Contenedores personalizados de conversión de voz en texto con Docker
El contenedor personalizado de conversión de voz en texto transcribe grabaciones de audio por lotes o de voz en tiempo real con resultados intermedios. Puede usar un modelo personalizado que haya creado en el Portal de voz personalizada. En este artículo aprenderá a descargar, instalar y ejecutar un contenedor personalizado de conversión de voz a texto.
Para obtener más información sobre los requisitos previos, validar que el contenedor se esté ejecutando, ejecutar varios contenedores en el mismo host y ejecutar contenedores desconectados, consulte Instalación y ejecución de contenedores de Voz con Docker.
Imágenes del contenedor
La imagen de contenedor personalizado de conversión de voz en texto para todas las versiones y configuraciones regionales compatibles se puede encontrar en el sindicato de Microsoft Container Registry (MCR). Reside en el repositorio azure-cognitive-services/speechservices/ y se denomina custom-speech-to-text.

El nombre completo de la imagen de contenedor es mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text. Anexa una versión específica o :latest para obtener la versión más reciente.
| Versión | Path |
|---|---|
| Más reciente | mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text:latest |
| 4.6.0 | mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text:4.6.0-amd64 |
Todas las etiquetas, salvo latest, tienen el formato siguiente y distinguen mayúsculas de minúsculas:
<major>.<minor>.<patch>-<platform>-<prerelease>
Nota:
Los valores de locale y voice de los contenedores personalizados de conversión de voz en texto los determina el modelo personalizado que ingiere el contenedor.
Las etiquetas también están disponibles en formato JSON para tu comodidad. El cuerpo incluye la ruta de acceso del contenedor y la lista de etiquetas. Las etiquetas no están ordenadas por versión, pero "latest" siempre se incluye al final de la lista, como se muestra en este fragmento de código:
{
"name": "azure-cognitive-services/speechservices/custom-speech-to-text",
"tags": [
"2.10.0-amd64",
"2.11.0-amd64",
"2.12.0-amd64",
"2.12.1-amd64",
<--redacted for brevity-->
"latest"
]
}
Obtención de la imagen de contenedor con el comando docker pull
Son necesarios los requisitos previos, incluido el hardware necesario. Consulte también la asignación recomendada de recursos para cada contenedor de voz.
Use el comando docker pull para descargar una imagen de contenedor de Microsoft Container Registry:
docker pull mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text:latest
Nota
Los valores de locale y voice de los contenedores de voz personalizados los determina el modelo personalizado que ingiere el contenedor.
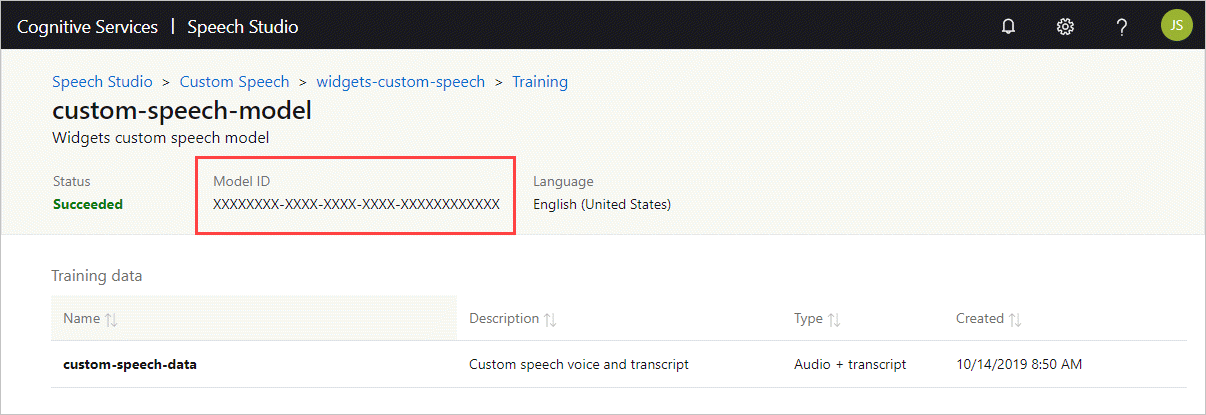
Obtención del id. del modelo
Para poder ejecutar el contenedor, debe conocer el id. de modelo del modelo personalizado o un id. de modelo base. Al ejecutar el contenedor, especifique uno de los identificadores de modelo que se van a descargar y usar.
El modelo personalizado debe entrenarse usando el Speech Studio. Para más información sobre cómo obtener el id. del modelo, consulte Ciclo de vida del modelo de voz personalizada.
Obtenga el identificador de modelo que se va a usar como argumento para el parámetro ModelId del comando docker run.
Descarga del modelo de visualización
Antes de ejecutar el contenedor, puede obtener opcionalmente la información de los modelos de visualización disponibles y optar por descargar esos modelos en el contenedor de conversión de voz en texto para obtener una visualización de salida final altamente mejorada. La descarga del modelo de visualización está disponible con la versión 3.1.0 y posterior del contenedor personalizado de conversión de voz en texto.
Nota:
Aunque use el comando docker run, el contenedor no se inicia para el servicio.
Puede consultar o descargar cualquiera de estos tipos de modelo de presentación, o todos ellos: Rescoring (Rescore), Punctuation (Punct), resegmentation (Resegment) y wfstitn (Wfstitn). De lo contrario, puede usar la opción FullDisplay (con los otros tipos o sin ellos) para consultar o descargar todos los tipos de modelos de presentación.
Establezca BaseModelLocale para consultar el modelo de presentación más reciente disponible en la configuración regional de destino. Si incluye varios tipos de modelo para mostrar, el comando devuelve los modelos de visualización disponibles más recientes para cada tipo. Por ejemplo:
docker run --rm -it \
mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text \
Punct Rescore Resegment Wfstitn \ # Specify `FullDisplay` or a space-separated subset of display models
BaseModelLocale={LOCALE} \
Eula=accept \
Billing={ENDPOINT_URI} \
ApiKey={API_KEY}
Establezca DisplayLocale para descargar el modelo de presentación más reciente disponible en la configuración regional de destino. Al establecer DisplayLocale, también debe especificar FullDisplay o un subconjunto de modelos de presentación separados por espacios. El comando descarga el modelo de visualización más reciente disponible para cada tipo especificado. Por ejemplo:
docker run --rm -it \
mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text \
Punct Rescore Resegment Wfstitn \ # Specify `FullDisplay` or a space-separated subset of display models
DisplayLocale={LOCALE} \
Eula=accept \
Billing={ENDPOINT_URI} \
ApiKey={API_KEY}
Establezca un parámetro de Id. de modelo para descargar un modelo de presentación específico: Rescoring (RescoreId), Punctuation (PunctId), resegmentation (ResegmentId) o wfstitn (WfstitnId). Esto es parecido a la forma en que descargaría un modelo base mediante el parámetro ModelId. Por ejemplo, para descargar un modelo de presentación rescoring, puede usar el comando siguiente con el parámetro RescoreId:
docker run --rm -it \
mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text \
RescoreId={RESCORE_MODEL_ID} \
Eula=accept \
Billing={ENDPOINT_URI} \
ApiKey={API_KEY}
Nota
Si establece más de una consulta o parámetro de descarga, el comando establecerá una prioridad en este orden: BaseModelLocale, Id. de modelo y, después, DisplayLocale (solo se aplica a los modelos de presentación).
Ejecute el contenedor con docker run
Utilice el comando docker run para ejecutar el contenedor para el servicio.
En la tabla siguiente se representan los diversos parámetros de docker run y las descripciones correspondientes:
| Parámetro | Descripción |
|---|---|
{VOLUME_MOUNT} |
El montaje del volumen del equipo host, que Docker usa para conservar el modelo personalizado. Un ejemplo es c:\CustomSpeech, donde la unidad c:\ se encuentra en la máquina host. |
{MODEL_ID} |
Id. del modelo base o de voz personalizado. Para más información, consulte Obtener id. del modelo. |
{ENDPOINT_URI} |
El punto de conexión es necesario para la medición y la facturación. Para más información, consulte los argumentos de facturación. |
{API_KEY} |
Se necesita la clave de API. Para más información, consulta los argumentos de facturación. |
Al ejecutar el contenedor personalizado de conversión de voz en texto, configure el puerto, la memoria y la CPU según los requisitos y recomendaciones del contenedor personalizado de conversión de voz en texto.
Este es un ejemplo del comando docker run con valores de marcador de posición. Debe especificar los parámetros VOLUME_MOUNT, MODEL_ID, ENDPOINT_URI y API_KEY:
docker run --rm -it -p 5000:5000 --memory 8g --cpus 4 \
-v {VOLUME_MOUNT}:/usr/local/models \
mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text \
ModelId={MODEL_ID} \
Eula=accept \
Billing={ENDPOINT_URI} \
ApiKey={API_KEY}
Este comando:
- Ejecuta un contenedor Conversión de voz a texto personalizada desde la imagen de contenedor.
- Asigna 4 núcleos de CPU y 8 GB de memoria.
- Carga el modelo de Conversión de voz a texto personalizada desde el montaje de entrada de volumen, por ejemplo, C:\CustomSpeech.
- Expone el puerto TCP 5000 y asigna un seudo-TTY para el contenedor.
- Descarga el modelo dado el
ModelId(si no se encuentra en el montaje de volumen). - Si el modelo personalizado se descargó anteriormente, se omite el
ModelId. - Una vez que se produce la salida, quita automáticamente el contenedor. La imagen del contenedor sigue estando disponible en el equipo host.
Para obtener más información sobre docker run con los contenedores de Voz, consulte Instalación y ejecución de contenedores de Voz con Docker.
Uso del contenedor
Los contenedores de voz proporcionan las API de punto de conexión de consulta basadas en websocket a las que se accede a través del SDK de voz y la CLI de voz. De forma predeterminada, el SDK de Voz y la CLI de Voz usan el servicio de Voz público. Para usar el contenedor, deberá cambiar el método de inicialización.
Importante
Cuando uses el servicio de voz con contenedores, asegúrate de usar la autenticación de host. Si configuras la clave y la región, las solicitudes irán al servicio de voz público. Es posible que los resultados del servicio de voz no sean los esperados. Se producirá un error en las solicitudes de contenedores desconectados.
En lugar de usar esta configuración de inicialización en la nube de Azure:
var config = SpeechConfig.FromSubscription(...);
Usa esta configuración con el host del contenedor:
var config = SpeechConfig.FromHost(
new Uri("ws://localhost:5000"));
En lugar de usar esta configuración de inicialización en la nube de Azure:
auto speechConfig = SpeechConfig::FromSubscription(...);
Usa esta configuración con el host del contenedor:
auto speechConfig = SpeechConfig::FromHost("ws://localhost:5000");
En lugar de usar esta configuración de inicialización en la nube de Azure:
speechConfig, err := speech.NewSpeechConfigFromSubscription(...)
Usa esta configuración con el host del contenedor:
speechConfig, err := speech.NewSpeechConfigFromHost("ws://localhost:5000")
En lugar de usar esta configuración de inicialización en la nube de Azure:
SpeechConfig speechConfig = SpeechConfig.fromSubscription(...);
Usa esta configuración con el host del contenedor:
SpeechConfig speechConfig = SpeechConfig.fromHost("ws://localhost:5000");
En lugar de usar esta configuración de inicialización en la nube de Azure:
const speechConfig = sdk.SpeechConfig.fromSubscription(...);
Usa esta configuración con el host del contenedor:
const speechConfig = sdk.SpeechConfig.fromHost("ws://localhost:5000");
En lugar de usar esta configuración de inicialización en la nube de Azure:
SPXSpeechConfiguration *speechConfig = [[SPXSpeechConfiguration alloc] initWithSubscription:...];
Usa esta configuración con el host del contenedor:
SPXSpeechConfiguration *speechConfig = [[SPXSpeechConfiguration alloc] initWithHost:"ws://localhost:5000"];
En lugar de usar esta configuración de inicialización en la nube de Azure:
let speechConfig = SPXSpeechConfiguration(subscription: "", region: "");
Usa esta configuración con el host del contenedor:
let speechConfig = SPXSpeechConfiguration(host: "ws://localhost:5000");
En lugar de usar esta configuración de inicialización en la nube de Azure:
speech_config = speechsdk.SpeechConfig(
subscription=speech_key, region=service_region)
Usa esta configuración con el punto de conexión del contenedor:
speech_config = speechsdk.SpeechConfig(
host="ws://localhost:5000")
Al usar la CLI de Voz en un contenedor, incluya la opción --host ws://localhost:5000/. También debes especificar --key none para garantizar que la CLI no intenta usar una clave de Azure Cognitive Service para voz para la autenticación. Para más información sobre cómo configurar la CLI de voz, consulta Introducción a la CLI de voz de Azure AI.
Pruebe el inicio rápido de conversión de voz en texto mediante la autenticación de host en lugar de la clave y la región.
Pasos siguientes
- Consulta la Información general de los contenedores de voz
- Revise Configuración de contenedores para ver las opciones de configuración.
- Uso de más contenedores de Azure AI