Adición de un conjunto de datos de entrenamiento de voz profesional
Cuando esté listo para crear un modelo personalizado de texto a voz para su aplicación, el primer paso es reunir las grabaciones de audio y los scripts asociados para empezar a entrenar el modelo de voz. Para más información sobre cómo grabar ejemplos de voz, consulte el tutorial. El servicio de voz usan estos datos para crear una voz única optimizada para que coincida con la de las grabaciones. Cuando haya entrenado la voz, puede comenzar a sintetizarla en sus aplicaciones.
Todos los datos que cargue deben cumplir los requisitos del tipo de datos elegido. Es importante dar el formato correcto a los datos antes de cargarlos, lo que garantiza que el servicio de voz los procese con precisión. Para confirmar que los datos están correctamente formateados, consulte Tipos de datos de entrenamiento.
Nota
- En cambio, los usuarios con una suscripción estándar (S0) pueden cargar cinco archivos de datos a la vez. Si alcanza el límite, espere hasta que al menos uno de los archivos de datos finalice la importación. A continuación, inténtelo de nuevo.
- El número máximo de archivos de datos que se pueden importar por suscripción es de 500 archivos ZIP para usuarios de la suscripción estándar (S0). Consulte las cuotas y los límites del servicio voz para obtener más información.
Creación del código
Cuando esté listo para cargar los datos, vaya a la pestaña Prepare training data (Preparar datos de entrenamiento) para agregar su primer conjunto de entrenamiento y cargar datos. Un conjunto de entrenamiento es un conjunto de expresiones de audio y los scripts de asignación que se usan para entrenar un modelo de voz. Puede usar un conjunto de entrenamiento para organizar los datos de entrenamiento. El servicio comprueba la preparación de los datos para cada conjunto de entrenamiento. Puede importar varios datos a un conjunto de entrenamiento.
Para cargar datos de entrenamiento, siga estos pasos:
- Inicie sesión en Speech Studio.
- Seleccione voz personalizada> El nombre del proyecto >Preparar los datos de entrenamiento>Cargar los datos.
- En el asistente de carga de datos, elija un tipo de datos y, a continuación, seleccione Siguiente .
- Seleccione los archivos locales del equipo o escriba la dirección URL de Azure Blob Storage para cargar datos.
- En Especificar el conjunto de entrenamiento de destino, seleccione un conjunto de formación existente o cree uno nuevo. Si ha creado un nuevo conjunto de entrenamiento, asegúrese de que está seleccionado en la lista desplegable antes de continuar.
- Seleccione Next (Siguiente).
- Ingrese un nombre y una descripción para los datos y luego seleccione Siguiente.
- Revise los detalles de carga y seleccione Enviar.
Nota:
No se aceptan identificadores duplicados. Se quitarán las expresiones con el mismo identificador.
Los nombres de audio duplicados se quitan del entrenamiento. Asegúrese de que los datos que seleccione no contengan los mismos nombres de audio en el archivo ZIP o en varios archivos ZIP. Si los id. de expresión (ya sea en archivos de audio o de script) están duplicados, se rechazan.
Los archivos de datos se validan automáticamente al seleccionar Enviar. La validación de datos incluye una serie de comprobaciones en los archivos de audio para comprobar su formato de archivo, el tamaño y la frecuencia de muestreo. Si hay algún error, corríjalo y vuelva a realizar el envío.
Una vez cargados los datos, puede comprobar los detalles en la vista de detalles del conjunto de entrenamiento. En la página Detalles puede comprobar la incidencia de las pronunciaciones y el nivel de ruido de los datos. La puntuación de pronunciación en el nivel de oración oscila entre 0 y 100. Una puntuación por debajo de 70 normalmente indica un error en el discurso o que el guion no coincide. Las expresiones con una puntuación general inferior a 70 se rechazarán. Un acento marcado puede reducir la puntuación de las pronunciaciones, y afectar a la voz digital que se ha creado.
Resolver problemas de datos en línea
Tras la carga, puede comprobar los detalles de los datos del conjunto de entrenamiento. Antes de continuar entrenando el modelo de voz, debe intentar resolver los problemas de datos.
Puede identificar y resolver problemas de datos por expresión en Speech Studio.
En la página Detalles, vaya a la página Datos aceptados o Datos rechazados. Seleccione las expresiones individuales que quiera cambiar y, después, seleccione Editar.
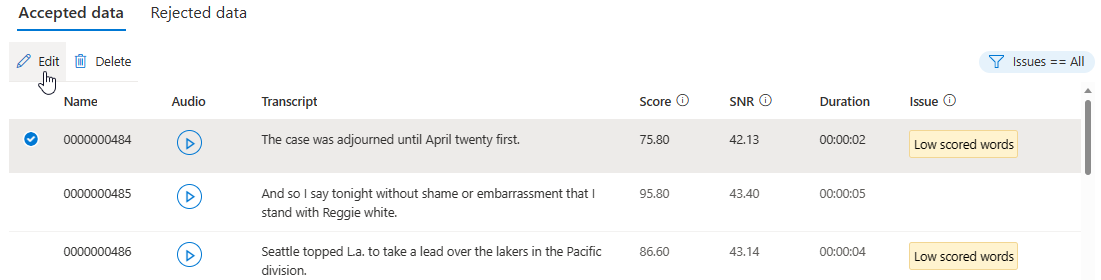
Puede elegir qué problemas de datos se mostrarán en función de sus criterios.
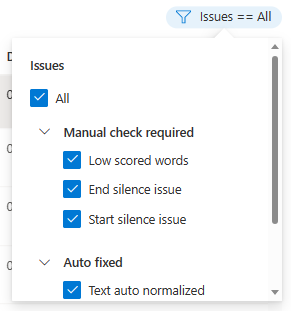
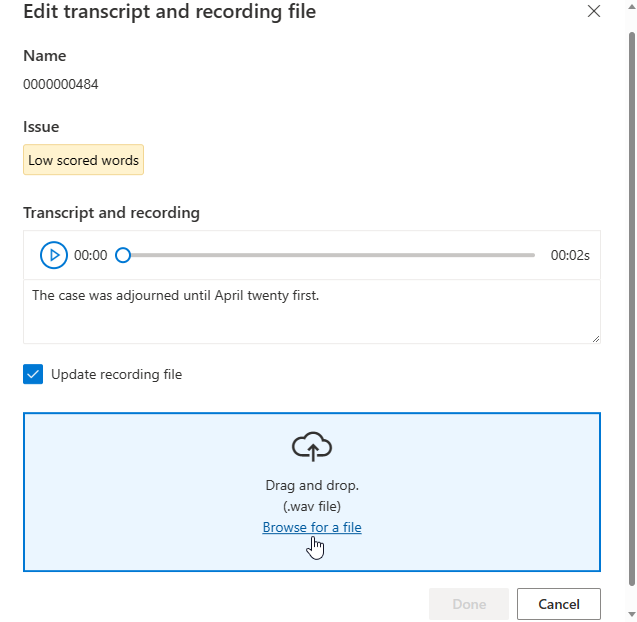
A continuación, se mostrará la ventana de edición.
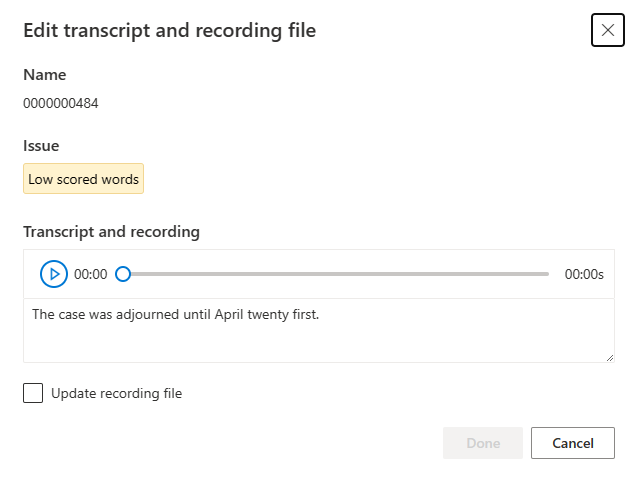
Actualice la transcripción o el archivo de grabación, en función la descripción del problema, en la ventana de edición.
Es posible editar la transcripción en el cuadro de texto y, a continuación, seleccionar Listo
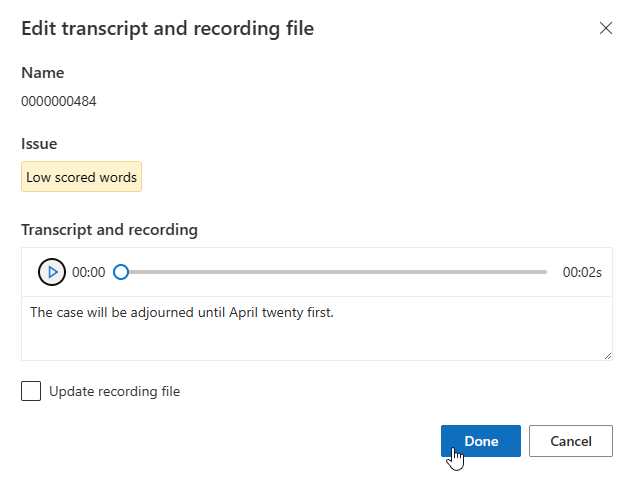
Si, en cambio, necesita actualizar el archivo de grabación, seleccione Actualizar archivo de grabación y cargue el archivo de grabación fijo (formato .wav).
Después de realizar cambios en los datos, debe comprobar la calidad de los datos haciendo clic en Analizar datos antes de usar este conjunto de datos para el entrenamiento.
No podrá seleccionar este conjunto de entrenamiento para su uso en un modelo de entrenamiento mientras que no se haya completado el análisis.
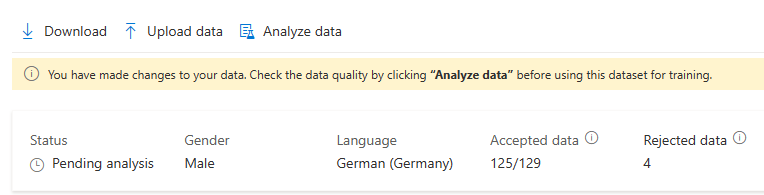
También puede eliminar expresiones con problemas seleccionándolos y haciendo clic en Eliminar.
Problemas de datos típicos
Los problemas se dividen en tres tipos. Consulte las tablas siguientes para comprobar los tipos de errores respectivos.
Rechazado automáticamente
Los datos con estos errores no se usarán para el entrenamiento. Los datos importados con errores se omitirán, por lo que no es necesario eliminarlos. Puede corregir estos errores de datos en línea o volver a cargar los datos corregidos para el entrenamiento.
| Category | Nombre | Descripción |
|---|---|---|
| Script | Invalid separator (Separador no válido) | Debe separar el id. de expresión y el contenido del script con un carácter de tabulación. |
| Script | Invalid script ID (Id. de script no válido) | El id. de la línea del script debe ser numérico. |
| Script | Script duplicado | Cada línea del contenido del script debe ser única. La línea está duplicada con 1{}. |
| Script | El script es demasiado largo | El script debe tener menos de 1000 caracteres. |
| Script | Sin audio correspondiente | El id. de cada expresión (cada línea del archivo del script) debe coincidir con el id. de audio. |
| Script | No valid script (Sin script válido) | No se encontró ningún script válido en este conjunto de datos. Corrija las líneas del script que aparecen en la lista detallada de problemas. |
| Audio | Sin script correspondiente | Ningún archivo de audio coincide con el id. del script. El nombre de los archivos .wav debe coincidir con los id. de los archivos de script. |
| Audio | Invalid audio format (Formato de audio no válido) | El formato de audio de los archivos .wav no es válido. Compruebe el formato de archivo .wav mediante una herramienta de audio como SoX. |
| Audio | Low sampling rate (Velocidad de muestreo baja) | La frecuencia de muestreo de los archivos .wav no puede ser inferior a 16 KHz. |
| Audio | El audio es demasiado largo | La duración del audio es mayor que 30 segundos. Divida el audio largo en varios archivos. Es una buena idea hacer que las expresiones duren menos de 15 segundos. |
| Audio | No valid audio (No hay audio válido) | No se encontró ningún audio válido en este conjunto de datos. Compruebe los datos de audio y cárquelos de nuevo. |
| Error de coincidencia | Expresión con puntuación baja | La puntuación de pronunciación de nivel de oración es inferior a 70. Revise el script y el audio para asegurarse de que coinciden. |
Corregido automáticamente
Los siguientes errores se corrigen automáticamente, pero debe revisar y confirmar que se han realizado las correcciones correctamente.
| Category | Nombre | Descripción |
|---|---|---|
| Error de coincidencia | Silencio corregido automáticamente | Se detecta que el silencio al principio es inferior a 100 ms y se ha ampliado a 100 ms automáticamente. Descargue el conjunto de datos normalizado y revíselo. |
| Error de coincidencia | Silencio corregido automáticamente | Se detecta que el silencio al final es inferior a 100 ms y se ha ampliado a 100 ms automáticamente. Descargue el conjunto de datos normalizado y revíselo. |
| Script | Texto normalizado automáticamente | El texto se normaliza automáticamente para dígitos, símbolos y abreviaturas. Revise el script y el audio para asegurarse de que coinciden. |
Comprobación manual necesaria
Los errores sin resolver enumerados en la tabla siguiente afectan a la calidad del entrenamiento, pero los datos con estos errores no se excluirán durante el entrenamiento. Para un entrenamiento de mayor calidad, es una buena idea corregir estos errores manualmente.
| Category | Nombre | Descripción |
|---|---|---|
| Script | Texto no normalizado | Este script contiene símbolos. Normalice los símbolos para que coincidan con el audio. Por ejemplo, normalice / a barra diagonal. |
| Script | No hay suficientes expresiones de pregunta | Al menos el 10 % de las expresiones totales deben ser frases de pregunta. Esto ayuda al modelo de voz a expresar correctamente un tono de interrogación. |
| Script | No hay suficientes expresiones de exclamación | Al menos el 10 % de las expresiones totales deben ser frases de exclamación. Esto ayuda al modelo de voz a expresar correctamente un tono de exclamación. |
| Script | No hay puntuación final válida | Agregue uno de los siguientes elementos al final de la línea: parada completa (ancho medio "." o ancho completo "。"), signo de exclamación (ancho medio "!" o ancho completo "!") o signo de interrogación (ancho medio "?" o ancho completo "?"). |
| Audio | Low sampling rate for neural voice (Velocidad de muestreo baja para la voz neuronal) | Se recomienda que la frecuencia de muestreo de los archivos .wav sea de 24 KHz o superior para crear voces neuronales. Si es inferior, se elevará automáticamente a 24 KHz. |
| Volumen | Overall volume too low (Volumen general demasiado bajo) | El volumen no debe ser inferior a -18 dB (10 % del volumen máximo). Controle el volumen medio dentro del intervalo adecuado durante la grabación de ejemplo o la preparación de los datos. |
| Volumen | Desbordamiento de volumen | El volumen desbordante se detecta en {}s. Ajuste el equipo de grabación para evitar el desbordamiento de volumen en su valor máximo. |
| Volumen | Problema de silencio al principio | Los primeros 100 ms de silencio tienen ruido. Reduzca el nivel de ruido de la grabación y deje los primeros 100 ms del principio en modo silencioso. |
| Volumen | Problema de silencio al final | Los últimos 100 ms de silencio tienen ruido. Reduzca el nivel de ruido de la grabación y deje los últimos 100 ms del final en modo silencioso. |
| Error de coincidencia | Palabras con puntuación baja | Revise el contenido del script y del audio para asegurarse de que coinciden y controle el ruido. Reduzca la longitud del silencio largo o divida el audio en varias expresiones si es demasiado largo. |
| Error de coincidencia | Problema de silencio al principio | Antes de la primera palabra se oía audio adicional. Revise el script y el contenido de audio para asegurarse de que coinciden, controlan el nivel de ruido del suelo y hacen que los primeros 100 ms no se usen. |
| Error de coincidencia | Problema de silencio al final | Después de la última palabra se oía audio adicional. Revise el script y el contenido de audio para asegurarse de que coinciden, controlan el nivel de ruido del suelo y hacen que los últimos 100 ms no se usen. |
| Error de coincidencia | Low signal-noise ratio (Relación entre señal y ruido de baja calidad) | La relación entre señal y ruido del audio es menor de 20 dB. Se recomiendan al menos 35 dB. |
| Error de coincidencia | No hay puntuación disponible | No se pudo reconocer el contenido de voz en este audio. Compruebe el contenido del audio y del script para asegurarse de que el audio es válido y coincide con el script. |
Pasos siguientes
Necesita un conjunto de datos de entrenamiento para crear una voz profesional. Un conjunto de datos de entrenamiento incluye archivos de audio y script. Los archivos de audio son grabaciones del actor de voz que lee los archivos de script. Los archivos de script son el texto de los archivos de audio.
En este artículo, puede crear un conjunto de formación y obtener su identificador de recurso. A continuación, con el identificador de recurso, puede cargar un conjunto de archivos de audio y script.
Creación de un conjunto de entrenamiento
Para crear un conjunto de formación, use la operación TrainingSets_Create de la API de voz personalizada. Construya el cuerpo de la solicitud según las instrucciones siguientes:
- Establezca la propiedad
projectIdrequerida. Consulte Creación de un proyecto. - Establezca la propiedad
voiceKindnecesaria enMaleoFemale. El tipo no se puede cambiar más adelante. - Establezca la propiedad
localerequerida. Debe ser la configuración regional de los datos del conjunto de entrenamiento. La configuración regional del conjunto de entrenamiento debe ser la misma que la configuración regional de la instrucción de consentimiento. Esta configuración regional no se podrá modificar más adelante. Puede encontrar el texto a voz en la lista de configuración regional de voz aquí. - Si lo desea, puede establecer la propiedad
descriptionpara la descripción del conjunto de entrenamiento. La descripción del conjunto de entrenamiento se puede cambiar más adelante.
Haga una solicitud HTTP PUT usando el URI como se muestra en el siguiente ejemplo de TrainingSets_Create.
- Reemplace
YourResourceKeypor su clave de recurso de Voz. - Reemplace
YourResourceRegionpor la región del recurso de voz. - Reemplace
JessicaTrainingSetIdpor un identificador de conjunto de entrenamiento de su elección. El identificador que distingue mayúsculas de minúsculas se usará en el URI del conjunto de entrenamiento y no se puede cambiar más adelante.
curl -v -X PUT -H "Ocp-Apim-Subscription-Key: YourResourceKey" -H "Content-Type: application/json" -d '{
"description": "300 sentences Jessica data in general style.",
"projectId": "ProjectId",
"locale": "en-US",
"voiceKind": "Female"
} ' "https://YourResourceRegion.api.cognitive.microsoft.com/customvoice/trainingsets/JessicaTrainingSetId?api-version=2023-12-01-preview"
Debe recibir un cuerpo de respuesta en el formato siguiente:
{
"id": "JessicaTrainingSetId",
"description": "300 sentences Jessica data in general style.",
"projectId": "ProjectId",
"locale": "en-US",
"voiceKind": "Female",
"status": "Succeeded",
"createdDateTime": "2023-04-01T05:30:00.000Z",
"lastActionDateTime": "2023-04-02T10:15:30.000Z"
}
Carga de datos del conjunto de entrenamiento
Para cargar un conjunto de formación de audio y scripts, use la operación TrainingSets_UploadData de la API de voz personalizada.
Antes de llamar a esta API, almacene los archivos de grabación y script en Azure Blob. En el ejemplo siguiente, los archivos de grabación son https://contoso.blob.core.windows.net/voicecontainer/jessica300/*.wav, los archivos de script son https://contoso.blob.core.windows.net/voicecontainer/jessica300/*.txt.
Construya el cuerpo de la solicitud según las instrucciones siguientes:
- Establezca la propiedad
kindnecesaria enAudioAndScript. El tipo determina el tipo de conjunto de entrenamiento. - Establezca la propiedad
audiosrequerida. En la propiedadaudios, establezca las siguientes propiedades:- Establezca la propiedad
containerUrlnecesaria en la dirección URL del contenedor de Azure Blob Storage que contiene los archivos de audio. Use firmas de acceso compartido (SAS) para un contenedor con permisos de lectura y lista. - Establezca la propiedad
extensionsnecesaria en las extensiones de los archivos de audio. - Opcionalmente, establezca la propiedad
prefixa fin de definir un prefijo para el nombre del blob.
- Establezca la propiedad
- Establezca la propiedad
scriptsrequerida. En la propiedadscripts, establezca las siguientes propiedades:- Establezca la propiedad
containerUrlnecesaria en la dirección URL del contenedor de Azure Blob Storage que contiene los archivos de script. Use firmas de acceso compartido (SAS) para un contenedor con permisos de lectura y lista. - Establezca la propiedad
extensionsnecesaria en las extensiones de los archivos de script. - Opcionalmente, establezca la propiedad
prefixa fin de definir un prefijo para el nombre del blob.
- Establezca la propiedad
Realice una solicitud HTTP POST usando el URI como se muestra en el ejemplo siguiente TrainingSets_UploadData.
- Reemplace
YourResourceKeypor su clave de recurso de Voz. - Reemplace
YourResourceRegionpor la región del recurso de voz. - Reemplace
JessicaTrainingSetIdsi especificó un identificador de conjunto de entrenamiento diferente en el paso anterior.
curl -v -X POST -H "Ocp-Apim-Subscription-Key: YourResourceKey" -H "Content-Type: application/json" -d '{
"kind": "AudioAndScript",
"audios": {
"containerUrl": "https://contoso.blob.core.windows.net/voicecontainer?mySasToken",
"prefix": "jessica300/",
"extensions": [
".wav"
]
},
"scripts": {
"containerUrl": "https://contoso.blob.core.windows.net/voicecontainer?mySasToken",
"prefix": "jessica300/",
"extensions": [
".txt"
]
}
} ' "https://YourResourceRegion.api.cognitive.microsoft.com/customvoice/trainingsets/JessicaTrainingSetId:upload?api-version=2023-12-01-preview"
El encabezado de respuesta contiene la propiedad Operation-Location. Use este URI para obtener detalles sobre la operación TrainingSets_UploadData. Este es un ejemplo de encabezado de respuesta:
Operation-Location: https://eastus.api.cognitive.microsoft.com/customvoice/operations/284b7e37-f42d-4054-8fa9-08523c3de345?api-version=2023-12-01-preview
Operation-Id: 284b7e37-f42d-4054-8fa9-08523c3de345