Integración de datos mediante Azure Data Factory y Azure Data Share
SE APLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Pruebe Data Factory en Microsoft Fabric, una solución de análisis todo en uno para empresas. Microsoft Fabric abarca todo, desde el movimiento de datos hasta la ciencia de datos, el análisis en tiempo real, la inteligencia empresarial y los informes. Obtenga información sobre cómo iniciar una nueva evaluación gratuita.
A medida que los clientes se embarcan en sus modernos proyectos de almacenamiento y análisis de datos, no solo necesitan más datos sino también más visibilidad de los datos en sus diferentes estados. En este taller se analiza cómo las mejoras en Azure Data Factory y Azure Data Share simplifican la integración y administración de los datos en Azure.
Desde la habilitación de procesos de ETL/ELT sin código hasta la creación de una vista completa de los datos, las mejoras en Azure Data Factory permiten a los ingenieros de datos aportar de forma segura más datos y, por tanto, más valor a la empresa. Azure Data Share permite compartir datos entre negocios de una manera controlada.
En este taller usará Azure Data Factory (ADF) para la ingesta de datos de Azure SQL Database en Azure Data Lake Storage Gen2 (ADLS Gen2). Cuando ya disponga de los datos en el lago, los transformará mediante flujos de datos de asignación, el servicio de transformación nativo de Azure Data Factory, y los recibirá en Azure Synapse Analytics. A continuación, compartirá la tabla que incluye los datos transformados junto con algunos datos adicionales mediante Azure Data Share.
En este laboratorio se usan datos de taxis de la ciudad de Nueva York. Para importarlos en la base de datos de SQL Database, descargue el archivo taxi-data.bacpac. Seleccione la opción Descargar archivo sin procesar en GitHub.
Requisitos previos
Suscripción de Azure: si no tiene una suscripción a Azure, cree una cuenta gratuita antes de empezar.
Azure SQL Database: si no tiene una base de datos de Azure SQL, consulte cómo crear una base de datos de Azure SQL.
Cuenta de almacenamiento de Azure Data Lake Storage Gen2: si no la tiene, aprenda a crear una cuenta de almacenamiento de ADLS Gen2.
Azure Synapse Analytics: si no tiene un área de trabajo de Azure Synapse Analytics, consulte cómo empezar con Azure Synapse Analytics.
Azure Data Factory: si no la ha creado, consulte cómo crear una factoría de datos.
Azure Data Share: si no lo ha creado, consulte cómo crear un recurso compartido de datos.
Configuración del entorno de Azure Data Factory
En esta sección aprenderá a acceder a la experiencia del usuario de Azure Data Factory (ADF UX) en Azure Portal. Una vez en la experiencia de usuario de ADF, configurará tres servicios vinculados para cada uno de los almacenes de datos que usamos: Azure SQL Database, ADLS Gen2 y Azure Synapse Analytics.
En los servicios vinculados de Azure Data Factory se define la información de conexión a los recursos externos. Actualmente, Azure Data Factory admite más de 85 conectores.
Apertura de la experiencia de usuario de Azure Data Factory
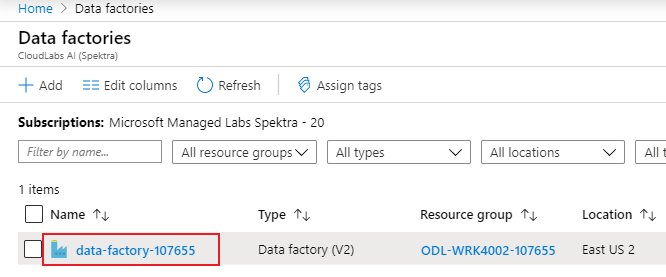
Abra Azure Portal en Microsoft Edge o Google Chrome.
Mediante la barra de búsqueda de la parte superior de la página, busque "Factorías de datos".
Seleccione el recurso de factoría de datos para abrir sus recursos en el panel izquierdo.
Seleccione Abrir Azure Data Factory Studio. También se puede acceder a Data Factory Studio directamente en adf.azure.com.
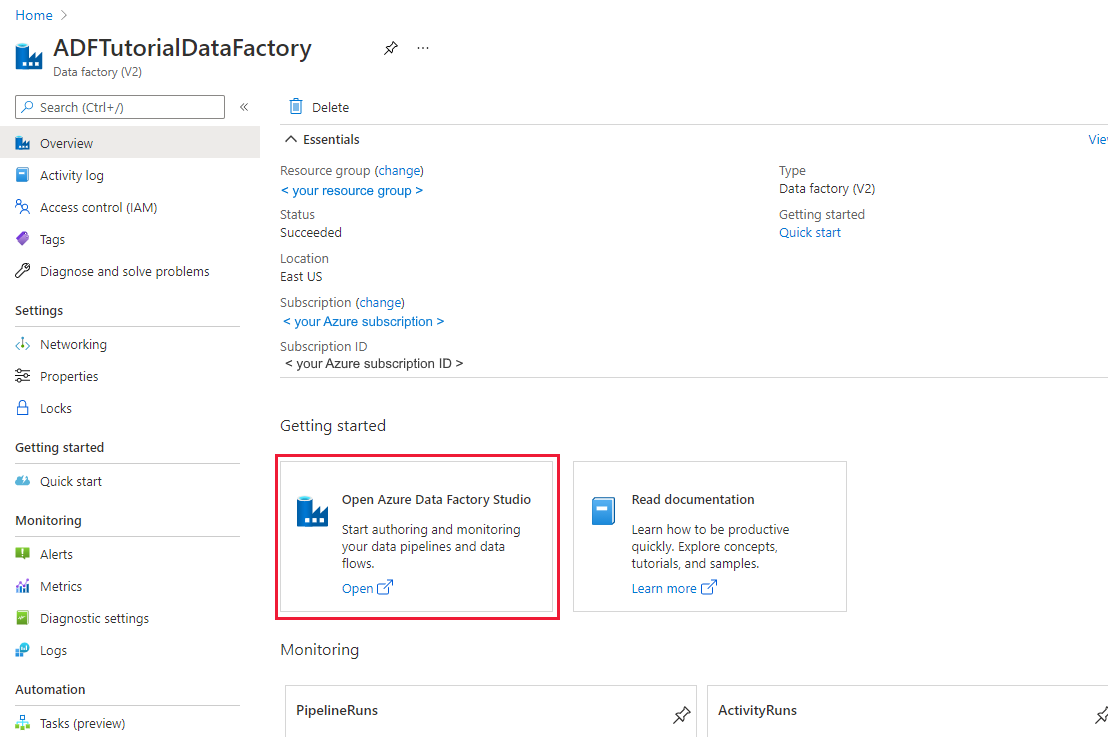
Se le redirigirá a la página principal de ADF en Azure Portal. Esta página contiene inicios rápidos, vídeos de instrucciones y vínculos a tutoriales para aprender los conceptos de factoría de datos. Para iniciar la creación, seleccione el icono de lápiz en la barra lateral izquierda.



Creación de un servicio vinculado de Azure SQL Database
Para crear un servicio vinculado, seleccione Administrar centro en la barra lateral izquierda; en el panel Conexiones, seleccione Servicios vinculados y, a continuación, seleccione Nuevo para agregar un nuevo servicio vinculado.

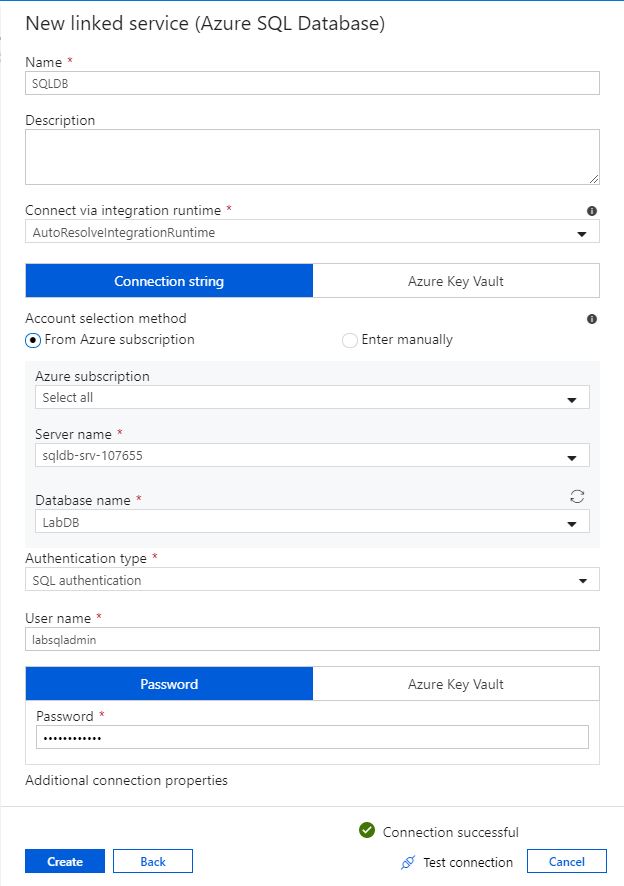
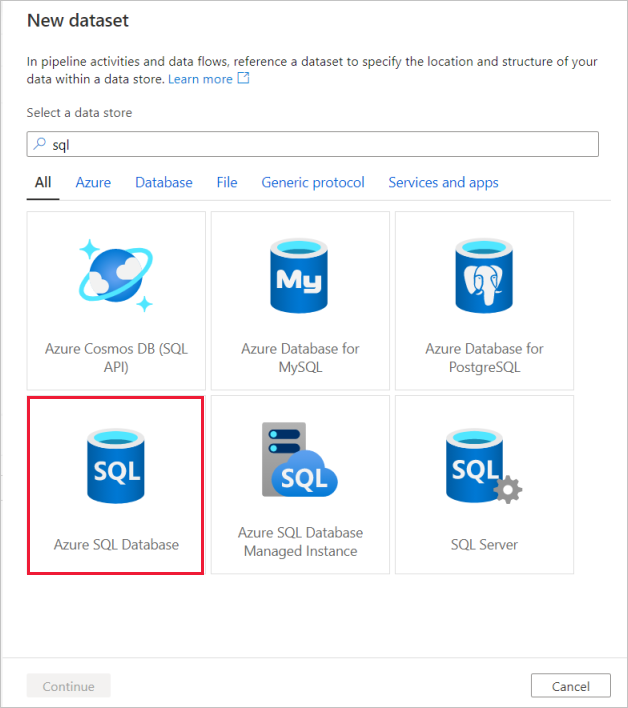
El primer servicio vinculado que configurará es el correspondiente a Azure SQL Database. Puede usar la barra de búsqueda para filtrar la lista de almacenes de datos. Seleccione el icono de Azure SQL Database y, después, Continuar.

En el panel de configuración de Azure SQL Database, escriba "SQLDB" como nombre del servicio vinculado. Escriba las credenciales para permitir que la factoría de datos se conecte a la base de datos. Si utiliza la autenticación de SQL, escriba el nombre del servidor, la base de datos, el nombre de usuario y la contraseña. Para comprobar que la información de conexión es correcta, seleccione Probar conexión. Cuando haya terminado, seleccione Crear.

Creación de un servicio vinculado de Azure Synapse Analytics
Repita el mismo proceso para agregar un servicio vinculado de Azure Synapse Analytics. En la pestaña de conexiones, seleccione Nueva. Seleccione el icono de Azure Synapse Analytics y, después, Continuar.
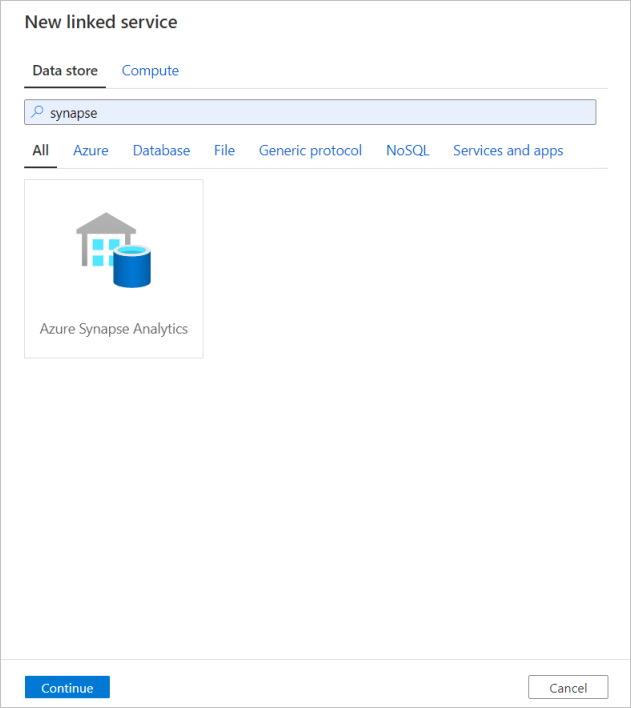
En el panel de configuración del servicio vinculado, escriba "SQLDW" como nombre del servicio vinculado. Escriba las credenciales para permitir que la factoría de datos se conecte a la base de datos. Si utiliza la autenticación de SQL, escriba el nombre del servidor, la base de datos, el nombre de usuario y la contraseña. Para comprobar que la información de conexión es correcta, seleccione Probar conexión. Cuando haya terminado, seleccione Crear.
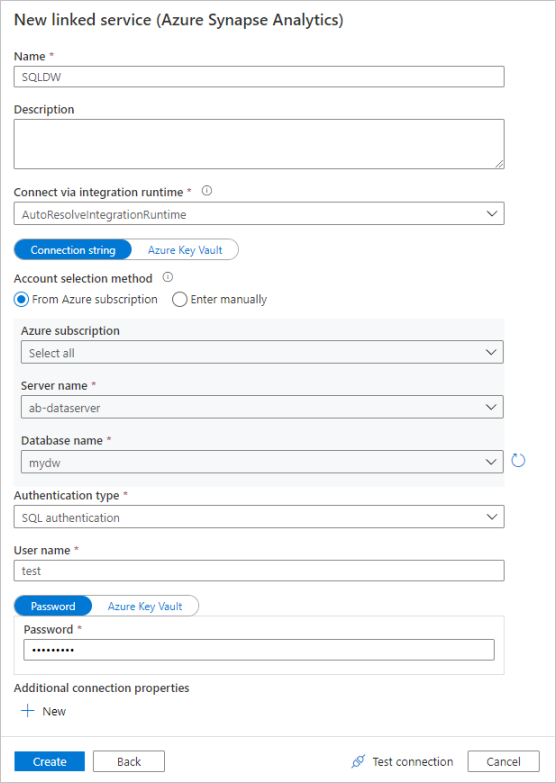
Creación de un servicio vinculado de Azure Data Lake Storage Gen2
El último servicio vinculado que se necesita para este laboratorio es el que corresponde a Azure Data Lake Storage Gen2. En la pestaña de conexiones, seleccione Nueva. Seleccione el icono de Azure Data Lake Storage Gen2 y, después, Continuar.
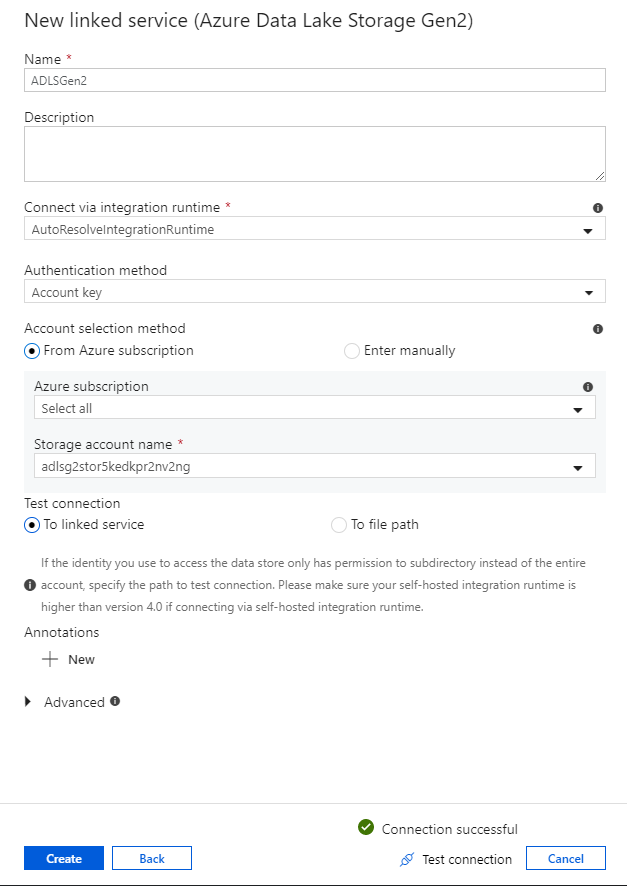
En el panel de configuración del servicio vinculado, escriba "ADLSGen2" como nombre del servicio vinculado. Si usa la autenticación de clave de cuenta, seleccione la cuenta de almacenamiento de ADLS Gen2 en la lista desplegable Nombre de la cuenta de almacenamiento. Para comprobar que la información de conexión es correcta, seleccione Probar conexión. Cuando haya terminado, seleccione Crear.
Activación del modo de depuración de flujos de datos
En la sección Transformación de datos mediante flujos de datos de asignación se creará este tipo de flujos de datos. Antes de crear flujos de datos de asignación, se recomienda activar el modo de depuración, que permite probar la lógica de transformación en segundos en un clúster de Spark activo.
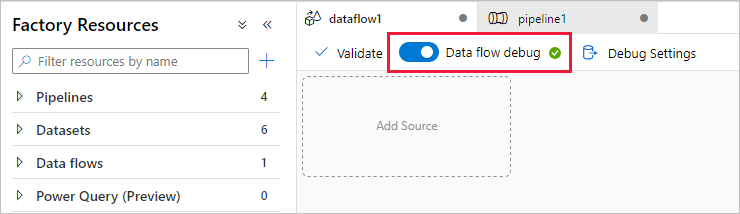
Para activar la depuración, seleccione el control deslizante Depuración de flujo de datos de la barra superior del lienzo del flujo de datos o del lienzo de la canalización cuando tenga actividades de flujo de datos. Seleccione Aceptar cuando aparezca el cuadro de diálogo de confirmación. El clúster tarda entre 5 y 7 minutos en iniciarse. Continúe en Ingesta de datos de Azure SQL Database en ADLS Gen2 mediante la actividad de copia mientras se inicializa.

Ingesta de datos mediante la actividad de copia
En esta sección, creará una canalización con una actividad de copia que ingiere una tabla de una instancia de Azure SQL Database en una cuenta de almacenamiento de ADLS Gen2. Aprenderá a agregar una canalización, a configurar un conjunto de datos y a depurar una canalización a través de la experiencia del usuario de ADF. El patrón de configuración que se usa en esta sección se puede aplicar a la copia desde un almacén de datos relacional hasta un almacén de datos basado en archivos.
En Azure Data Factory, una canalización es una agrupación lógica de actividades que realizan conjuntamente una tarea. Una actividad define una operación que se realizará en los datos. Un conjunto de datos apunta a los datos que se desean usar en un servicio vinculado.
Creación de una canalización con una actividad de copia
En el panel de recursos de Azure Data Factory, seleccione el icono de signo más para abrir el menú de nuevo recurso. Seleccione Pipeline (Canalización).
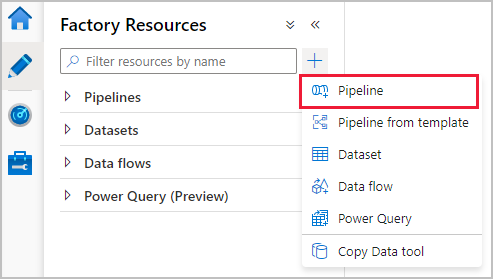
En la pestaña General del lienzo de la canalización, asigne un nombre descriptivo a la canalización, como "IngestAndTransformTaxiData".

En el panel de actividades del lienzo de la canalización, abra el acordeón Move and Transform (Mover y transformar) y arrastre la actividad Copy data (Copiar datos) al lienzo. Asigne un nombre descriptivo a la actividad de copia, como "IngestIntoADLS".



Configuración del conjunto de datos de origen de Azure SQL Database
Seleccione la pestaña Origen de la actividad de copia. Para crear un nuevo conjunto de datos, seleccione Nuevo. El origen será la tabla
dbo.TripDataque se encuentra en el servicio vinculado "SQLDB" configurado anteriormente.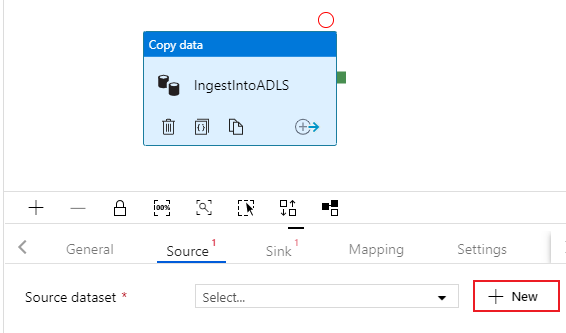
Busque Azure SQL Database y seleccione Continuar.
Asigne al conjunto de datos el nombre "TripData". Seleccione "SQLDB" como servicio vinculado. Seleccione la tabla denominada
dbo.TripDataen la lista desplegable de nombre de la tabla. Importe el esquema con la opción From connection/store (Desde la conexión o almacén). Seleccione Aceptar cuando termine.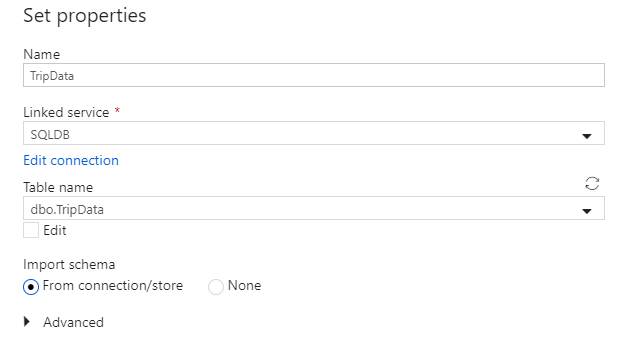
Ha creado correctamente el conjunto de datos de origen. Asegúrese de que la configuración de origen tiene seleccionado el valor predeterminado Table (Tabla) en el campo de uso de consulta.
Configuración del conjunto de datos del receptor de ADLS Gen2
Seleccione la pestaña Receptor de la actividad de copia. Para crear un nuevo conjunto de datos, seleccione Nuevo.
Busque Azure Data Lake Storage Gen2 y seleccione Continuar.
En el panel de selección de formato, elija DelimitedText, ya que escribe en un archivo CSV. Seleccione Continuar.

Asigne el nombre "TripDataCSV" al conjunto de datos del receptor. Seleccione "ADLSGen2" como servicio vinculado. Indique dónde desea escribir el archivo CSV. Por ejemplo, puede escribir los datos en el archivo
trip-data.csvdel contenedorstaging-container. Establezca First row as header (Primera fila como encabezado) en verdadero, ya que desea que los datos de salida tengan encabezados. Puesto que todavía no existe ningún archivo en el destino, establezca Import schema (Importar esquema) en None (Ninguno). Seleccione Aceptar cuando termine.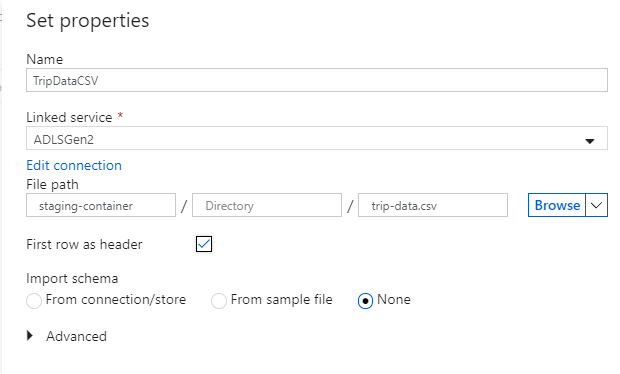
Prueba de la actividad de copia con una ejecución de depuración de la canalización
Para comprobar que la actividad de copia funciona correctamente, seleccione Depurar en la parte superior del lienzo de la canalización para realizar una ejecución de depuración. Este tipo de ejecución permite probar la canalización completa o hasta un punto de interrupción, antes de publicarla en el servicio de Azure Data Factory.

Para supervisar la ejecución de depuración, vaya a la pestaña Output (Salida) del lienzo de la canalización. La pantalla de supervisión se actualiza automáticamente cada 20 segundos o cuando seleccione manualmente el botón de actualización. La actividad de copia tiene una vista de supervisión especial a la que se puede acceder seleccionando el icono de gafas de la columna Acciones.
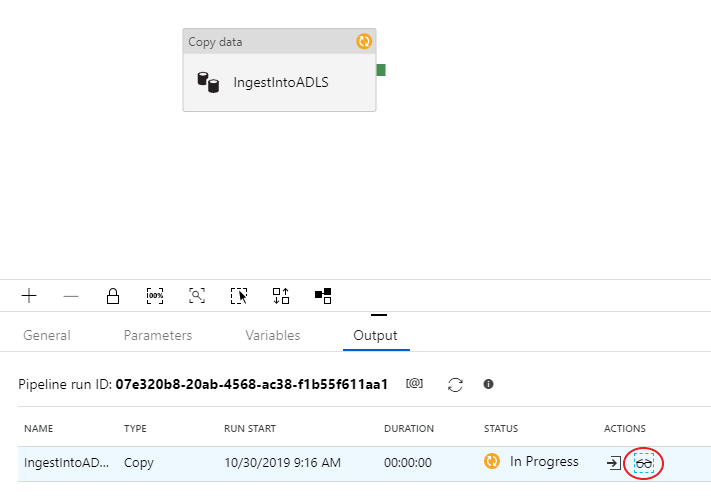
La vista de supervisión de la copia proporciona los detalles de ejecución y las características de rendimiento de la actividad. Puede ver información como los datos leídos y escritos, las filas leídas y escritas, los archivos leídos y escritos, y el rendimiento. Si está todo correctamente configurado, debería ver 49 999 filas escritas en un archivo del receptor de ADLS.

Antes de pasar a la sección siguiente, se recomienda publicar los cambios en el servicio de Azure Data Factory seleccionando Publicar todo en la barra superior de Azure Data Factory. Aunque no se trata en este laboratorio, Azure Data Factory admite la integración completa de Git. Esta integración permite realizar control de versiones, el almacenamiento iterativo en un repositorio y la colaboración en una factoría de datos. Para más información, consulte Control de código fuente en Azure Data Factory.


Transformación de datos mediante Mapping Data Flow
Ahora que ha copiado correctamente los datos en Azure Data Lake Storage, es el momento de combinarlos y agregarlos a un almacén de datos. Usamos el flujo de datos de asignación, el servicio de transformación con un diseño visual de Azure Data Factory. Los flujos de datos de asignación permiten a los usuarios desarrollar lógica de transformación sin código y ejecutarlos en clústeres de Spark administrados por el servicio ADF.
El flujo de datos creado en este paso realiza una combinación interna del conjunto de datos "TripDataCSV" creado en la sección anterior con una tabla dbo.TripFares almacenada en "SQLDB" basándose en cuatro columnas de clave. Después, los datos se agregan en función de la columna payment_type para calcular la media de determinados campos y se escriben en una tabla de Azure Synapse Analytics.
Incorporación de una actividad de flujo de datos a la canalización
En el panel de actividades del lienzo de la canalización, abra el acordeón Move and Transform (Mover y transformar) y arrastre la actividad Data flow (Flujo de datos) al lienzo.
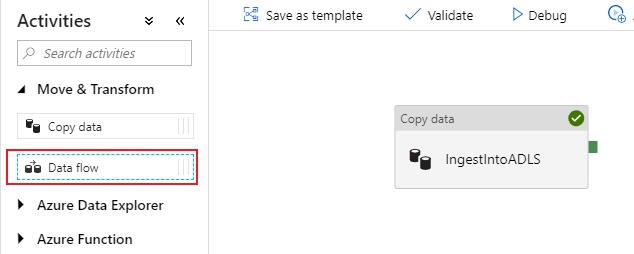
En el panel lateral que se abre, seleccione Create new data flow (Crear nuevo flujo de datos) y elija Mapping data flow (Flujo de datos de asignación). Seleccione Aceptar.

Se le redirigirá al lienzo de flujo de datos, donde creará la lógica de transformación. En la pestaña General, asigne el nombre "JoinAndAggregateData" al flujo de datos.



Configuración del origen de archivo CSV para los datos de carreras
Lo primero que desea hacer es configurar las dos transformaciones de origen. El primer origen apunta al conjunto de datos "TripDataCSV" de tipo DelimitedText. Para agregar una transformación de origen, seleccione el cuadro Agregar origen en el lienzo.
Asigne al origen el nombre "TripDataCSV" y seleccione el conjunto de datos "TripDataCSV" de la lista desplegable de origen. Si lo recuerda, inicialmente no importó un esquema al crear este conjunto de datos, ya que no había ningún dato en él. Puesto que ahora existe
trip-data.csv, seleccione Editar para ir a la pestaña de configuración del conjunto de datos.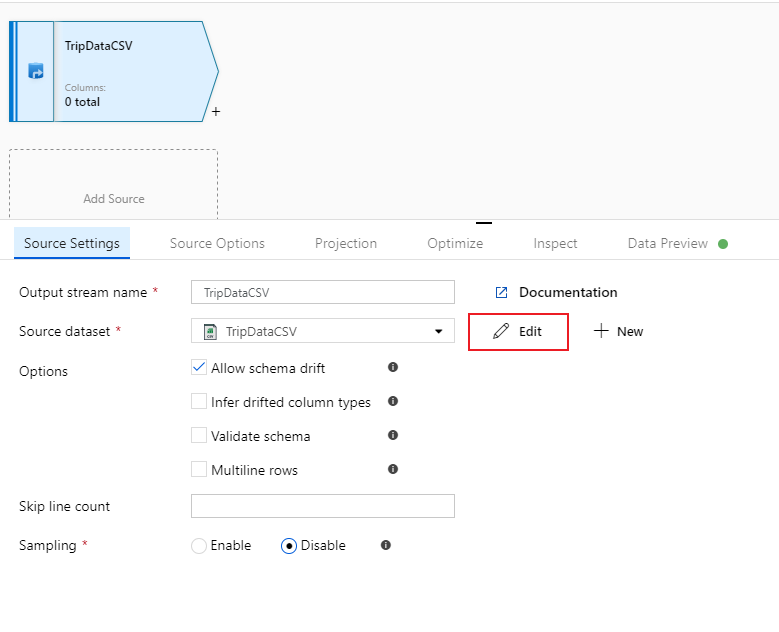
Vaya a la pestaña Esquema y seleccione Importar esquema. Seleccione From Connection/Store (Desde la conexión o almacén) para importar directamente desde el almacén de archivos. Deben aparecer 14 columnas de tipo cadena.
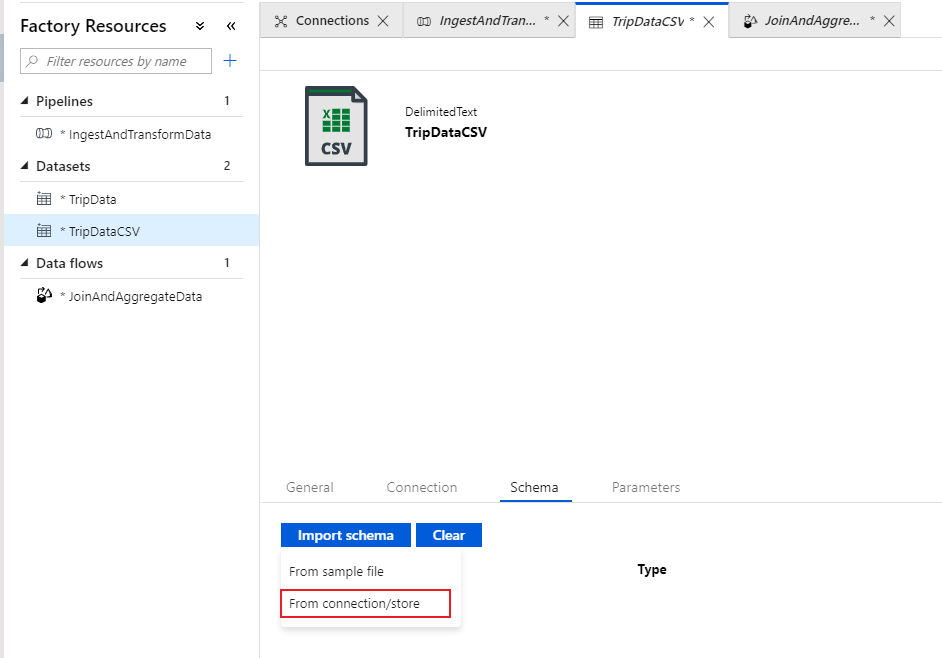
Vuelva al flujo de datos "JoinAndAggregateData". Si el clúster de depuración se ha iniciado (lo que se indica mediante un círculo verde junto al control deslizante de depuración), puede obtener una instantánea de los datos en la pestaña Vista previa de datos. Seleccione Actualizar para capturar una vista previa de los datos.
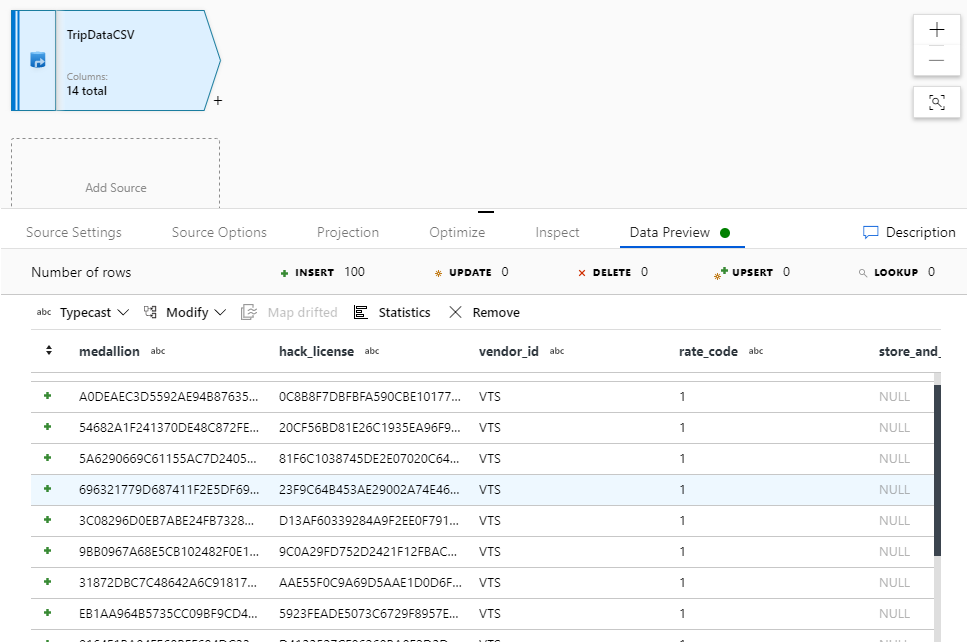


Nota:
La vista previa de los datos no escribe datos.
Configuración del origen de Azure SQL Database para las tarifas de carrera
El segundo origen que va a agregar puntos en la tabla de SQL Database
dbo.TripFares. Bajo el origen "TripDataCSV", habrá otro cuadro: Agregar origen. Selecciónelo para agregar una nueva transformación de origen.
Asigne a este origen el nombre "TripFaresSQL". Haga clic en Nuevo, junto al campo del conjunto de datos de origen, para crear un nuevo conjunto de datos de Azure SQL Database.
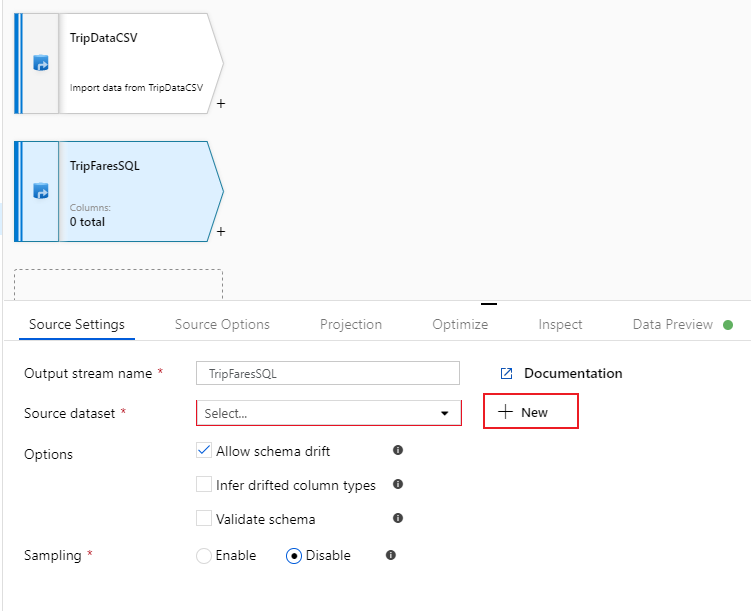
Seleccione el icono de Azure SQL Database y, después, Continuar. Puede observar que muchos de los conectores de factoría de datos no se admiten en el flujo de datos de asignación. Para transformar los datos de uno de estos orígenes, realice la ingesta en un origen compatible mediante la actividad de copia.

Llame al conjunto de datos "TripFares". Seleccione "SQLDB" como servicio vinculado. Seleccione la tabla denominada
dbo.TripFaresen la lista desplegable de nombre de la tabla. Importe el esquema con la opción From connection/store (Desde la conexión o almacén). Seleccione Aceptar cuando termine.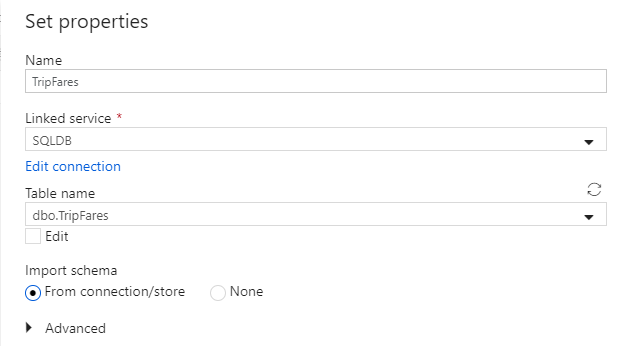
Para comprobar los datos, capture una vista previa en la pestaña Data Preview (Vista previa de datos).


Combinación interna de TripDataCSV y TripFaresSQL
Para agregar una nueva transformación, seleccione el icono de signo más situado en la esquina inferior derecha de "TripDataCSV". En Multiple inputs/outputs (Varias entradas y salidas), seleccione Join (Combinación).
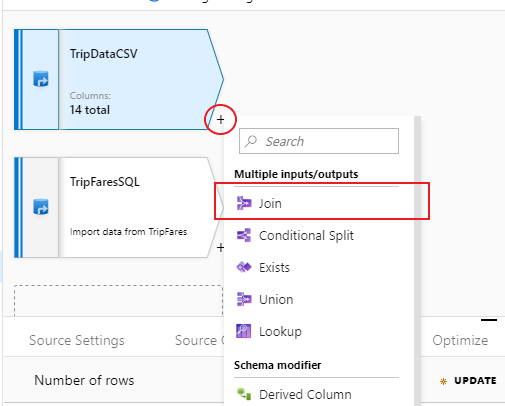
Asigne a la transformación de combinación el nombre "InnerJoinWithTripFares". Seleccione "TripFaresSQL" en la lista desplegable del flujo derecho. Seleccione Inner (Interna) como tipo de combinación. Para más información sobre los diferentes tipos de combinación en el flujo de datos de asignación, consulte Tipos de combinación.
Seleccione en cada flujo las columnas con las que desea establecer coincidencias, a través de la lista desplegable Condiciones de combinación. Para agregar otra condición de combinación, seleccione el icono de signo más situado junto a una condición existente. De forma predeterminada, todas las condiciones de combinación se unen mediante un operador AND, lo que significa que se deben cumplir todas las condiciones para establecer una coincidencia. En este laboratorio, deseamos establecer las coincidencias de las columnas
medallion,hack_license,vendor_idypickup_datetime.
Compruebe que ha combinado correctamente 25 columnas junto con una vista previa de los datos.



Agregado por payment_type
Después de completar la transformación de combinación, agregue una transformación de agregado; para ello, seleccione el icono de signo más situado junto a InnerJoinWithTripFares. Elija Aggregate (Agregado) en Schema modifier (Modificador de esquema).
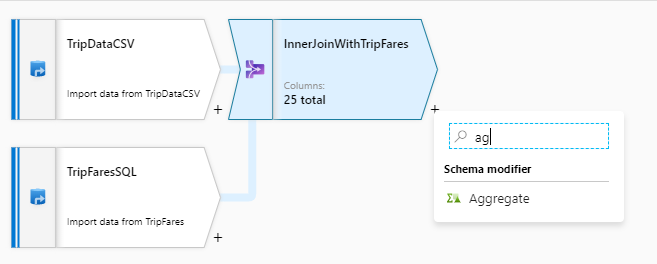
Denomine "AggregateByPaymentType" a la transformación de agregado. Seleccione
payment_typecomo columna de agrupación.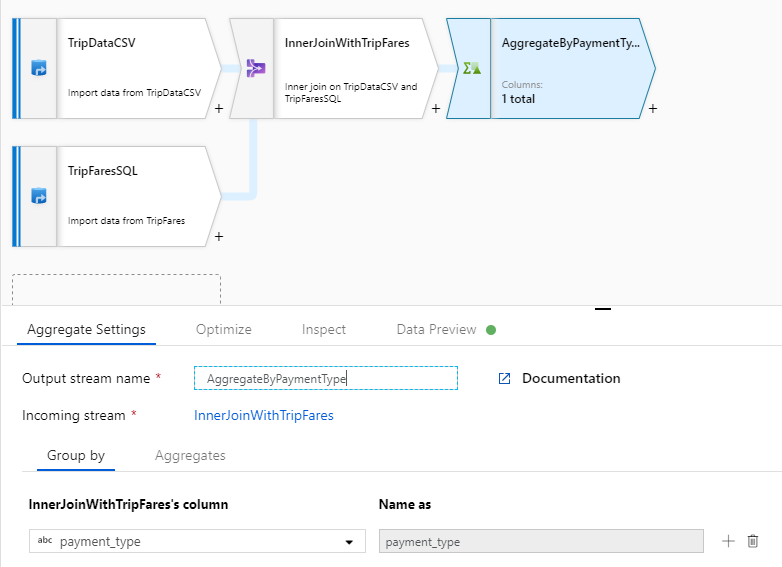
Vaya a la pestaña Agregados. Especifique dos agregaciones:
- La tarifa media agrupada por tipo de pago
- La distancia total de la carrera agrupada por tipo de pago
En primer lugar, creará la expresión para la tarifa media. En el cuadro de texto con la etiqueta Add or select a column (Agregar o seleccionar una columna), escriba "tarifa_media".

Para escribir una expresión para agregar, seleccione el cuadro azul con la etiqueta Introducir expresión, que abre el generador de expresiones de flujo de datos, una herramienta que se usa para crear estas expresiones de forma visual mediante un esquema de entrada, funciones y operaciones integradas, y parámetros definidos por el usuario. Para más información sobre las funcionalidades del generador de expresiones, consulte la documentación del generador de expresiones.
Para obtener la tarifa media, utilice la función de agregación
avg()para agregar la columnatotal_amountconvertida en un entero contoInteger(). En el lenguaje de expresiones de flujo de datos, esta operación se define comoavg(toInteger(total_amount)). Seleccione Guardar y finalizar cuando haya terminado.
Para agregar otra expresión de agregación, seleccione el icono de signo más situado junto a
average_fare. Seleccione Add column (Agregar columna).
En el cuadro de texto con la etiqueta Add or select a column (Agregar o seleccionar una columna), escriba "total_trip_distance". Como en el último paso, abra el generador de expresiones para escribir la expresión.
Para obtener la distancia total de la carrera, utilice la función de agregación
sum()para agregar la columnatrip_distanceconvertida en un entero contoInteger(). En el lenguaje de expresiones de flujo de datos, esta operación se define comosum(toInteger(trip_distance)). Seleccione Guardar y finalizar cuando haya terminado.
Pruebe la lógica de la transformación en la pestaña Data Preview (Vista previa de datos). Como puede ver, hay bastantes menos filas y columnas que antes. Solo las tres columnas de agrupación y agregación definidas en esta transformación continúan en sentido descendente. Dado que solo hay cinco grupos de tipos de pago en el ejemplo, solo se genera una salida de cinco filas.






Configuración del receptor de Azure Synapse Analytics
Ahora que hemos terminado la lógica de la transformación, estamos preparados para recibir los datos en una tabla de Azure Synapse Analytics. Agregue una transformación de receptor en la sección Destination (Destino).

Asigne al receptor el nombre "SQLDWSink". Seleccione Nuevo junto al campo de conjunto de datos de receptor para crear un nuevo conjunto de datos de Azure Synapse Analytics.
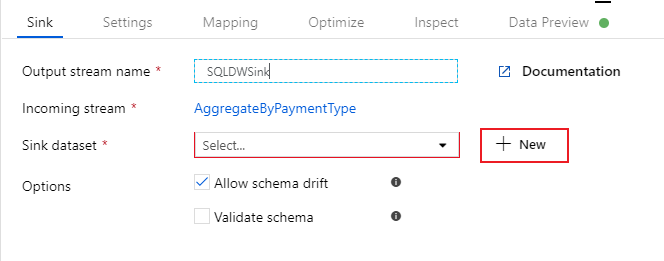
Seleccione el icono de Azure Synapse Analytics y, después, Continuar.
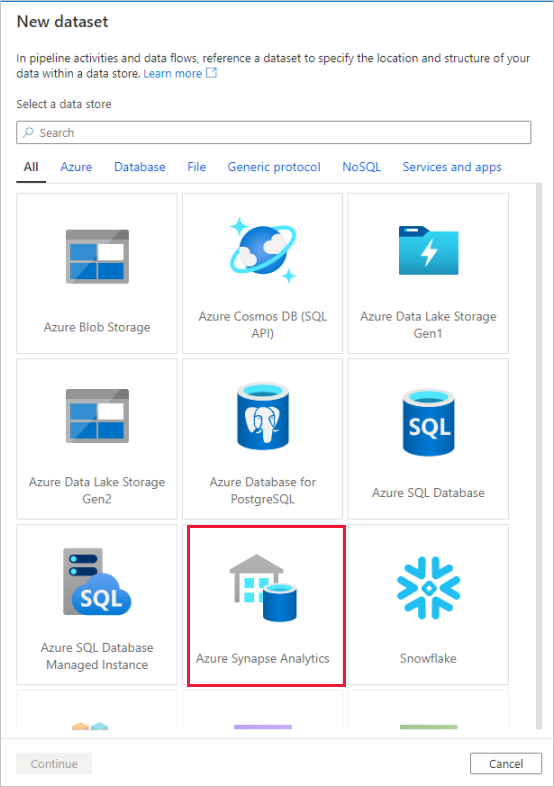
Llame al conjunto de datos "AggregatedTaxiData". Seleccione "SQLDW" como servicio vinculado. Seleccione Crear nueva tabla y asigne a la nueva tabla el nombre
dbo.AggregateTaxiData. Cuando haya terminado, seleccione Aceptar.
Vaya a la pestaña Settings (Configuración) del receptor. Dado que estamos creando una nueva tabla, debemos seleccionar Recreate table (Volver a crear tabla) en Table action (Acción de tabla). Anule la selección de Enable staging (Habilitar almacenamiento provisional), que alterna si la inserción se realizará fila a fila o bien por lotes.



Ha creado correctamente el flujo de datos. Ahora es el momento de ejecutarlo en una actividad de canalización.
Depuración de la canalización completa
Vuelva a la pestaña de la canalización IngestAndTransformData. Observe el cuadro verde en la actividad de copia "IngestIntoADLS". Arrástrela sobre la actividad de flujo de datos "JoinAndAggregateData". De este modo se crea una condición "en caso de éxito", que determina que la actividad de flujo de datos solo se ejecutará si la copia se realiza correctamente.
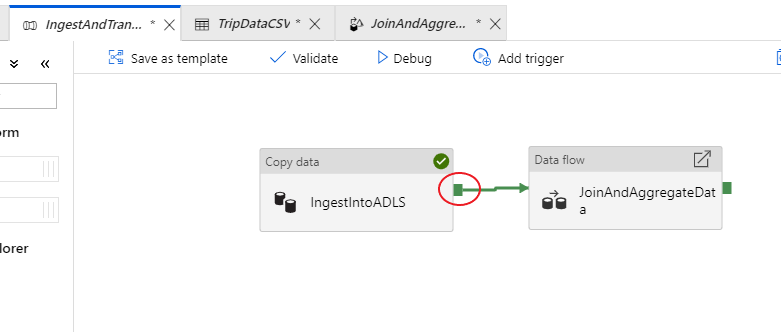
Como hicimos en la actividad de copia, seleccione Depurar para llevar a cabo una ejecución de depuración. En las ejecuciones de depuración, la actividad de flujo de datos usa el clúster de depuración activo en lugar de crear un nuevo clúster. Esta canalización tarda poco más de un minuto en ejecutarse.

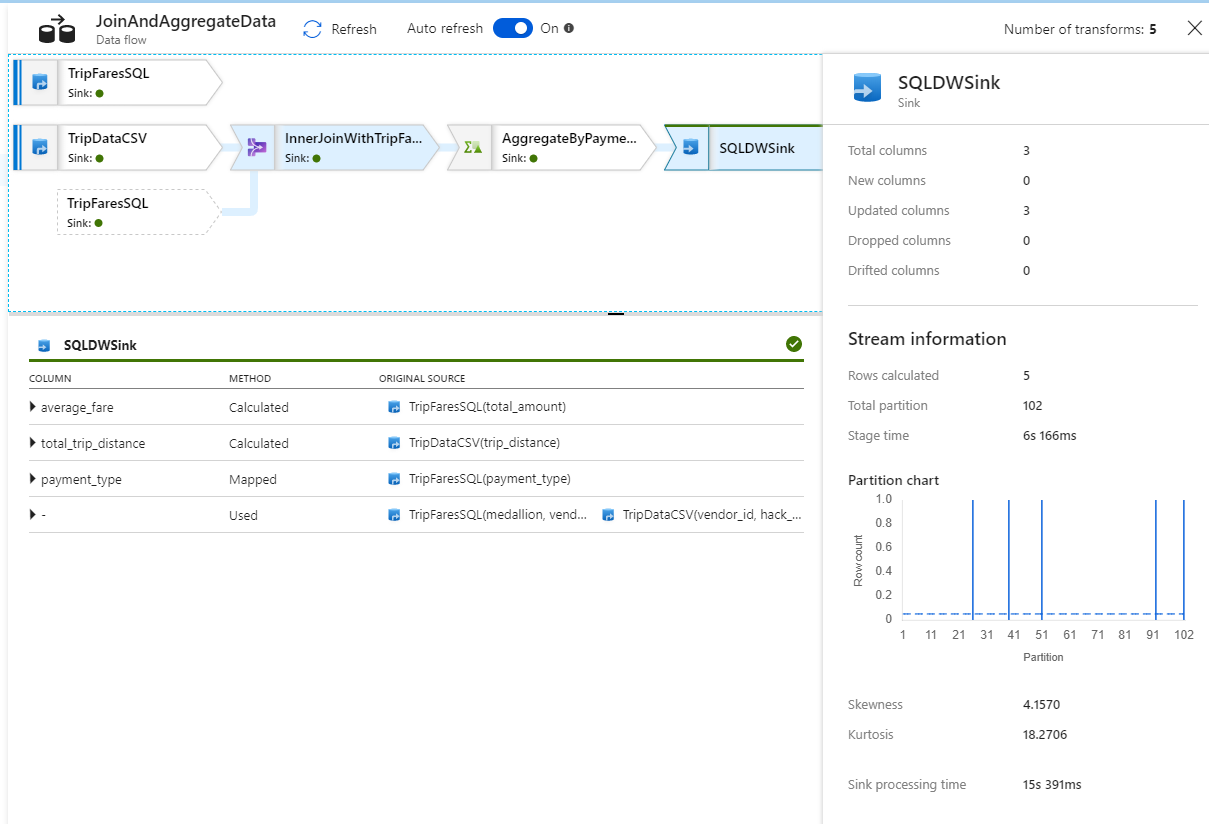
Al igual que ocurre con la actividad de copia, el flujo de datos tiene una vista de supervisión especial a la que se accede mediante el icono con forma de gafas al finalizar la actividad.

En la vista de supervisión, puede ver un gráfico de flujo de datos simplificado junto con los tiempos de ejecución y las filas de cada fase de la ejecución. Si se ejecuta correctamente, en esta actividad se deben agregar 49 999 filas en cinco filas.

Puede seleccionar una transformación para obtener detalles adicionales sobre su ejecución, como la información de creación de particiones y las columnas nuevas, actualizadas o eliminadas.




Ya ha completado la parte de Azure Data Factory de este laboratorio. Publique los recursos si desea ponerlos en funcionamiento con desencadenadores. Ejecutó correctamente una canalización que realizó la ingesta de datos de Azure SQL Database en Azure Data Lake Storage mediante la actividad de copia y, a continuación, agregó esos datos a una instancia de Azure Synapse Analytics. Para comprobar que los datos se escribieron correctamente, examine la propia instancia de SQL Server.
Uso compartido de datos mediante Azure Data Share
En esta sección aprenderá a configurar un nuevo recurso compartido de datos mediante Azure Portal. Esto implica la creación de un nuevo recurso compartido de datos que contiene conjuntos de datos de Azure Data Lake Storage Gen2 y Azure Synapse Analytics. Después, configurará una programación de instantáneas, que proporcionará a los consumidores de datos una opción para actualizar automáticamente los datos que se compartan con ellos. A continuación, invitará a los destinatarios al recurso compartido de datos.
Después de crear el recurso compartido de datos, cambiará su papel y se convertirá en el consumidor de datos. Como consumidor de datos, pasará por el flujo de aceptación de una invitación al recurso compartido de datos, la configuración de la ubicación donde quiere recibir los datos y la asignación de los conjuntos de datos a diferentes ubicaciones de almacenamiento. A continuación, desencadenará una instantánea que copiará los datos compartidos en el destino especificado.
Compartir datos (flujo del proveedor de datos)
Abra Azure Portal en Microsoft Edge o Google Chrome.
Mediante la barra de búsqueda de la parte superior de la página, busque Recursos compartidos de datos.
Seleccione la cuenta de recurso compartido de datos con "Provider" en el nombre. Por ejemplo, DataProvider0102.
Seleccione Empezar a compartir los datos.

Seleccione + Crear para comenzar a configurar el nuevo recurso compartido de datos.
En Nombre del recurso compartido, especifique un nombre de su elección. Este es el nombre del recurso compartido que verá el consumidor de datos; por tanto, asegúrese de darle un nombre descriptivo como, por ejemplo, TaxiData.
En Descripción, incluya una frase que describa el contenido del recurso compartido de datos. Este recurso contiene datos de carreras de taxis de todo el mundo, guardados en una serie de almacenes entre los que se incluyen Azure Synapse Analytics y Azure Data Lake Storage.
En Condiciones de uso, especifique un conjunto de condiciones que le gustaría que el consumidor de datos aceptase. Algunos ejemplos pueden ser "No distribuya estos datos fuera de la organización" o "Consulte el contrato legal".

Seleccione Continuar.
Seleccione Agregar conjuntos de datos.

Seleccione Azure Synapse Analytics para elegir la tabla de la instancia de Azure Synapse Analytics en la que se descargaron las transformaciones de ADF.
Se le proporciona un script para que lo ejecute antes de continuar. Este script crea un usuario en la base de datos SQL que permite que la identidad MSI de Azure Data Share se autentique en su nombre.
Importante
Antes de ejecutar el script, debe establecerse como administrador de Active Directory para el servidor lógico de SQL de Azure SQL Database.
Abra una nueva pestaña y vaya a Azure Portal. Copie el script proporcionado para crear un usuario en la base de datos cuyos datos desea compartir. Para ello, inicie sesión en la base de datos EDW mediante el editor de consultas de Azure Portal usando la autenticación de Microsoft Entra. Debe modificar el usuario en el siguiente script de ejemplo:
CREATE USER [dataprovider-xxxx@contoso.com] FROM EXTERNAL PROVIDER; ALTER ROLE db_owner ADD MEMBER [wiassaf@microsoft.com];Vuelva a la instancia de Azure Data Share donde estaba agregando los conjuntos de datos al recurso compartido de datos.
Seleccione EDW y, a continuación, seleccione AggregatedTaxiData para la tabla.
Seleccione Agregar conjunto de datos.
Ahora contamos con una tabla SQL que forma parte de nuestro conjunto de datos. A continuación, agregaremos otros conjuntos de datos desde Azure Data Lake Storage.
Seleccione Agregar conjunto de datos y elija Azure Data Lake Storage Gen2

Seleccione Siguiente.
Expanda wwtaxidata. Expanda Boston Taxi Data. Puede compartir hasta el nivel de archivo.
Seleccione la carpeta Boston Taxi Data para agregarla completa a al recurso compartido de datos.
Seleccione Agregar conjuntos de datos.
Revise los conjuntos de datos que se han agregado. Se deberían haber agregado una tabla SQL y una carpeta de ADLS Gen2 al recurso compartido de datos.
Seleccione Continuar
En esta pantalla, puede agregar destinatarios al recurso compartido de datos. Los destinatarios que agregue recibirán invitaciones a ese recurso. Para este laboratorio, debe agregar dos direcciones de correo electrónico:
La dirección de correo electrónico de la suscripción de Azure en la que se encuentra.

Agregue el consumidor de datos ficticio denominado janedoe@fabrikam.com .
En esta pantalla, puede realizar una configuración de instantánea para el consumidor de datos. Esto les permite recibir actualizaciones periódicas de los datos según el intervalo que defina.
Marque Programación de instantáneas y configure una actualización cada hora de los datos mediante la lista desplegable Periodicidad.
Seleccione Crear.
Ahora tiene un recurso compartido de datos activo. Revisemos qué puede ver como proveedor de datos cuando crea un recurso compartido de datos.
Seleccione el recurso compartido de datos que ha creado, de nombre TaxiData. Puede navegar hasta él seleccionando Recursos compartidos enviados en Recurso compartido de datos.
Seleccione Programación de instantáneas. Puede deshabilitar la programación de instantáneas, si lo desea.
A continuación, seleccione la pestaña Conjuntos de datos. Puede agregar otros conjuntos de datos a este recurso compartido de datos una vez creado.
Seleccione la pestaña Suscripciones a recursos compartidos. Todavía no existen suscripciones a recursos compartidos porque el consumidor de datos aún no ha aceptado la invitación.
Vaya a la pestaña Invitaciones. Aquí verá una lista de las invitaciones pendientes.
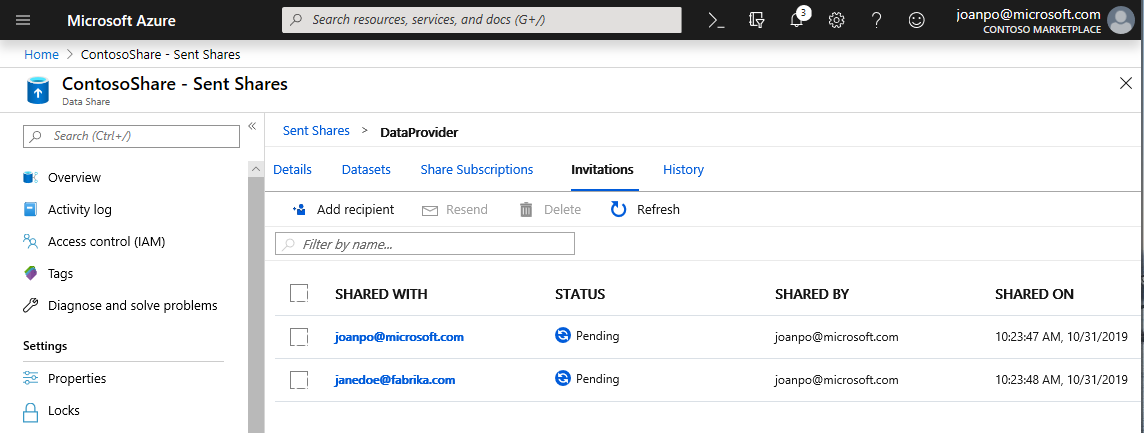
Seleccione la invitación a janedoe@fabrikam.com . Seleccione Eliminar. Si el destinatario todavía no ha aceptado la invitación, ya no podrá hacerlo.
Seleccione la pestaña Historial . Aún no se muestra nada, porque el consumidor de datos todavía no ha aceptado la invitación ni desencadenado una instantánea.






Recepción de datos (flujo del consumidor de datos)
Ahora que hemos revisado el recurso compartido de datos, estamos preparados para cambiar de contexto y pasar a nuestro papel como consumidor de datos.
En estos momentos debería tener una invitación de Microsoft Azure para Azure Data Share en la bandeja de entrada. Inicie Outlook Web Access (outlook.com) e inicie sesión con las credenciales proporcionadas para la suscripción de Azure.
En el correo electrónico que debe haber recibido, seleccione "Ver invitación >". Ahora va a simular la experiencia del consumidor de datos cuando acepta una invitación del proveedor de datos para el recurso compartido de datos.

Puede que se le pida que seleccione una suscripción. Asegúrese de seleccionar la suscripción en la que ha estado trabajando para este laboratorio.
Seleccione la invitación titulada DataProvider.
En esta pantalla de Invitación, aparecen varios detalles sobre el recurso compartido de datos que configuró anteriormente como proveedor de datos. Revise los detalles y acepte las condiciones de uso, si se indicaron.
Seleccione la suscripción y el grupo de recursos que ya existen para el laboratorio.
En Data share account (Cuenta de Azure Data Share), seleccione DataConsumer. También puede crear una nueva cuenta de Azure Data Share.
Junto a Nombre del recurso compartido recibido, aparece el nombre del recurso compartido predeterminado es el nombre especificado por el proveedor de datos. Asigne al recurso compartido un nombre descriptivo para los datos que va a recibir, por ejemplo TaxiDataShare.

Puede optar por elegir la opción Accept and configure now (Aceptar y configurar ahora) o bien Accept and configure later (Aceptar y configurar más adelante). Si decide aceptar y configurar ahora, especifique una cuenta de almacenamiento en la que se deberán copiar todos los datos. Si decide aceptar y configurar más adelante, no se asignarán los conjuntos de datos del recurso compartido y deberá asignarlos manualmente. Elegiremos la opción para más adelante.
Seleccione Accept and configure later (Aceptar y configurar más adelante).
Cuando configure esta opción, se habrá creado una suscripción al recurso compartido, pero no habrá ninguna ubicación en la que recibir los datos, ya que no se ha asignado ningún destino.
A continuación, configuraremos las asignaciones de conjunto de datos para el recurso compartido de datos.
Seleccione el recurso compartido recibido (el nombre que especificó en el paso 5).
La opción Desencadenar instantánea está atenuada, pero el recurso compartido está activo.
Seleccione la pestaña Conjuntos de datos. Cada conjunto de datos tiene el estado No asignado, lo que significa que no tiene ningún destino en el que copiar los datos.

Seleccione la tabla de Azure Synapse Analytics y, a continuación, seleccione + Asignar a destino.
En el lado derecho de la pantalla, seleccione la lista desplegable Tipo de datos de destino.
Puede asignar los datos de SQL a una amplia gama de almacenes de datos. En este caso, los asignaremos a una instancia de Azure SQL Database.
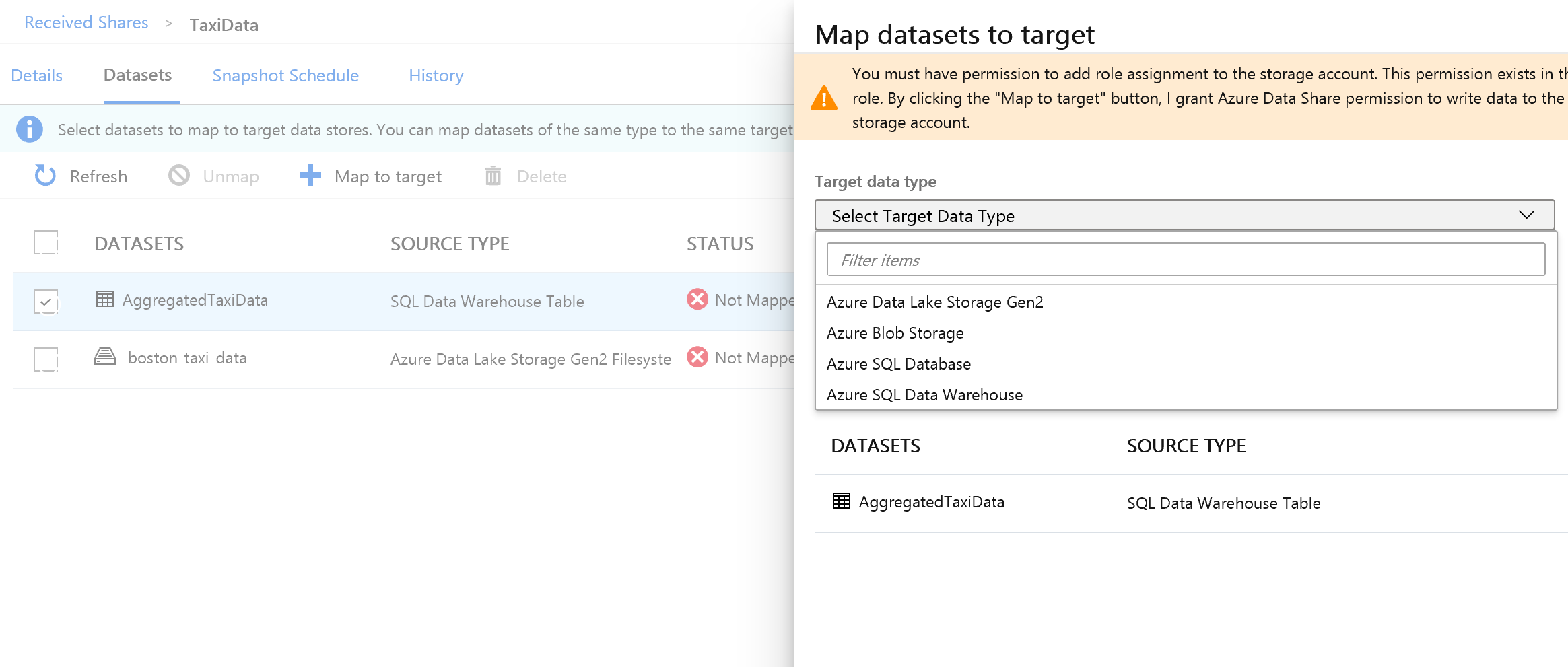
(Opcional) Seleccione Azure Data Lake Storage Gen2 como tipo de datos de destino.
(Opcional) Seleccione la suscripción, el grupo de recursos y la cuenta de almacenamiento con los que ha estado trabajando.
(Opcional) Puede elegir si recibe los datos en el lago de datos en formato CSV o Parquet.
Junto a Tipo de datos de destino, seleccione Azure SQL Database.
Seleccione la suscripción, el grupo de recursos y la cuenta de almacenamiento con los que ha estado trabajando.
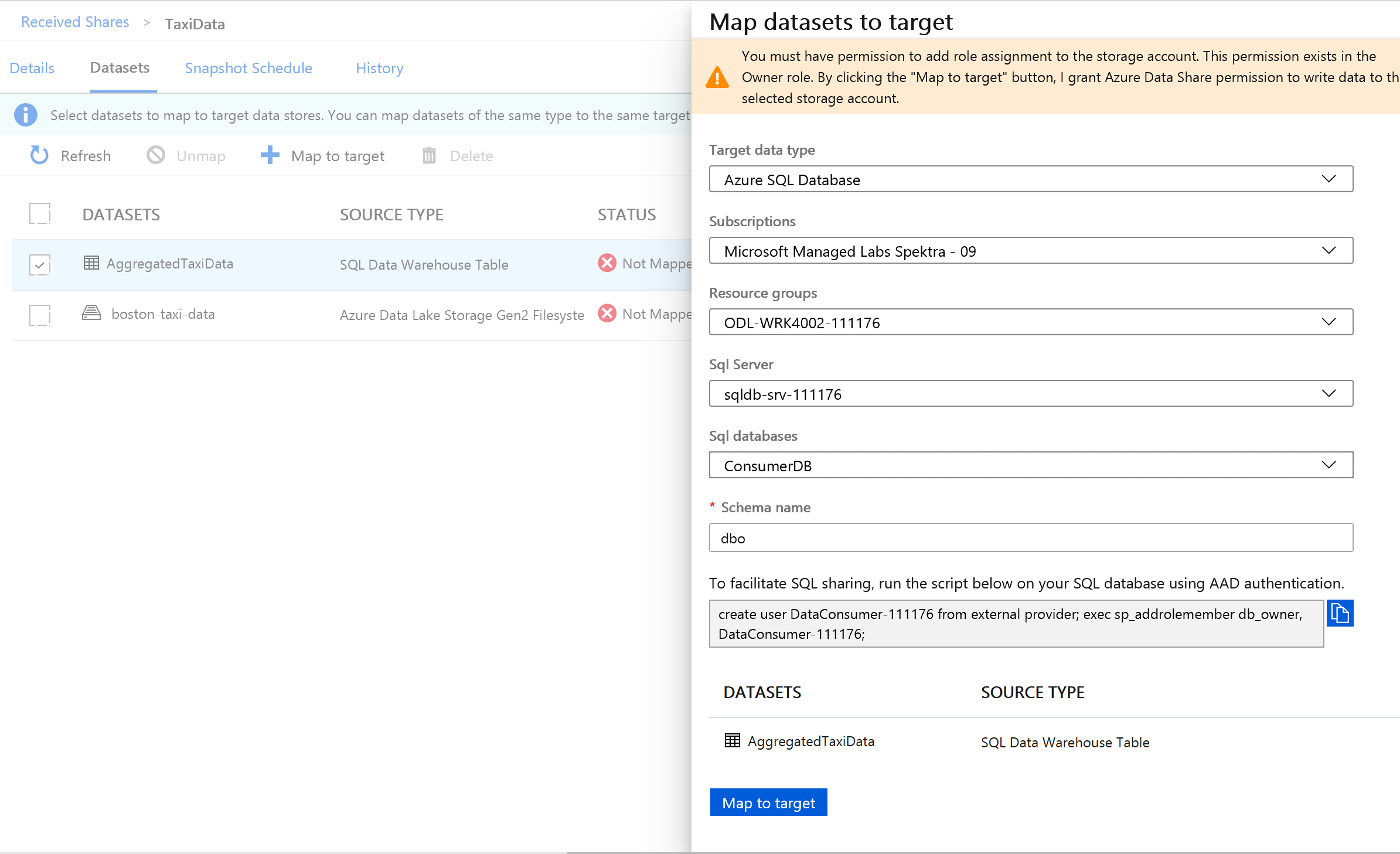
Para poder continuar, debe crear un nuevo usuario en la instancia de SQL Server mediante la ejecución del script proporcionado. En primer lugar, copie el script proporcionado en el portapapeles.
Abra una nueva pestaña de Azure Portal. No cierre la pestaña existente, ya que tendrá que volver a ella en un momento.
En la nueva pestaña que ha abierto, vaya a SQL Database.
Seleccione la base de datos SQL (solo debe haber una en la suscripción). Tenga cuidado de no seleccionar el almacenamiento de datos.
Seleccione Editor de consultas (versión preliminar) .
Use la autenticación de Microsoft Entra para iniciar sesión en el editor de consultas.
Ejecute la consulta proporcionada en el recurso compartido de datos (que copió en el portapapeles en el paso 14).
Este comando permite al servicio Azure Data Share usar identidades administradas para que los servicios de Azure se autentiquen en la instancia de SQL Server y poder copiar datos en ella.
Vuelva a la pestaña original y seleccione Asignar a destino.
A continuación, seleccione la carpeta Azure Data Lake Storage Gen2 que forma parte del conjunto de datos y asígnela a una cuenta de Azure Blob Storage.

Con todos los conjuntos de datos asignados, ya está listo para empezar a recibir datos del proveedor de datos.

Seleccione Detalles.
La opción Desencadenar instantánea ya no está atenuada, puesto que ahora el recurso compartido de datos tiene destinos en los que copiar.
Seleccione Desencadenar instantánea ->Copia completa.
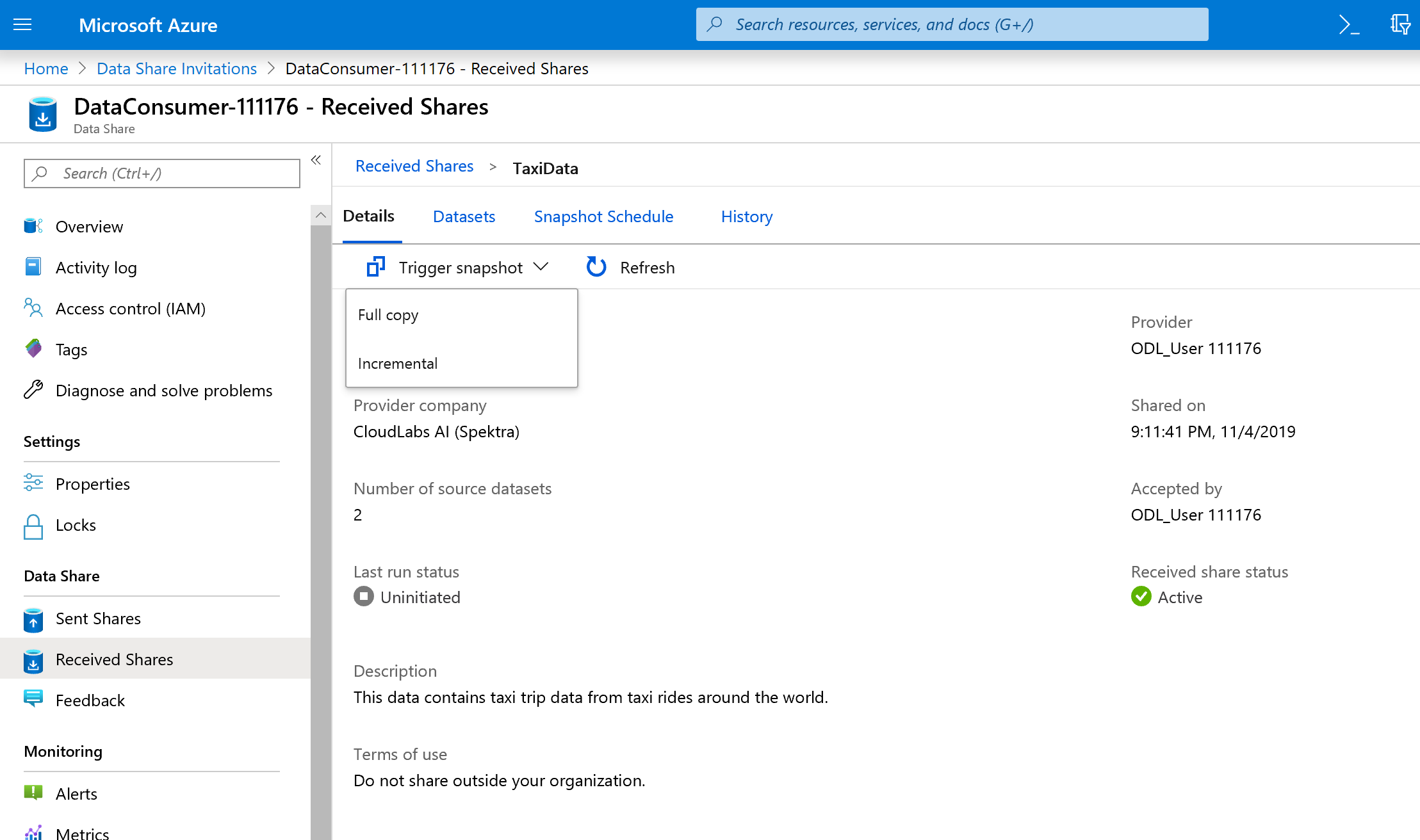
De este modo se inicia la copia de datos en la nueva cuenta de Azure Data Share. En un escenario real, estos datos procederían de un tercero.
Los datos tardarán entre 3 y 5 minutos en aparecer. Para supervisar el progreso, seleccione la pestaña Historial.
Mientras espera, vaya hasta el recurso compartido de datos original (TaxiData) y vea el estado de Suscripciones a recursos compartidos y la pestaña Historial. Ahora hay una suscripción activa; como proveedor de datos, también puede supervisar cuándo el consumidor de datos ha empezado a recibir los datos compartidos con él.
Vuelva al recurso compartido de datos del consumidor de datos. Una vez que el estado del desencadenador sea correcto, vaya a la base de datos SQL de destino y al lago de datos para comprobar que los datos se han descargado en los almacenes correspondientes.







¡Enhorabuena, ha completado el laboratorio!