Copia de datos de Azure Data Lake Storage Gen1 en Gen2 con Azure Data Factory
SE APLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Pruebe Data Factory en Microsoft Fabric, una solución de análisis todo en uno para empresas. Microsoft Fabric abarca todo, desde el movimiento de datos hasta la ciencia de datos, el análisis en tiempo real, la inteligencia empresarial y los informes. ¡Obtenga más información sobre cómo iniciar una nueva evaluación gratuita!
Azure Data Lake Storage Gen2 es un conjunto de funciones dedicadas al análisis de macrodatos compilado en Azure Blob Storage. Puede usarlo para interactuar con los datos usando el paradigma de sistema de archivos o el de almacenamiento de objetos.
Si actualmente usa Azure Data Lake Storage Gen1, puede evaluar Azure Data Lake Storage Gen2 mediante la copia de datos de Data Lake Storage Gen1 en Gen2 con Azure Data Factory.
Azure Data Factory es un servicio de integración de datos en la nube totalmente administrado. Puede utilizar el servicio para rellenar el lago con datos de un amplio conjunto de almacenes de datos locales y basados en la nube y, de este modo, ahorrar tiempo cuando compile las soluciones de análisis. Para obtener una lista de conectores admitidos, vea la tabla de Almacenes de datos admitidos.
Azure Data Factory ofrece una solución de movimiento de datos administrados y de escalabilidad horizontal. Debido a la arquitectura con escalabilidad horizontal de Data Factory, puede ingerir datos con un alto rendimiento. Para obtener más información, vea el artículo Copiar rendimiento de actividad.
En este artículo se muestra cómo utilizar la herramienta Copiar datos de Data Factory para copiar datos de Azure Data Lake Storage Gen1 en Azure Data Lake Storage Gen2. Puede seguir los mismos pasos para copiar datos de otros tipos de almacenes de datos.
Prerrequisitos
- Suscripción a Azure. Si no tiene una suscripción a Azure, cree una cuenta gratuita antes de empezar.
- Cuenta de Azure Data Lake Storage Gen1 con datos en ella.
- Cuenta de Azure Storage con Data Lake Storage Gen2 habilitado. Si no tiene una cuenta de Storage, debe crear una.
Crear una factoría de datos
Si aún no ha creado la factoría de datos, siga los pasos descritos en Inicio rápido: Creación de una factoría de datos mediante Azure Portal y Azure Data Factory Studio para crear una. Después de crearla, vaya a la factoría de datos en Azure Portal.
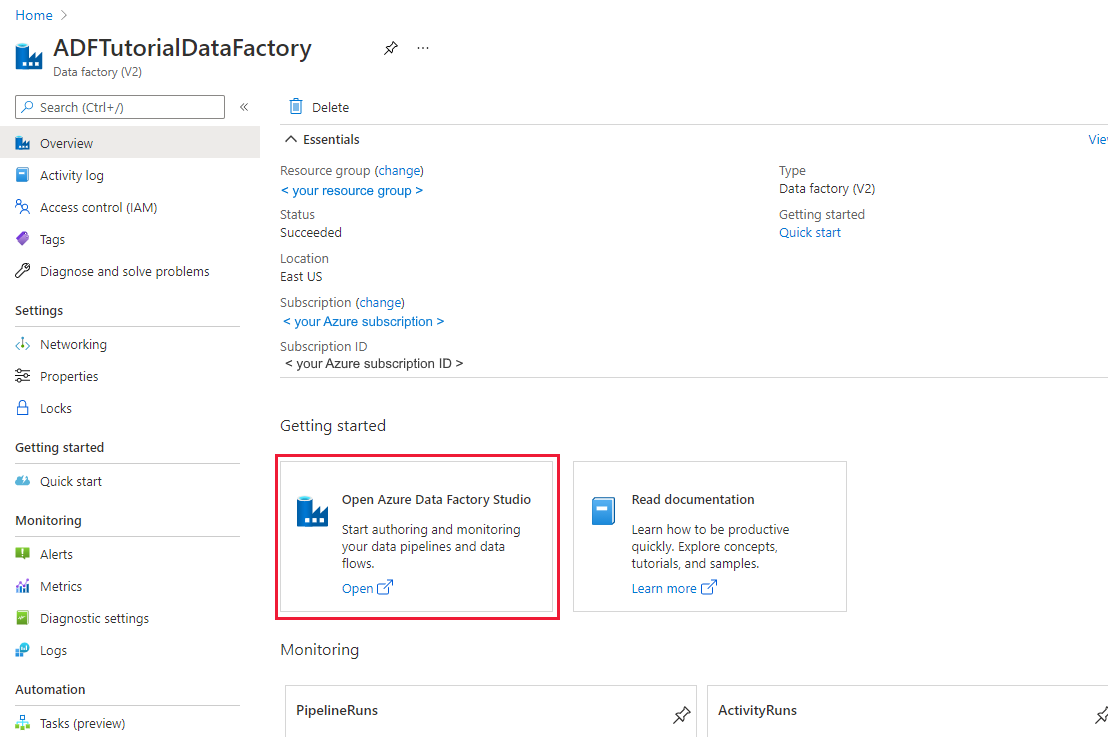
Seleccione Open (Abrir) en el icono Open Azure Data Factory Studio (Abrir Azure Data Factory Studio) para iniciar la aplicación de integración de datos en una pestaña independiente.
Carga de datos en Azure Data Lake Storage Gen2
En la página principal, seleccione el icono Ingest (Ingerir) para iniciar la herramienta de copia de datos.
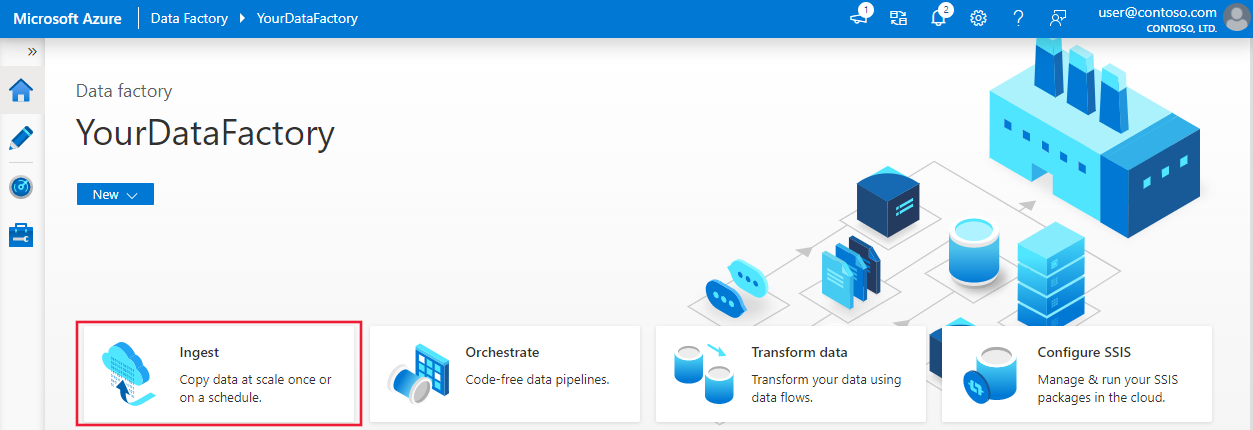
En la página Properties (Propiedades), elija Built-in copy task (Tarea de copia integrada) en Task type (Tipo de tarea) y elija Run once now (Ejecutar una vez ahora) en Task cadence or task schedule (Cadencia de tareas o programación de tareas). A continuación, seleccione Next (Siguiente).
En la página Source data store (Almacén de datos de origen), haga clic en + New connection (+ Nueva conexión).
Seleccione Azure Data Lake Storage Gen1 en la galería de conectores y seleccione Continuar.
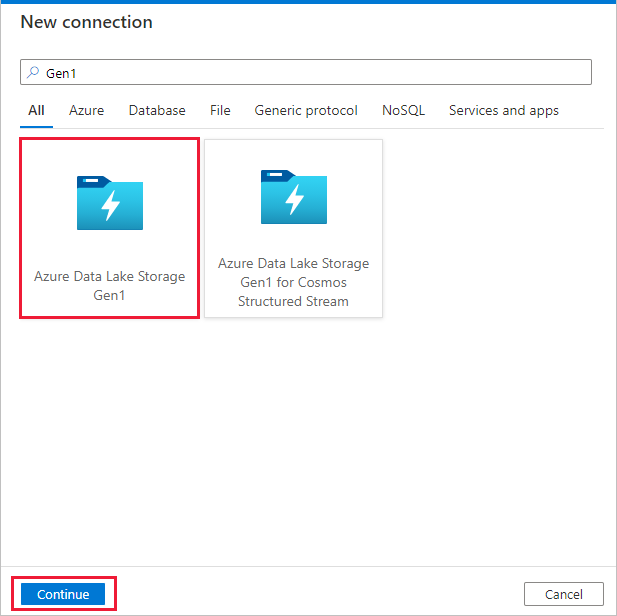
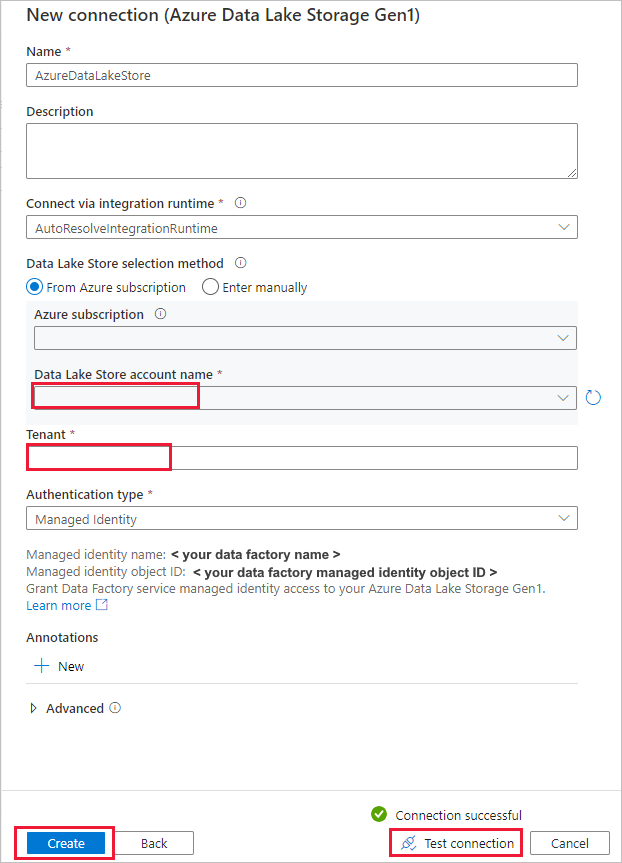
En la página New Connection (Azure Data Lake Storage Gen1) (Nueva conexión [Azure Data Lake Storage Gen1]), siga estos pasos:
- Seleccione su instancia de Data Lake Storage Gen1 para el nombre de cuenta y especifique o valide el inquilino.
- Seleccione Prueba de conexión para validar la configuración. Seleccione Crear.
Importante
En este tutorial se utilizará una identidad administrada para recursos de Azure con el fin de autenticar la cuenta de Azure Data Lake Storage Gen1. Para conceder a la identidad administrada los permisos adecuados en Azure Data Lake Storage Gen1, siga estas instrucciones.
En la página Source data store (Almacén de datos de origen), realice los pasos siguientes:
- Seleccione la conexión recién creada en la sección Connection (Conexión).
- En File or folder (Archivo o carpeta), vaya a la carpeta y el archivo que quiere copiar. Seleccione la carpeta o el archivo y, después, OK (Aceptar).
- Elija el comportamiento de copia; para ello, seleccione las opciones Recursively (De forma recursiva) y Binary copy (Copia binaria). Seleccione Siguiente.
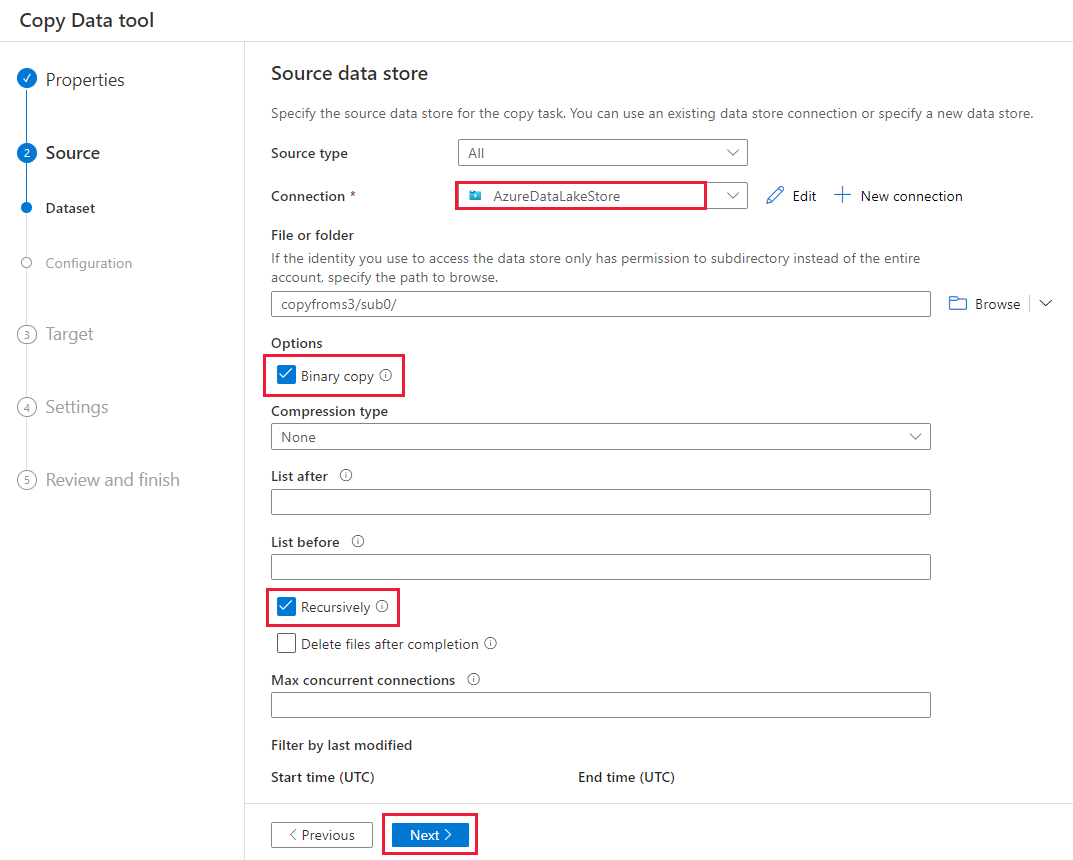
En la página Almacén de datos de destino, seleccione + Nueva conexión>Azure Data Lake Storage Gen2>Continuar.
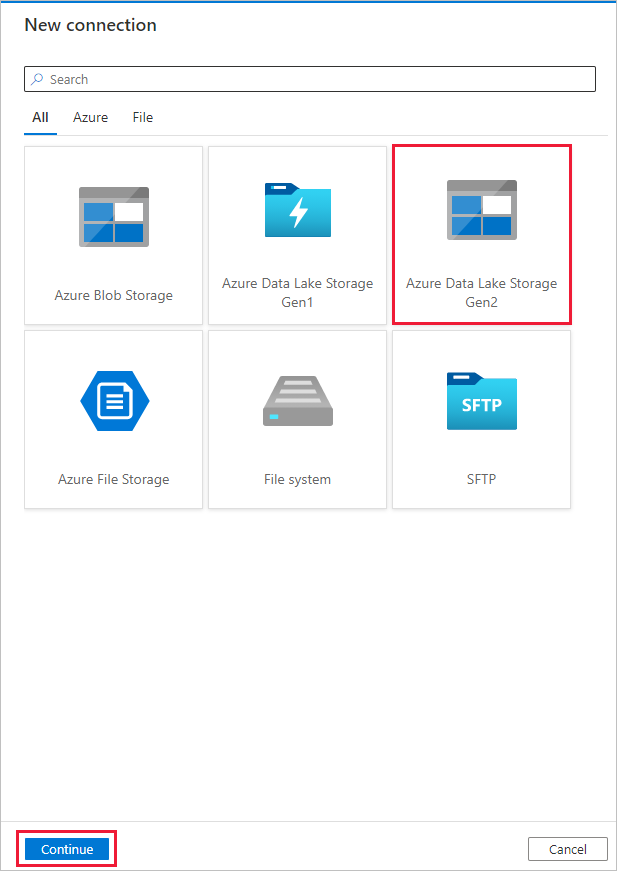
En la página New Connection (Azure Data Lake Storage Gen2) (Nueva conexión [Azure Data Lake Storage Gen2]), siga estos pasos:
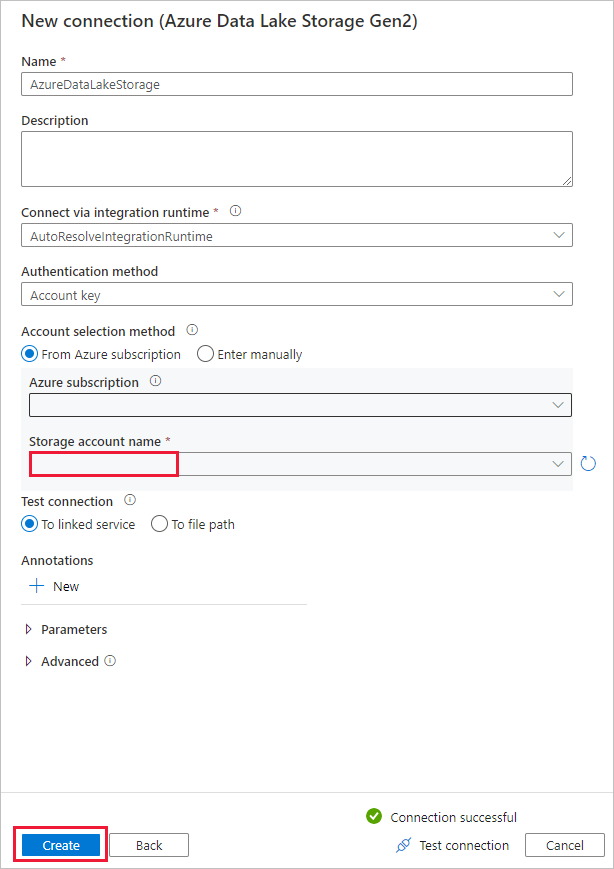
- Seleccione la cuenta habilitada para Data Lake Storage Gen2 en la lista desplegable Nombre de la cuenta de almacenamiento.
- Seleccione Create (Crear) para crear la conexión.
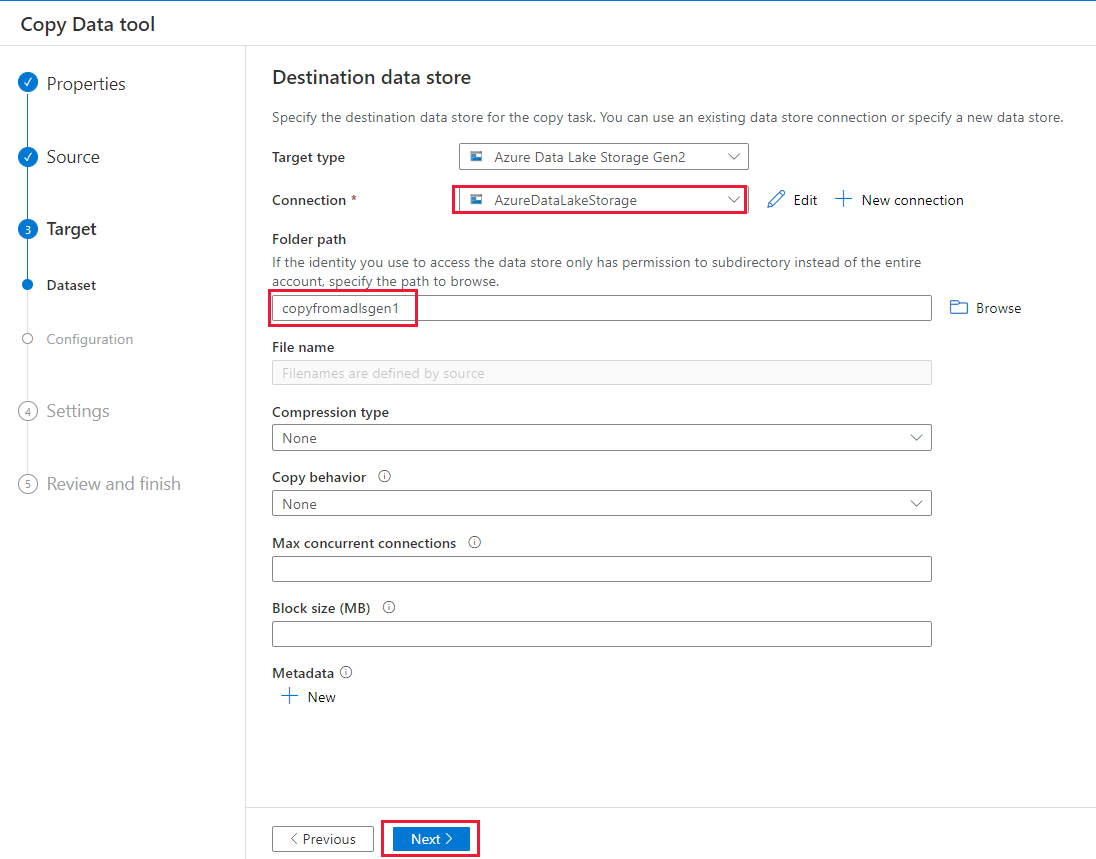
En la página Destination data store (Almacén de datos de destino), realice los pasos siguientes:
- Seleccione la conexión recién creada en el bloque Conexión.
- En la página Folder path (Ruta de la carpeta) escriba copyfromadlsgen1 como nombre de la carpeta de salida y seleccione Next (Siguiente). Si no existen el sistema de archivos de Azure Data Lake Storage Gen2 correspondiente y las subcarpetas, Data Factory los crea durante la copia.
En la página Settings (Configuración), especifique CopyFromADLSGen1ToGen2 en el campo Task name (Nombre de la tarea) y seleccione Next (Siguiente) para usar la configuración predeterminada.
En la página Resumen, revise la configuración y seleccione Siguiente.
En la página Deployment (Implementación), seleccione Monitor (Supervisión) para supervisar la canalización.
Observe que la pestaña Monitor (Supervisión) de la izquierda se selecciona automáticamente. La columna Pipeline name (Nombre de canalización) incluye los vínculos para ver los detalles de la ejecución de actividad y volver a ejecutar la canalización.
Para ver las ejecuciones de actividad asociadas a la ejecución de la canalización, seleccione el vínculo en la columna Pipeline name (Nombre de canalización). Como solo hay una actividad (actividad de copia) en la canalización, solo verá una entrada. Para volver a la vista de ejecuciones de canalización, seleccione el vínculo All pipeline runs (Todas las ejecuciones de la canalización) en el menú de la ruta de navegación en la parte superior. Seleccione Refresh (Actualizar) para actualizar la lista.
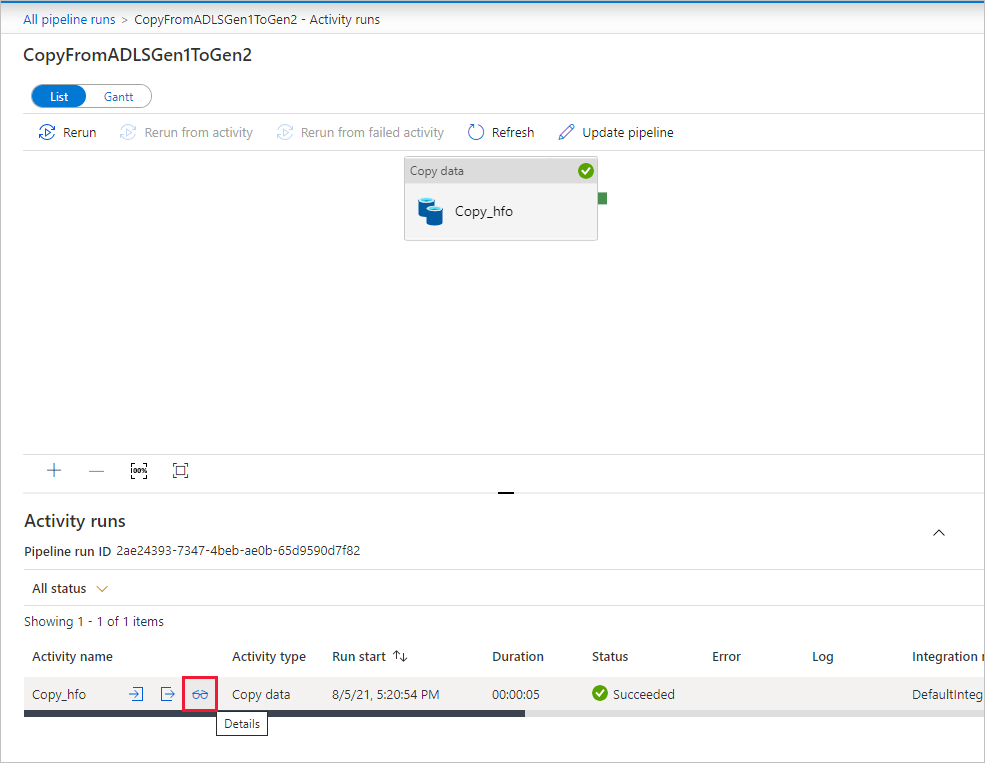
Para supervisar los detalles de la ejecución de cada actividad de copia, seleccione el vínculo con un icono de gafas Details (Detalles) en la columna Activity name (Nombre de actividad) en la vista de supervisión de la actividad. Puede supervisar detalles como el volumen de datos copiados desde el origen al receptor, el rendimiento de los datos, los pasos de ejecución con su duración correspondiente y las configuraciones que se utilizan.
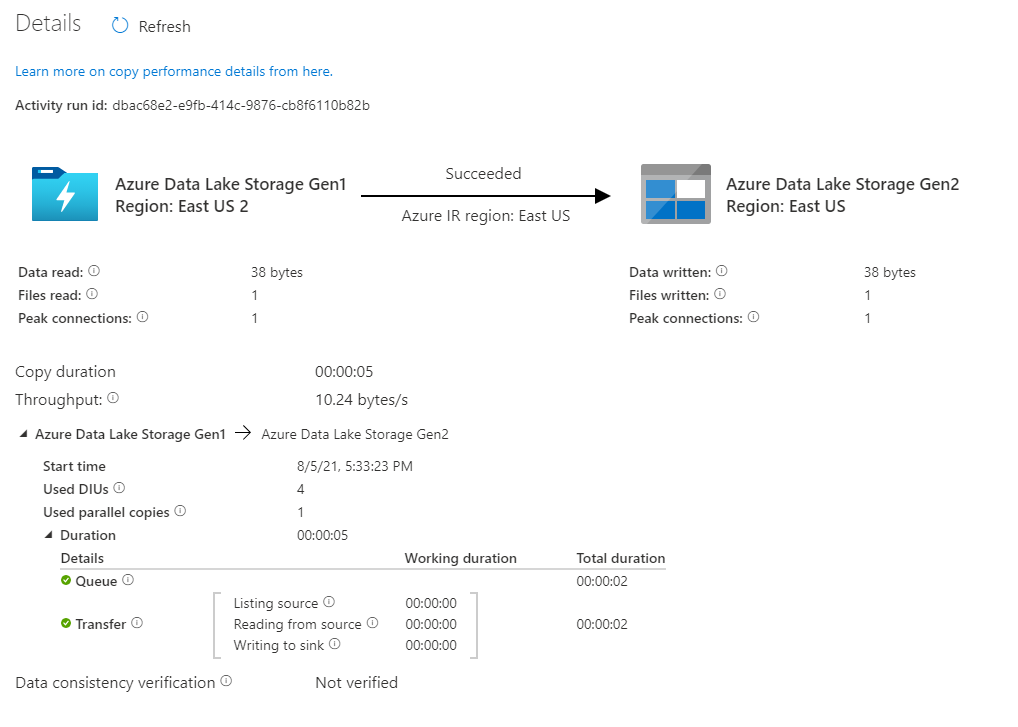
Verifique que los datos se copian en la cuenta de Azure Data Lake Storage Gen2.
Procedimientos recomendados
Para evaluar la actualización de Azure Data Lake Storage Gen1 a Azure Data Lake Storage Gen2 en general, vea Actualizar sus soluciones de análisis de macrodatos de Azure Data Lake Storage Gen1 a Azure Data Lake Storage Gen2. Las secciones siguientes presentan procedimientos recomendados para usar Data Factory para una actualización de datos de Data Lake Storage Gen1 a Data Lake Storage Gen2.
Migración de datos de instantánea inicial
Rendimiento
ADF ofrece una arquitectura sin servidor que permite paralelismo en diferentes niveles, lo que permite a los desarrolladores crear canalizaciones para aprovechar al máximo el ancho de banda de red, así como el ancho de banda y las IOPS de almacenamiento para maximizar el rendimiento del movimiento de datos para su entorno.
Nuestros clientes han migrado correctamente petabytes de datos, compuestos por cientos de millones de archivos, de Data Lake Storage Gen1 a Gen2, con un rendimiento sostenido de 2 Gbps y superior.
Puede lograr velocidades de movimiento de datos mayores aplicando diferentes niveles de paralelismo:
- Una única actividad de copia puede aprovechar recursos de proceso escalables: si usa Azure Integration Runtime, puede especificar hasta 256 unidades de integración de datos (DIU) para cada actividad de copia en modo sin servidor; si usa un entorno de ejecución de integración autohospedado, puede escalar verticalmente la máquina o escalar horizontalmente a varias máquinas (hasta 4 nodos) manualmente y una única actividad de copia creará particiones de su conjunto de archivos entre todos los nodos.
- Una única actividad de copia lee y escribe en el almacén de datos mediante varios subprocesos.
- El flujo de control de ADF puede iniciar varias actividades de copia en paralelo, por ejemplo, mediante un bucle ForEach.
Particiones de datos
Si el tamaño total de los datos en Data Lake Storage Gen1 es inferior a 10 TB y el número de archivos es menos de 1 millón, puede copiar todos los datos en una sola ejecución de actividad de copia. Si tiene una mayor cantidad de datos para copiar, o si quiere flexibilidad para administrar la migración de datos por lotes y hacer que cada uno de estos se complete en un periodo de tiempo determinado, particione los datos. La creación de particiones también reduce el riesgo de se produzca una incidencia inesperada.
Para hacer particiones de los archivos, se utiliza rango de nombres: listAfter/listBefore en la propiedad de la actividad de copia. Cada actividad de copia se puede configurar para copiar una partición a la vez, de modo que varias actividades de copia puedan copiar datos de una sola cuenta de Data Lake Storage Gen1 de forma simultánea.
Limitación de frecuencia
Como procedimiento recomendado, lleve a cabo una prueba de concepto de rendimiento con un conjunto de datos de ejemplo representativo, a fin de determinar el tamaño de partición adecuado.
Comience con una sola partición y una única actividad de copia con la configuración de DIU predeterminada. Se recomienda establecer siempre la opción de copia paralela en vacío (valor predeterminado) . Si considera que el rendimiento de copia no es lo suficientemente bueno, identifique y resuelva los cuellos de botella de rendimiento siguiendo los pasos de optimización del rendimiento.
Aumente gradualmente el valor de DIU hasta alcanzar el límite de ancho de banda de la red o el límite de ancho de banda/IOPS de los almacenes de datos, o hasta alcanzar el máximo de 256 DIU permitido en una única actividad de copia.
Si ha alcanzado el máximo rendimiento de una sola actividad de copia, pero aún no ha llegado a los límites superiores de rendimiento de su entorno, puede ejecutar varias actividades de copia en paralelo.
Si ve un número significativo de errores de limitación en la supervisión de la actividad de copia, significa que ha alcanzado el límite de capacidad de la cuenta de almacenamiento. ADF volverá a intentar automáticamente superar cada error de limitación para asegurarse de que no se perderá ningún dato, pero un número elevado de reintentos también puede disminuir el rendimiento de la copia. En tal caso, se recomienda reducir el número de actividades de copia que se ejecutan de forma simultánea para evitar que se produzcan muchos errores de limitación. Si ha estado usando una sola actividad de copia para copiar datos, se recomienda reducir la DIU.
Migración de datos diferencial
Puede usar varios métodos para cargar únicamente los archivos nuevos o actualizados desde Data Lake Storage Gen1:
- Cargar archivos nuevos o actualizados mediante una carpeta o nombres de archivo con particiones por hora. Un ejemplo es /2019/05/13/*.
- Cargar archivos nuevos o actualizados por LastModifiedDate. Si va a copiar grandes cantidades de archivos, realice primero particiones para evitar un bajo rendimiento de copia debido a que la actividad de copia única analiza toda la cuenta de Data Lake Storage Gen1 para identificar nuevos archivos.
- Identificar archivos nuevos o actualizados mediante cualquier herramienta o solución de terceros. Después, pasar el nombre de archivo o carpeta a la canalización de Data Factory a través de un parámetro, o una tabla o archivo.
La frecuencia adecuada para realizar una carga incremental depende del número total de archivos en Azure Data Lake Storage Gen1 y del volumen de archivos nuevos o actualizados que se van a cargar cada vez.
Seguridad de las redes
De forma predeterminada, ADF transfiere datos de Azure Data Lake Storage Gen1 a Gen2 mediante una conexión cifrada a través del protocolo HTTPS. HTTPS proporciona cifrado de datos en tránsito y evita la interceptación y ataques de tipo "Man in the middle".
Como alternativa, si no quiere que los datos se transfieran a través de la red pública de Internet, puede lograr una mayor seguridad si se transfieren a través de una red privada.
Conservación de las ACL
Si quiere replicar las ACL junto con los archivos de datos cuando se actualiza de Data Lake Storage Gen1 a Data Lake Storage Gen2, vea Conservar las ACL de Data Lake Storage Gen1.
Resistencia
Dentro de una ejecución de una única actividad de copia, ADF tiene un mecanismo de reintento integrado para que pueda controlar cierto nivel de errores transitorios en los almacenes de datos o en la red subyacente. Si migra más de 10 TB de datos, se recomienda crear particiones de ellos para reducir el riesgo de problemas inesperados.
También puede habilitar la tolerancia a errores en la actividad de copia para omitir los errores predefinidos. Además, puede habilitar la comprobación de coherencia de los datos en la actividad de copia para realizar una comprobación adicional y así garantizar que los datos no solo se copian correctamente del almacén de origen al de destino, sino también que son coherentes en ambos.
Permisos
En Data Factory, el conector de Data Lake Storage Gen1 admite la entidad de servicio y la identidad administrada para las autenticaciones de recursos de Azure. El conector de Data Lake Storage Gen2 admite la clave de cuenta, la entidad de servicio y la identidad administrada para las autenticaciones de recursos de Azure. Para hacer que Data Factory pueda navegar y copiar todos los archivos o listas de control de acceso (ACL) que necesitará, conceda los permisos suficientemente elevados para la cuenta para acceder a todos los archivos, leerlos o escribirlos y configurar las ACL si así lo desea. Debe conceder a la cuenta un rol de superusuario o propietario durante el período de migración y quitar los permisos elevados una vez completada la migración.