modelos Básico y Avanzado. Tampoco hay ningún costo por ejecutar modelos en el dispositivo con el SDK de voz cuando se usa con otras características del servicio Voz, como la conversión de voz en texto.
Tipos de modelos
Puede usar Palabra clave personalizada para generar dos tipos de modelos en el dispositivo para cualquier palabra clave.
| Tipo de modelo | Descripción |
|---|---|
| Básico | Adecuado para fines de demostración o de creación rápida de prototipos. Los modelos se generan con un modelo base común y pueden tardar hasta 15 minutos en estar listos. Es posible que los modelos no tengan características de precisión óptimas. |
| Avanzado | Adecuado para fines de integración de productos. Los modelos se generan mediante la adaptación de un modelo base común con datos de entrenamiento simulados para mejorar las características de precisión. Los modelos pueden tardar hasta 48 horas en estar listos. |
Nota
Puede ver una lista de regiones que admiten el tipo de modelo Avanzado en la documentación Compatibilidad con la región de reconocimiento de palabras clave.
Ningún tipo de modelo requiere que cargue datos de entrenamiento. Palabra clave personalizada controla completamente la generación de datos y el entrenamiento del modelo.
Pronunciaciones
Al crear un nuevo modelo, Palabra clave personalizada genera automáticamente posibles pronunciaciones de la palabra clave proporcionada. Puede escuchar cada pronunciación y elegir todas las variaciones que representan mejor la forma en que espera que los usuarios digan la palabra clave. No se deben seleccionar las demás pronunciaciones.
Es importante escoger cuidadosamente las pronunciaciones para garantizar las mejores características de precisión. Por ejemplo, si elige más pronunciaciones de las que necesita, es posible que obtenga mayores tasas de aceptación falsas. Si se eligen pocas pronunciaciones, de manera que no se cubran todas las variaciones esperadas, podría obtener tasas de aceptación correcta inferiores.
Modelos de prueba
Una vez que una palabra clave personalizada genere modelos en el dispositivo, los modelos se pueden probar directamente en el portal. Puede usar el portal para hablar directamente al explorador y obtener los resultados del reconocimiento de palabras clave.
Comprobación de la palabra clave
La comprobación de palabras clave es un servicio en la nube que reduce el efecto de las aceptaciones falsas de los modelos en el dispositivo con modelos sólidos que se ejecutan en Azure. No se requiere ningún ajuste ni entrenamiento para que la comprobación de palabras clave funcione con su palabra clave. Para mejorar la precisión y la latencia, en el servicio se implementan continuamente actualizaciones de modelo incrementales, que son completamente transparentes para las aplicaciones cliente.
Precios
La comprobación de palabras clave siempre se usa en combinación con la conversión de voz en texto. No hay ningún costo por usar la comprobación de palabras clave más allá del costo de la conversión de voz en texto.
Comprobación de palabras clave y conversión de voz en texto
Cuando se usa la comprobación de palabras clave, siempre se combina con la conversión de voz en texto. Ambos servicios se ejecutan en paralelo, lo que significa que el audio se envía a ambos servicios para su procesamiento simultáneo.
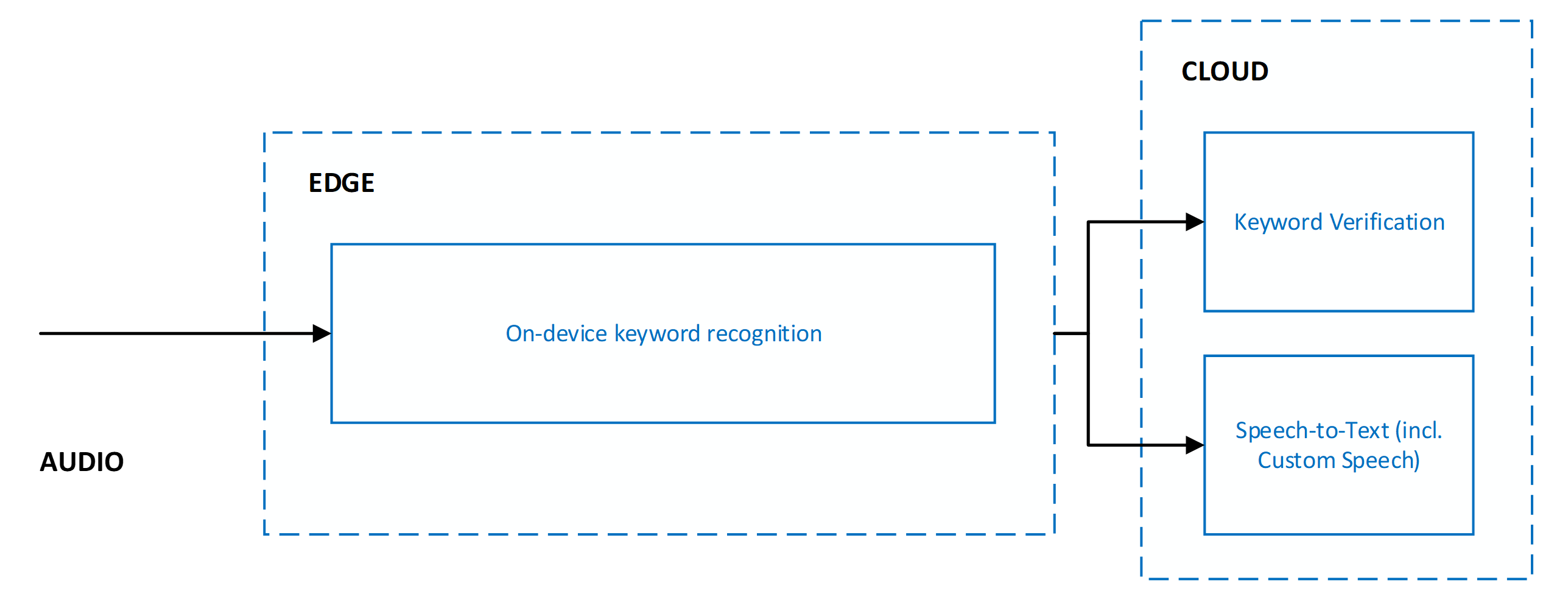
La ejecución de la comprobación de palabras clave y la conversión de voz en texto en paralelo ofrece las siguientes ventajas:
- Ninguna otra latencia en los resultados de la conversión de voz en texto: la ejecución en paralelo significa que la comprobación de palabras clave no agrega latencia. El cliente recibe los resultados de la conversión de voz en texto con la misma rapidez. Si la comprobación de palabras clave determina que la palabra clave no estaba presente en el audio, el procesamiento de la conversión de voz en texto termina. Esta acción protege contra el procesamiento innecesario de la conversión de voz en texto. El procesamiento de modelos de red y nube aumenta la latencia de activación de voz que percibe el usuario. Para obtener más información, vea Recomendaciones e instrucciones para el reconocimiento de palabras clave.
- Prefijo de palabra clave forzado en los resultados de conversión de voz en texto: el procesamiento de conversión de voz en texto garantiza que los resultados enviados al cliente tienen como prefijo la palabra clave. Este comportamiento permite una mayor precisión en los resultados de conversión de voz en texto para la voz que sigue a la palabra clave.
- Mayor tiempo de espera de conversión de voz en texto: debido a la presencia esperada de la palabra clave al principio del audio, la conversión de voz en texto permite una pausa más larga de hasta cinco segundos después de la palabra clave antes de que determine el final de la voz y finalice el procesamiento de conversión de voz en texto. Este comportamiento garantiza que la experiencia del usuario final se controle correctamente para los comandos de fase (<keyword><pause><command>) y los comandos encadenados (<keyword><command>).
Respuestas de la comprobación de palabras clave y consideraciones de latencia
Para cada solicitud que se realiza al servicio, la comprobación de palabras clave devuelve una de dos respuestas: Aceptado o Rechazado. La latencia de procesamiento varía según la longitud de la palabra clave y la longitud del segmento de audio que se espera que contenga la palabra clave. La latencia de procesamiento no incluye el coste de red entre el cliente y los servicios de Voz.
| Respuesta de la comprobación de palabras clave | Descripción |
|---|---|
| Aceptado | Indica que el servicio consideró que la palabra clave estaba presente en la secuencia de audio proporcionada como parte de la solicitud. |
| Rechazada | Indica que el servicio consideró que la palabra clave no estaba presente en la secuencia de audio proporcionada como parte de la solicitud. |
Los casos rechazados suelen producir latencias mayores, ya que el servicio procesa más audio que con los casos aceptados. De forma predeterminada, la comprobación de palabras clave procesa un máximo de dos segundos de audio para buscar la palabra clave. Si la palabra clave no se encuentra en dos segundos, el servicio agota el tiempo de espera y señala una respuesta rechazada al cliente.
Uso de la comprobación de palabras clave con modelos en el dispositivo desde Palabra clave personalizada
El SDK de Voz posibilita el uso sin problemas de los modelos en el dispositivo generados mediante Palabra clave personalizada con comprobación de palabras clave y conversión de voz en texto. Controla de forma transparente lo siguiente:
- El acceso de audio a la comprobación de palabras clave y el reconocimiento de voz en función del resultado del modelo en el dispositivo.
- La comunicación de la palabra clave a la comprobación de palabras clave.
- La comunicación de cualquier metadato adicional a la nube para orquestar el escenario de un extremo a otro.
No es necesario especificar explícitamente ningún parámetro de configuración. Toda la información necesaria se extrae automáticamente del modelo en el dispositivo generado por Palabra clave personalizada.
El ejemplo y los tutoriales vinculados aquí muestran cómo usar el SDK de Voz:
- Ejemplos del asistente de voz en GitHub
- Tutorial: Habilitación del asistente con voz creado mediante el Servicio de Bot de Azure AI con el SDK de Voz para C#
- Tutorial: Creación de una aplicación de comandos personalizados con comandos de voz simples
Integración y escenarios del SDK de Voz
El SDK de Voz posibilita el uso sencillo de modelos personalizados de reconocimiento de palabras clave en el dispositivo generados con Palabra clave personalizada y la comprobación de palabras clave. Para asegurarse de que se puedan satisfacer las necesidades del producto, el SDK admite los dos escenarios siguientes:
| Escenario | Descripción | Ejemplos |
|---|---|---|
| Reconocimiento de palabras clave de un extremo a otro con conversión de voz en texto | Adecuado para productos que usa un modelo personalizado de palabras clave en el dispositivo, desde palabras clave personalizadas con comprobación de palabras clave y la conversión de voz en texto. Este escenario es el más habitual. | |
| Reconocimiento de palabras clave sin conexión | Adecuado para productos sin conectividad de red que usa un modelo personalizado de palabras clave en el dispositivo desde Palabra clave personalizada. |